基于Python的招聘信息的大数据可视化分析系统
1. 项目背景
互联网时代,网络已经完完全全渗透到我们的生活当中,成为我们生活当中的一部分,其中很多求职、找工作也不例外,因此,很多招聘平台,例如像赶集网、58同城、英才网、智联招聘、前程无忧等求职网站如雨后春笋般的出现在市场上,为每一个求职者提供了便利,相对人才市场举办的线下招聘,其成本少、效率高、速度快等优点深受求职者们的青睐。由于企业招聘的特殊性,目前影响薪资的无非是地理位置、工作经验、学历、技术等,这些并非是呈传统性的线性变化。
本项目利用Python实现某一城市招聘相关信息的爬取,并对爬取的原始数据进行数据清洗,存储到数据库中,通过 Flask+echarts+Bootstrap+jquery搭建系统,分析各个区域所招聘企业的数量以及对学历、工作经验、工资等的数据分析。
招聘可视化系统录像
2. 招聘数据
招聘信息爬取流程为,先获取该市所有的在线招聘信息,以南昌市为例,通过构造循环,抓取所有分页下的招聘数据。
base_url = 'https://nanchang.xxxx.com/community/p{}/'
start = 1
end = 100
big_Region = "***" # 图片按照所在区
address = "***" # 图片按地址存储地址
quyu = "***"
small_Region = "***" # 大区域所包含小区域
count = 0
for i in range(start, end):
if i==1:
# 第2要修改的地方
url = "https://nanchang.xxxx.com/xxxx/" + quyu
else:
url="https://nanchang.xxxx.com/xxxx/" + quyu + "/" + "pg" + str(i)
link_req = requests.get(url, headers)
# print(req.status_code)
html = link_req.text
soup = BeautifulSoup(html, "lxml")
uls = soup.find('ul', class_="***Content***")通过lxml解析器对分析html页面的Dom结构,利用 Bootstrap 进行解析,获取招聘信息的详细字段信息。
同理,获取招聘下所有在招聘信息:
3. 招聘据清洗与存储
抓取的原始数据可能存在数据异常、缺失等情况,需要进行数据清洗和数据类型转换等预处理操作。清洗后的数据存储到sqlite数据库中。
# 获取excel里面的数据集
def get_bossLast(dpath):
datalist = []
df = pd.read_csv(dpath, encoding="gbk")
df = df[["职位","公司名","城市","地区","商业区","工作经验","教育水平","公司行业","规模人数","技能","福利","最低薪资","最高薪资","薪资年薪","平均工资"]]
datalist = df.values.tolist()
return datalist# 4.保存数据到sqlite3中
def saveDataDB(datalist, dbpath):
init_db(dbpath)
conn = sqlite3.connect(dbpath)
cur = conn.cursor()
for data in datalist:
for index in range(len(data)):
data[index] = '"' + *** + '"'
sql = '''
insert into ***
print(sql)
4. 招聘可视化分析系统
系统采用 flask 搭建 web 后台,利用 pandas、numpy等工具包实现对当前招聘企业的数量、学历、工作经验、工资等进行统计分析,并利用 bootstrap + echarts +bootstraps + Jquery进行前端渲染可视化。
4.1 区域数据分析

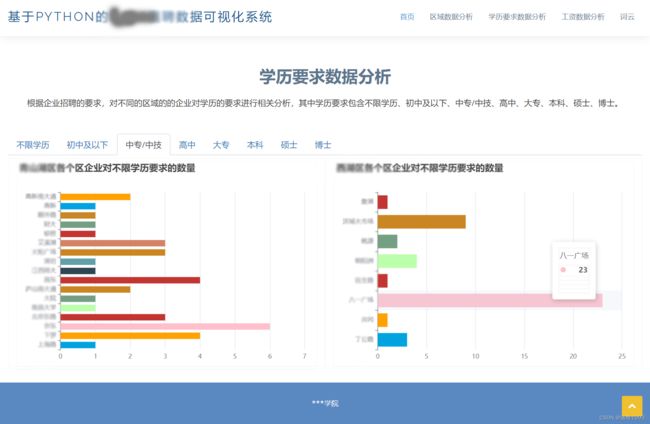
4.2 学历要求数据分析


4.3 工资数据分析
4.4 招聘福利假期行业等的词云分析
5. 总结
本项目利用Python实现某城市招聘相关信息的爬取,并对爬取的原始数据进行数据清洗,存储到数据库中,通过 flask 搭建后台,分析影响工资的各类因素,最终呈现出相关的数据分析可是画图。
注:由于是第一次写,很多不足,请多指教。