中文Word2Vec训练
中文的词向量训练和英文的差不多,输入数据的格式都一样,均需要可迭代的句子列表。但有一点需要注意的是,在英文句子里,单词之间自然地就很清楚哪个是哪个单词了,而中文句子则不然,计算机需要知道哪个部分称之为一个“词”。
所以,中文词向量的训练关键在于分词的处理。通常使用jieba分词工具库来对语料库进行处理。下面来看一些简单例子:
import os
# jieba分词库
import jieba
import jieba.analyse
# gensim词向量训练库
from gensim.test.utils import common_texts, get_tmpfile
from gensim.models import Word2Vec
from gensim.models import word2vec《倚天屠龙记》小说训练:
with open('./倚天屠龙记.txt', encoding='utf-8') as f1:
document = f1.read() # 一行一行地读取小说文本的句子
document_cut = jieba.cut(document, cut_all=False) # 分词
result = ' '.join(document_cut).replace(',', '').replace('。', '').replace('?', '').replace('!', '') \
.replace('“', '').replace('”', '').replace(':', '').replace(';', '').replace('…', '').replace('(', '').replace(')', '') \
.replace('—', '').replace('《', '').replace('》', '').replace('、', '').replace('‘', '') \
.replace('’', '') # 词与词之间用空格隔开并去掉标点符号
with open('./倚天屠龙记_segment.txt', 'w', encoding="utf-8") as f2:
f2.write(result) # 得到分词之后的文本语料库#加载语料
sentences = word2vec.LineSentence('./倚天屠龙记_segment.txt')#创建临时文件
path = get_tmpfile("word2vec_1.model") #训练语料
model_1 = word2vec.Word2Vec(sentences, sg=1, vector_size=100, negative=3, sample=0.001, hs=1, window=5, min_count=1, workers=4)这里说一下相关参数:
1. sentences:预处理后的训练语料库。是可迭代列表,但是对于较大的语料库,可以考虑直接从磁盘/网络传输句子的迭代。
2. sg:skip-gram算法,对低频词敏感;默认sg=0为CBOW算法。
3. vector_size(int) :是输出词向量的维数,默认值是100。这个维度的取值与我们的语料的大小相关,比如小于100M的文本语料,则使用默认值一般就可以了。如果是超大的语料,建议增大维度。值太小会导致词映射因为冲突而影响结果,值太大则会耗内存并使算法计算变慢,一般值取为100到200之间,不过见的比较多的也有300维的。
4. window(int):是一个句子中当前单词和预测单词之间的最大距离,window越大,则和某一词较远的词也会产生上下文关系。默认值为5。window越大所需要枚举的预测此越多,计算的时间越长。
5. min_count:忽略所有频率低于此值的单词。默认值为5。
6. workers:表示训练词向量时使用的线程数,默认是当前运行机器的处理器核数。
还有关采样和学习率的,一般不常设置:
1. negative和sample可根据训练结果进行微调,sample表示更高频率的词被随机下采样到所设置的阈值,默认值为1e-3。
2. hs=1表示分层softmax将会被使用,默认hs=0且negative不为0,则负采样将会被选择使用。
# 输出和“张三丰”最相似的前10个词和相似度度量
for key in model_1.wv.similar_by_word('张三丰', topn=10):
print(key)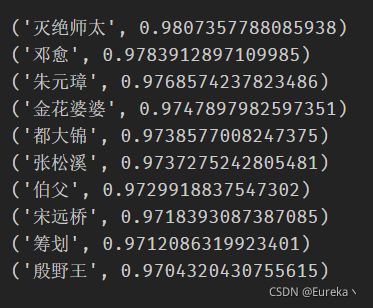
# 任意查看两个词之间的相似度大小
model_1.wv.similarity('周芷若', '赵敏')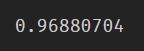
THUCNews数据集训练:
THUCNews是根据新浪新闻RSS订阅频道2005~2011年间的历史数据筛选过滤生成,包含74万篇新闻文档(2.19 GB),均为UTF-8纯文本格式。包含财经、彩票、房产、股票、家居、教育、科技、社会、时尚、时政、体育、星座、游戏、娱乐14个领域。
下载好的数据集文件如下:

例如财经领域中的某篇新闻报道:
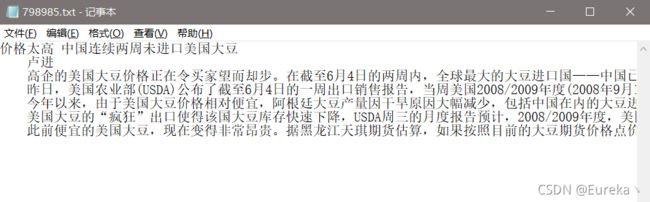
每个领域下面都有若干这样的txt文本数据。所以现在需要做的第一步就是如何把这些分散开的语料喂入模型中。
# 读取一个目录下的所有文件
class MySentences(object):
def __init__(self, dirname):
self.dirname = dirname
def __iter__(self):
for fname in os.listdir(self.dirname):
for line in open(os.path.join(self.dirname, fname), encoding='utf-8'):
yield line.split()拿财经领域的数据来演示:
# 针对THUCNews数据集的财经领域
File = './THUCNews/财经'
files = os.listdir(File) # 得到该文件夹下的所有文件名(包含后缀),输出为列表形式
for file in files:
with open(File + '/' + file, encoding='utf-8') as f1:
# 对每个文档的内容进行分词
document = f1.read()
document_cut = jieba.cut(document, cut_all=False)
# 分词之后用空格隔开并去掉标点符号
result = ' '.join(document_cut).replace(',', '').replace('。', '').replace('?', '').replace('!', '') \
.replace('“', '').replace('”', '').replace(':', '').replace(';', '').replace('…', '').replace('(', '').replace(')', '') \
.replace('—', '').replace('《', '').replace('》', '').replace('、', '').replace('‘', '') \
.replace('’', '')
# 处理好的语料文档的路径
datapath = './财经/' + file
with open(datapath, 'w', encoding="utf-8") as f2:
f2.write(result)# 利用自定义的读取一个文件夹下所有文件的函数来加载语料
sentences = MySentences('./财经')#创建临时文件
path = get_tmpfile("word2vec_2.model") #训练语料
model_2 = word2vec.Word2Vec(sentences, window=5, min_count=1, workers=4)# 任意查看与某个词最相似的前5个词语及相似度度量
for key in model_2.wv.similar_by_word('中国银行', topn=5):
print(key)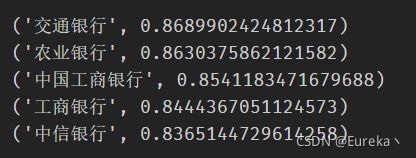
Word2Vec常用方法汇总:
在已经获取模型的前提下可以进行:
1. 获取每个词的词向量
model['词语']
2. 支持词语的加减运算(实际中可能只有少数例子比较符合)
model.most_similar(positive=['woman', 'king'], negative=['man'])
3. 计算两个词之间的余弦距离
model.wv.similarity("好", "还行")
4. 计算余弦距离最接近“word”的10个词,或topn个词
model.most_similar("word")
model.wv.similar_by_word('词语', topn =100) 最接近的100个词
5. 计算两个集合之间的余弦似度
当出现某个词语不在这个训练集合中的时候,会报错
list_sim1 = model.n_similarity(list1, list2)
6. 选出集合中不同类的词语
model.doesnt_match("breakfast cereal dinner lunch".split())
更多方法及版本迁移可以参考gensim的官方文档。