SQL系列(二)最常见的业务实战
SQL系列(二)最常见的业务实战
本文将通过构建三张表,几个SQL实例带大家掌握最常见的业务需求,同时这些实例也覆盖了面试中80%的考点。
临时表概览
temp.hh_user_active:用户活跃信息表,存储了2021年每日活跃的用户ID。dt+uid为唯一值。
| col_name | data_type | comment | sample |
|---|---|---|---|
| dt | string | 活跃日期 | 2021-01-01 |
| uid | string | 用户ID | 91 |
temp.hh_user_exercise:用户练习信息表,存储了2021年每日练习的用户数据。id为唯一值。
| col_name | data_type | comment | sample |
|---|---|---|---|
| dt | string | 练习日期 | 2021-01-01 |
| uid | string | 用户ID | 77 |
| id | string | 练习ID | 1 |
| paperid | string | 试卷ID | 45 |
temp.hh_paper:试卷表,存储了所有的试卷内容。id为唯一值。
| col_name | data_type | comment | sample |
|---|---|---|---|
| id | string | 试卷ID | 60 |
| paper_info | string | 试卷信息 | [{"questionids": "51,93,79,12,83,88,95,94,60,75,33,9,63,11,65,98,28,35,25,80", "course": "语文", "content": " |

以上数据来源于python构造的,如果有需要的同学可关注公众号HsuHeinrich,回复【SQL02】自动获取~
常见的业务SQL实例
汇总统计
-
计算每个用户的活跃天数、练习次数、在12月的活跃天数。并筛选出活跃天数高于60天的用户,降序选择100个样本。
知识点:汇总、去重汇总、有条件去重汇总以及一些基础语法(表关联、having等)
select
ua.uid
,count(distinct ua.dt) as active_days -- 活跃天数
,count(exerciseid) as exercise_cnt -- 练习次数
,count(distinct if(trunc(ua.dt,'MM')='2021-12-01',ua.dt,null)) as active_days_in_12m -- 12月活跃天数
from
(-- 用户活跃信息
select
dt
,uid
from
temp.hh_user_active
where
dt between '2021-01-01' and '2021-12-31'
)ua
left join
(-- 用户练习信息
select
dt
,uid
,id as exerciseid
,paperid
from
temp.hh_user_exercise
where
dt between '2021-01-01' and '2021-12-31'
)ue on ua.dt=ue.dt and ua.uid=ue.uid
group by
ua.uid
having
active_days >= 60
order by
active_days desc
limit 100
-
查看用户活跃天数的分布
知识点:嵌套子查询
select
active_days
,count(uid) as user_nums -- 用户数
from
(-- 用户活跃信息
select
uid
,count(dt) as active_days
from
temp.hh_user_active
where
dt between '2021-01-01' and '2021-12-31'
group by
uid
)ua
group by
active_days
窗口函数的应用
-
计算每日练习次数、练习新用户数(以前未做过练习,今日开始做练习算作今日的练习新用户)、累积练习次数(每月单独汇总)、累积占比(每月单独汇总)
-
每日练习次数排名前三的试卷ID
知识点:三大窗口函数的应用、窗口函数在明细与汇总中的应用
select
ex.dt
,exercise_cnt
,exercise_new_user_nums
,cume_exercisee_cnt
,cume_rate
,paperid_list
from
(-- 每日练习数据
select -- 窗口函数用于汇总
dt
,sum(1) as exercise_cnt -- 练习次数
,count(distinct if(first_exercise_date=dt,uid,null)) as exercise_new_user_nums -- 练习新用户数
,sum(sum(1)) over(partition by trunc(dt, 'MM') order by dt) as cume_exercisee_cnt -- 累积练习次数
,sum(sum(1)) over(partition by trunc(dt, 'MM')) as toatl_exercisee_cnt -- 总练习次数
,sum(sum(1)) over(partition by trunc(dt, 'MM') order by dt)
/ sum(sum(1)) over(partition by trunc(dt, 'MM')) as cume_rate -- 累积百分比
from
(-- 窗口函数用于明细
select
uid
,dt
,id
,first_value(dt) over(partition by uid order by dt) as first_exercise_date -- 首次练习日期
,paperid
from
temp.hh_user_exercise
where
dt between '2021-01-01' and '2021-12-31'
)a
group by
dt
)ex
left join
(-- 每日练习最多的试卷信息
select
dt
,collect_list(paperid) as paperid_list
from
(
select
dt
,paperid
,count(1) as cnt
,row_number() over(partition by dt order by count(1) desc) as rn -- 每日练习次数排名
from
temp.hh_user_exercise
where
dt between '2021-01-01' and '2021-12-31'
group by
dt
,paperid
)a
where
rn<=3
group by
dt
)exp on ex.dt=exp.dt
正则、json、列传多行
在开始本实例之前,先普及下正则和json的相关知识
正则表达式具备强大的字符串模糊匹配能力,hive可以使用
rlike、regexp、regexp_replace、regexp_extract进行正则匹配,日常业务中的Hive只需要掌握简单的正则基础知识即可。
| 元素 | 含义 | 示例 |
|---|---|---|
| . | 代表除换行字符之外的任何字符 | fo.与foo、for等匹配 |
| * | 匹配零个或多个 | fo*与f、fo、foo等匹配 |
| + | 匹配一个或多个 | fo+与fo、foo等匹配 |
| ? | 匹配零个或一个 | fo?r与fr、for匹配 |
| ( ) | 圆括号中内容为一个实体 | f(or)+d与ford、forord等匹配 |
| [] | 匹配方括号中任意字符 | f[abc]r与far、fbr等匹配 f[abc]+r与faar、facr等匹配 |
| [^] | 匹配除方括号中任意字符 | f[^abc]r与for等匹配 |
| {m} {m,n} {m,} |
匹配m次、至少m之多n次、至少m次 | fo{2,}r与foor、fooor等匹配 |
| \d | 任何数字,同[0-9] | \d与1、13等匹配 |
| \D | 任何非数字,同[^0-9] |
\D与a、abc等匹配 |
| \w | 任何字母数字,同[_A-Za-z0-9] | \w与a、a1等匹配 |
| \W | 任何非字母数字,同[^_A-Za-z0-9] |
\W与!、&等匹配 |
| \s | 任意空白字符,包括空格、换行字符、制表符、非换行空格等 | for\s与for you等匹配 |
| \S | 任意非空白字符 | for\S与forever等匹配 |
| ^ | 表示一个字符串的开头 | ^(start)与start 123匹配 |
| $ | 表示一个字符串的结尾 | ^(end)与123 end匹配 |
| \ | 对关键字进行转义,也包括\本身 |
|
| \t | 匹配制表符 | |
| \n | 匹配换行符 | |
| \r | 匹配回车符 | |
| | | 匹配多种情况 | a(b|c|d)m与abm、acm等匹配 |
| *? | 懒惰模式-匹配零个或多个,尽可能少的匹配 | a.*?b在ammbbb匹配为ammb |
| +? | 懒惰模式-匹配一个或多个,尽可能少的匹配 | |
| ?? | 懒惰模式-匹配零个或一个,尽可能少的匹配 | |
| {n,m}? {n,}? |
懒惰模式-至少m之多n次、至少m次,尽可能少的匹配 |
在hive中正则提取时,无法进行全局提取,即只能提取第一个与之匹配的子串。但是可以利用
regexp_replace(str,pattern, '$1')剔除规则外字符(除尾部),再进行尾部之前的规则提取即可。
json的字符串常常以
[{key,value}]或者{key,value}的形式。因此在提取json汇总的value时,常常以get_json_object(strin,'$[*].key')提取外层含有[]的json串,以get_json_object(strin,'$.key')提取外层无[]的json串。
列传多行常常会用到
lateral view explode (split(ids,',')) t as id,其实际可理解为explode后的表t(该表只有一个字段)与原始表进行笛卡尔积。
-
提取所有的题目ID,以及对应的试卷,科目,图片信息
知识点:正则、json提取、列转多行
select
questionid
,id as paperid
,course
,regexp_replace(content, '.*? )', '$1') as content1 -- 类似全局提取(但尾部规则外字符无法替换)
,regexp_extract(regexp_replace(content, '.*?)', '$1'), '.*(jpg>|jpeg>|png>)', 0) as content2 -- 剔除尾部规则外字符
,regexp_replace(regexp_extract(regexp_replace(content, '.*?)', '$1'), '.*(jpg>|jpeg>|png>)', 0),'>',',') as imgs -- 分隔符替换为逗号
from
(
select
id
,get_json_object(paper_info,'$[*].questionids') as questionids -- json提取questionids
,get_json_object(paper_info,'$[*].course') as course
,get_json_object(paper_info,'$[*].content') as content
from
temp.hh_paper
)a
lateral view explode (split(questionids,',')) t as questionid -- 列转多行
)', '$1') as content1 -- 类似全局提取(但尾部规则外字符无法替换)
,regexp_extract(regexp_replace(content, '.*?)', '$1'), '.*(jpg>|jpeg>|png>)', 0) as content2 -- 剔除尾部规则外字符
,regexp_replace(regexp_extract(regexp_replace(content, '.*?)', '$1'), '.*(jpg>|jpeg>|png>)', 0),'>',',') as imgs -- 分隔符替换为逗号
from
(
select
id
,get_json_object(paper_info,'$[*].questionids') as questionids -- json提取questionids
,get_json_object(paper_info,'$[*].course') as course
,get_json_object(paper_info,'$[*].content') as content
from
temp.hh_paper
)a
lateral view explode (split(questionids,',')) t as questionid -- 列转多行
多维度聚合
-
统计每日各科目的练习次数,要求可以单独按照日期或者科目维度查看各自的练习次数。
知识点:group 强化
select
coalesce(exercise_dt,'all') as exercise_dt
,coalesce(course,'all') as course
,count(distinct exerciseid) as exercise_cnt
from
(
select
ua.uid
,coalesce(ue.dt,'未知') as exercise_dt -- 注意多维度聚合时,聚合的维度不应有null
,coalesce(p.course,'未知') as course
,exerciseid
from
(-- 用户活跃信息
select
dt
,uid
from
temp.hh_user_active
where
dt between '2021-01-01' and '2021-12-31'
)ua
join
(-- 用户练习信息
select
dt
,uid
,id as exerciseid
,paperid
from
temp.hh_user_exercise
where
dt between '2021-01-01' and '2021-12-31'
)ue on ua.dt=ue.dt and ua.uid=ue.uid
left join
(
select
id as paperid
,get_json_object(paper_info,'$[*].course') as course
from
temp.hh_paper
)p on ue.paperid=p.paperid
)a
group by
exercise_dt
,course
with cube
日期计算
-
生成自2000-01-01后每一天的日期信息,包含但不限于年、月、日、月初、月末等
知识点:各类日期函数的应用
select
dt
,from_unixtime(unix_timestamp(dt,'yyyy-MM-dd'),'yyyyMMdd') as dt2 -- 日期格式转换
,date_format(dt, 'yyyyMMdd') as dt3 -- 日期格式转换
,year(dt) as dt_year -- 年
,quarter(dt) as dt_quarter -- 季度
,month(dt) as dt_month -- 月
,day(dt) as dt_day -- 日
,year(date_sub(next_day(dt,'monday'),4))*100+weekofyear(dt) as year_week -- 年周
,trunc(dt,'YY') as year_first_day -- 年初
,date_add(add_months(trunc(dt,'YY'),12),-1) as year_last_day -- 年末
,datediff(dt,trunc(dt,'YY'))+1 as day_of_year -- 年的n日
,trunc(dt,'Q') as quarter_first_day -- 季度初
,date_add(add_months(trunc(dt,'Q'),3),-1) as quarter_last_day -- 季度末
,trunc(dt,'MM') as month_first_day -- 月初
,last_day(dt) as month_last_day -- 月末
,if(pmod(datediff(dt,'1990-01-01')+1,7)=0,7,pmod(datediff(dt,'1990-01-01')+1,7)) as week_day -- 周几 -- 19900101为周一
,date_add(next_day(dt,'MO'),-7) as week_first_day -- 周初
,date_add(next_day(dt,'MO'),-1) as week_last_day -- 周末
,if(ceil(day(dt)/10)>3,3,ceil(day(dt)/10)) as xun -- 旬
from
(-- 构造自然日
select
date_add(begain_date,rn-1) as dt
from
(
select
'2000-01-01' as begain_date
,row_number() over(order by rand()) as rn
from
temp.hh_user_active
)a
where
rn-1<10000
)a
留存
- 计算每日活跃用户数、次日留存用户数、7日留存用户数、7日内留存用户数
select
a.dt
,count(distinct a.uid) as uv
,count(distinct if(re.dt=date_add(a.dt,1),a.uid,null)) as retention_1d -- 次日留存
,count(distinct if(re.dt=date_add(a.dt,7),a.uid,null)) as retention_7d -- 7日留存
,count(distinct if(re.dt between date_add(a.dt,1) and date_add(a.dt,7),a.uid,null)) as retention_in_7d -- 7日内留存
from
(
select
dt
,uid
from
temp.hh_user_active
where
dt between '2021-01-01' and '2021-12-31'
)a
left join
(
select
dt
,uid
from
temp.hh_user_active
where
dt between '2021-01-01' and '2021-12-31'
)re on a.uid=re.uid and re.dt>=a.dt
group by
a.dt
cohort
- cohort也叫同期群分析,常用于观察同一时间段的新用户在未来一段时间的表现。根据用户活跃信息表计算出每月新用户的留存cohort
select
dt_min
,max(if(date_diff=0,uv,0)) as d0
,max(if(date_diff=1,uv,0)) as d1
,max(if(date_diff=2,uv,0)) as d2
,max(if(date_diff=3,uv,0)) as d3
,max(if(date_diff=4,uv,0)) as d4
,max(if(date_diff=5,uv,0)) as d5
,max(if(date_diff=6,uv,0)) as d6
,max(if(date_diff=7,uv,0)) as d7
,max(if(date_diff=8,uv,0)) as d8
,max(if(date_diff=9,uv,0)) as d9
,max(if(date_diff=10,uv,0)) as d10
,max(if(date_diff=11,uv,0)) as d11
,max(if(date_diff=12,uv,0)) as d12
,max(if(date_diff=13,uv,0)) as d13
,max(if(date_diff=14,uv,0)) as d14
,max(if(date_diff=15,uv,0)) as d15
,max(if(date_diff>15,uv,0)) as `d15+`
from
(-- 构造同期群+日期差数据宽表 可直接excel透视或pandas转化为宽表
select
dt_min
,date_diff
,count(uid) as uv
from
(
select
dt
,uid
,first_value(dt) over(partition by uid order by dt) as dt_min -- 同期群分组 -- 首次活跃日期
,datediff(dt,first_value(dt) over(partition by uid order by dt)) as date_diff -- 活跃日期差
from
(-- 用户每日数据
select
dt
,uid
from
temp.hh_user_active
where
dt between '2021-01-01' and '2021-12-31'
)a
)a
group by
dt_min
,date_diff
)a
group by
dt_min
连续登陆问题
连续登陆是一类窗口函数应用的典型问题,如求连续登陆、连续消费等。常见的方法有三种:row_number、lag/lead、sum(if[exp])。其核心是按照日期排序,将连续的日期等换成同一分组。
- 计算每个用户最大连续登陆天数和最大沉睡天数
select
uid
,max(continue_nums) as max_continue_nums
,max(max_sleep_nums) as max_sleep_nums
from
(
select
uid
,continue_flag
,count(1) as continue_nums -- 连续登录天数
,max(sleep_nums) as max_sleep_nums -- 最大沉睡天数
from
(
select
uid
,date_diff
,rn
,date_diff - rn as continue_flag -- 连续登陆差值相同
,coalesce(date_diff - lag_date_diff - 1,0) as sleep_nums -- 以date_diff作为日期的数值替换,相当于dt-lag(dt)
from
(
select
uid
,date_diff
,row_number() over(partition by uid order by date_diff) as rn -- 排序
,lag(date_diff) over(partition by uid order by date_diff) as lag_date_diff -- 上次活跃
from
(
select
dt
,uid
,datediff(dt,'2000-01-01') as date_diff -- 构造与指定日期差(后续操作作为日期的等价数值)
from
(-- 用户每日数据
select
dt
,uid
from
temp.hh_user_active
where
dt between '2021-01-01' and '2021-12-31'
)a
)a
)a
)a
group by
uid
,continue_flag
)a
group by
uid
-
计算连续5日都在练习新试卷的用户数
只需在1的基础上构造出每日练习新试卷用户数据即可
-- 优化1的逻辑,减少嵌套
select
count(distinct if(max_continue_nums>=5,uid,null)) as user_nums -- 连续5天做新试卷的用户数
from
(
select
uid
,continue_flag
,count(1) as continue_nums -- 连续登录天数
,max(count(1)) over(partition by uid) as max_continue_nums -- 最大连续登陆天数
from
(
select
dt
,uid
,datediff(dt,'2000-01-01') as date_diff -- 构造与指定日期差
,row_number() over(partition by uid order by datediff(dt,'2000-01-01')) as rn -- 排序
,datediff(dt,'2000-01-01')
- row_number() over(partition by uid order by datediff(dt,'2000-01-01')) as continue_flag -- 连续登陆差值相同
from
(-- 构造每日练习新试卷用户数据
select
dt
,uid
,count(if(paper_first_date=dt,1,null)) as new_paper_exercise_cnt
from
(
select
dt
,uid
,id as exerciseid
,paperid
,first_value(dt) over(partition by uid,paperid order by dt) as paper_first_date -- 每用户试卷首次练习日期
from
temp.hh_user_exercise
where
dt between '2021-01-01' and '2021-12-31'
)a
group by
dt
,uid
having
new_paper_exercise_cnt>0
)a
)a
group by
uid
,continue_flag
)a
-
如果用户从dateX开始,连续7日活跃,则返回dateX所在行的信息,一个用户可以有多条符合条件的记录。
知识点:其实lag/lead窗口函数也适用于连续登陆问题,且在指定的连续长度时逻辑更为简洁。
select
uid
,dt
from
(
select
uid
,dt
,lead(dt,6) over(partition by uid order by dt) as lead_dt_7d
,if(datediff(lead(dt,6) over(partition by uid order by dt), dt)=6,1,0) as if_continue
from
temp.hh_user_active
where
dt between '2021-01-01' and '2021-12-31'
)a
where
if_continue=1
-
计算用户最大连续登陆天数,且规定如果间隔一天也算连续。即1,2,4算作连续4天;1,2,5算作连续两天。
知识点:通过sum(if[exp])的窗口函数计算累积值,可以构造出连续分组,对于连续的定义更为灵活。
select
uid
,max(continue_nums) as max_continue_nums -- 最大连续登陆天数
from
(
select
uid
,group_id
,datediff(max(dt),min(dt))+1 as continue_nums -- 连续天数
from
(
select
uid
,dt
,dt_lag
,lag_diff
,sum(if(lag_diff>2,1,0)) over(partition by uid order by dt) as group_id -- 当日期差大于2天,则另起一组(因为0的累积值不变)
from
(
select
uid
,dt
,lag(dt,1) over(partition by uid order by dt) as dt_lag -- 日期滞后一天
,datediff(dt,lag(dt,1) over(partition by uid order by dt)) as lag_diff -- 与上个日期的差值
from
temp.hh_user_active
where
dt between '2021-01-01' and '2021-12-31'
)a
)a
group by
uid
,group_id
)a
group by
uid
建议
通过上述SQL实战,相信大家已经能够顺利地写出大多数业务需求了。不过有些约定俗成的建议给到各位:
良好的代码风格
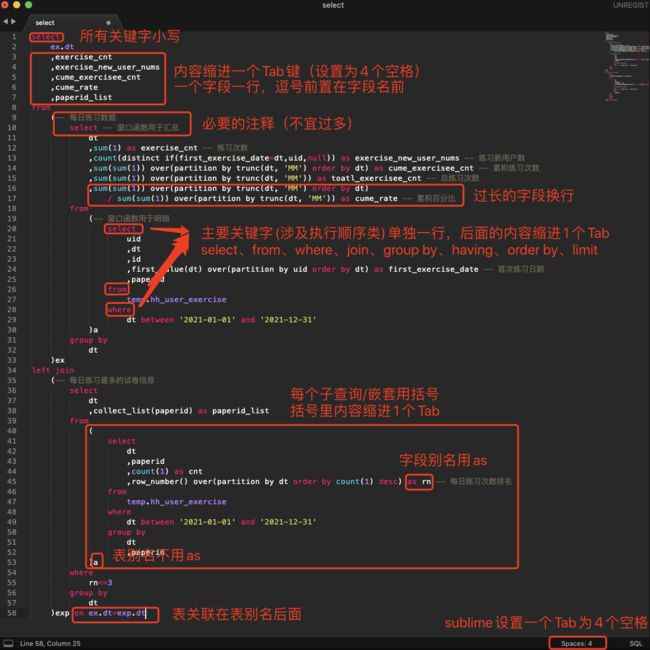
SQL是一个非严格的格式化要求语言,因此一个优秀的数据分析师应该养成自己良好的代码风格。如果没有的话,可以参考笔者的SQL代码风格。笔者的代码风格也继承于入门的师傅,核心在于关键字小写、缩进美化、必要的注释。详见下图:
理解执行顺序
理解SQL的执行顺序有助于提高代码的正确率,避免进入逻辑误区。SQL执行的内部机制为:from->on->join->where->group by->count->having->select->union all->order by->limit。
主表思维
简单翻译一下就是不要使用right join。日常业务需求的经验沉淀告诉我们,每个需求都需要明确主要信息,附加信息以left join的形式增加到主表,构造一张大明细表(明细表中含维度和度量,维度在前,度量在后),在此基础上按所需维度向上汇总。
精简子查询
从上面的例子也能发现,Hive与MySQL在语法习惯上有不同。MySQL习惯于先关联再整体上筛选条件和字段,但在Hive中,习惯构造好一个个的子查询,然后再关联。这就要求对子查询尽量做到精简,能过滤的先过滤,能汇总的先汇总。
逻辑关联
简单翻译下就是尽量避免多对多关联。多对多容易造成逻辑理解混乱、数据重复等问题,也提升了数据校验的难度。不仅在局部上如此要求,在整体上也是如此,因为SQL的关联是按顺序从上到下的,因此如果前置的表在进行一对多或者多对一操作后,再与下表关联就容易出现多对多的情况。
总结
其实SQL是最考验分析师的逻辑能力的,火候够不够就看逻辑够不够清晰。有人可能就问了,那怎么知道自己逻辑够不够清晰呢?简单的一句话:当你知道如何最正确的使用count()和count(distinct)时,你的逻辑就是清晰的。
最后,给大伙出道简单的综合题吧:给定起始值和结束值(均为整数),构造步长为1的等差数组。如:
| start | end | result |
|---|---|---|
| 2 | 5 | [2,3,4,5] |
| 11 | 9 | [11,10,9] |
新的一年,祝大家升职加薪,到点下班不是梦~
共勉~