数据统计全靠它,python中的pandas!
在进行统计分析时,pandas提供了多种工具来帮助我们理解数据。
pandas提供了多个聚合函数,其中包括均值、标准差、最大值、最小值等等。
此外,pandas还可以进行基于列的统计分析,例如通过groupby()函数对数据进行聚合,并计算每组的统计分析结果。
除了基本的统计分析之外,pandas还可以进行更高级的分析,例如基于时间序列的分析等。
总之,pandas是一个非常强大的数据处理工具,可以帮助我们更轻松地进行数据分析和探索。
1. 一般统计
拿到数据之后,第一步我们会通过一些常用的统计信息来大体了解下数据的整体情况。
pandas中常用的统计函数有:
- .sum():计算对象的总和
- .mean():计算对象的平均值
- .median():计算对象的中位数
- .max():计算对象的最大值
- .min():计算对象的最小值
- .count():计算对象数量
- .std():计算对象标准差
- .var():计算对象方差
通过agg函数可以一次将所有的统计信息分析出来。
import pandas as pd
df = pd.DataFrame(
{
"数学": [100, 88, 94, 76, 84],
"语文": [98, 80, 86, 76, 90],
"英语": [95, 91, 86, 95, 83],
},
index=["小红", "小明", "小汪", "小李", "小张"],
)
df.agg(["sum", "mean", "median","max", "min", "count", "std", "var"])

2. 分组统计
如果要分析的数据集中不同的多个行存在同属于一个分类时,可以先分组之后再用上面的统计分析方法。
比如下面的示例,按年级分组统计的是同一个年级中所有学生的成绩情况,而按学生分组统计的则是该学生在各个年级阶段的成绩情况。
按年级分组统计:
(agg函数除了可以指定统计函数,还可以指定统计的列,下面的示例只统计了语文和数学情况)
df = pd.DataFrame(
{
"姓名": ["小红", "小明", "小红", "小明", "小汪", "小汪"],
"年级": ["初二", "初一", "初一", "初二", "初一", "初二"],
"数学": [100, 88, 94, 76, 84, 78],
"语文": [98, 80, 86, 76, 90, 88],
"英语": [95, 91, 86, 95, 83, 65],
},
)
agg_funcs = ["max", "min", "mean"]
df.groupby(by="年级").agg({"语文": agg_funcs, "数学": agg_funcs})

按学生分组统计:
df.groupby(by="姓名").agg({"语文": agg_funcs, "数学": agg_funcs})

3. 透视表
pandas透视表(Pivot Table)是数据分析中的一种非常强大的功能,可以实现数据的按列汇总、按行汇总、按列和行同时汇总、数据透视和数据分析等功能。
同样使用上一节中的示例数据,原始数据中,年级,姓名和分数混在一起,要看按人或者按年级查看成绩情况的时候,需要进行过滤和排序等操作。

如果使用透视表的话,可以将原始数据中的某些列的值作为新的索引,某些列的值作为新的列,那么数据会更加一目了然。
另外,透视表的结果用来绘制折线图,柱状图等也非常方便。
用年级作为索引,姓名作为列名的透视表:
df = pd.DataFrame(
{
"姓名": ["小红", "小明", "小红", "小明", "小汪", "小汪"],
"年级": ["初二", "初一", "初一", "初二", "初一", "初二"],
"数学": [100, 88, 94, 76, 84, 78],
"语文": [98, 80, 86, 76, 90, 88],
"英语": [95, 91, 86, 95, 83, 65],
},
)
pd.pivot_table(df, values=["数学", "语文", "英语"], index=["年级"], columns=["姓名"])
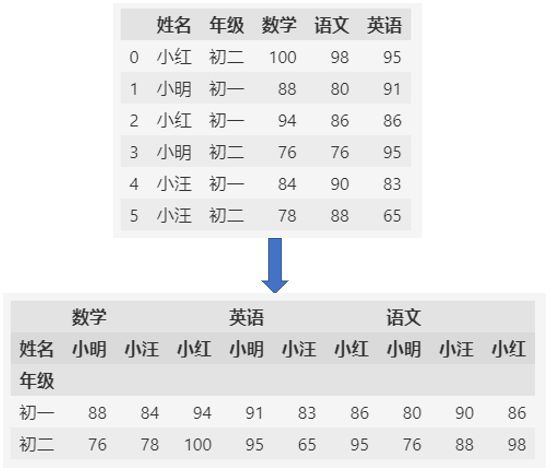
用姓名作为索引,年级作为列名的透视表:
pd.pivot_table(df, values=["数学", "语文", "英语"], index=["姓名"], columns=["年级"])

4. 同比和环比
同比和环比是统计中经常用到的概念,用来评估数据的变化情况。
同比一般指跟上一年度同一时期统计的数据的比较,环比一般指跟上一次统计的数据的比较。
原始数据如下(某同学初中三年每学期的平均分):
df = pd.DataFrame(
{
"年级": ["初一上", "初一下", "初二上", "初二下", "初三上", "初三下"],
"平均分": [90, 85, 86, 80, 90, 88],
},
)
df

环比就是看每个学期比上个学期是否进步:
df["平均分环比"] = df["平均分"].pct_change(periods=1)
df

第一条数据是NaN,因为它没有上一条数据可以参考。
pct_change 得出的数值就是同比增长的百分比,负数表示下降的百分比。
同比就是比较每个学年同学期的成绩变化,比如初二上和初一上比较,初三下和初二下比较等等。
df["平均分同比"] = df["平均分"].pct_change(periods=2)
df

我们观察这个示例数据,同比与环比的差别仅仅在于:同比是隔一个数据比较,而环比是相邻的数据比较。
所以,用pct_change来计算同比的时候,只要设置periods参数为2即可。
periods参数默认为1,所以其实计算环比的时候也可以不设置periods参数。
5. 总结回顾
本篇介绍的数据统计时常用的几种方法,其中分组统计和透视表是使用比较频繁的。
上面的示例主要介绍统计的函数,假造的数据非常简单,其实在数据统计时,统计前清理数据,排序数据等才是耗费时间最长的过程。
好了,今天的分享就到这里!如果你对Python感兴趣,想要学习pyhton,这里给大家分享一份Python全套学习资料,里面的内容都是适合零基础小白的笔记和资料,超多实战案例,不懂编程也能听懂、看懂。
需要的话可以微信扫描下方二维码免费获得。

一、Python所有方向的学习路线
Python所有方向路线就是把Python常用的技术点做整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。

二、Python学习软件
学习Python常用的开发软件都在这里了!每个都有详细的安装教程,保证你可以安装成功哦!

三、Python入门学习视频
还有很多适合0基础入门的学习视频,有了这些视频,轻轻松松上手Python~
四、Python实战案例
光学理论是没用的,要学会跟着一起敲代码,动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。100+实战案例源码等你来拿!

五、Python小游戏源码
如果觉得上面的实战案例有点枯燥,可以试试自己用Python编写小游戏,让你的学习过程中增添一点趣味!

六、副业兼职
而且学会Python以后,还可以在各大兼职平台接单赚钱,各种兼职渠道+兼职注意事项+如何和客户沟通,我都整理成文档了。

七、资料领取
由于篇幅有限,很多资料图片放不上来。需要的小伙伴可以微信扫描下方CSDN官方认证二维码领取(免费免费免费)