Word2Vec原理简单解析
前言
词的向量化就是将自然语言中的词语映射成是一个实数向量,用于对自然语言建模,比如进行情感分析、语义分析等自然语言处理任务。下面介绍比较主流的两种词语向量化的方式:

第一种即One-Hot编码
是一种基于词袋(bag of words)的编码方式。假设词典的长度为 N 即包含 N 个词语,并按照顺序依次排列。One-Hot 编码将词语表示成长度为 N 的向量,每一向量分量代表词典中的一个词语,则 One-Hot 编码的词语向量只有一位分量值为 1。假设词语在词典中的位置为 k,那么该词语基于 One-Hot 编码的词语向量可表示为第 k 位值为 1,其他位全为 0 的向量。这种方式很容易理解,比如:
假设我们有词典{今天,我,不想,去,上课,因为,我,是,小宝宝},那么句子“今天我不想去上课”就可以表示为”[1,1,1,1,1,0,0,0,0],“因为我是小宝宝”就可以表示为[0,0,0,0,0,1,1,1,1]。这种编码方式简单明了。但是也具有明显的问题:
- 未能考虑词语之间的位置顺序关系;
- 无法表达词语所包含的语义信息;
- 无法有效地度量两个词语之间的相似度;
- 具有维度灾难。
第二种是word2vec
在说明 Word2vec 之前,需要先解释一下 Word Embedding。
什么是 Word Embedding
它就是将「不可计算」「非结构化」的词转化为「可计算」「结构化」的向量。
Word2vec 是 Word Embedding 的方法之一。他是 2013 年由谷歌的 Mikolov 提出了一套新的词嵌入方法。
Word2vec 在整个 NLP 里的位置可以用下图表示:

word embedding 最初其实是从NNLM开始的,虽然该模型的本质不是为了训练语言模型,word embedding 只是他的副产品。其架构为:
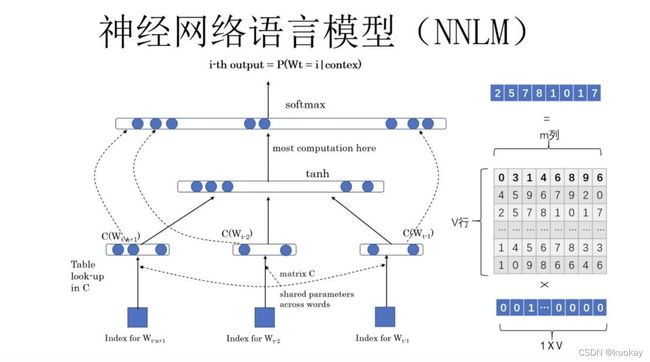
该模型是以无监督方式从海量文本语料中学习富含语义信息的低维词向量的语言模型,word2vec 词向量模型将单词从原先所属的空间映射到新的低维空间,使得语义上相似的单词在该空间内距离相近,word2vec 词向量可以用于词语之间相似性度量,由于语义相近的词语在向量山空间上的分布比较接近,可以通过计算词向量间的空间距离来表示词语间的语义相似度,因此 word2vec 词向量具有很好的语义特性。word2vec 模型是神经网络在自然语言处理领域应用的结果,它是利用深度学习方法来获取词语的分布表示,可以用于文本分类、情感计算、词典构建等自然语言处理任务。
简单的举个例子,“老师”之于“学生”类似于“师父”之于“徒弟”,“老婆”之于“丈夫”类似于“女人”之于“男人”。
Word2vec 的 2 种训练模式
word2vec 包含两种训练模型,分别是连续词袋模型 CBOW 和 Skip-gram 模型。其中CBOW 模型是在已知词语 W(t)上下文 2n 个词语的基础上预测当前词 W(t);而 Skip-gram模型是根据词语 W(t)预测上下文 2n 个词语。假设 n=2,则两种训练模型的体系结构如图所示,Skip-gram 模型和连续词袋模型 CBOW 都包含输入层、投影层、输出层。
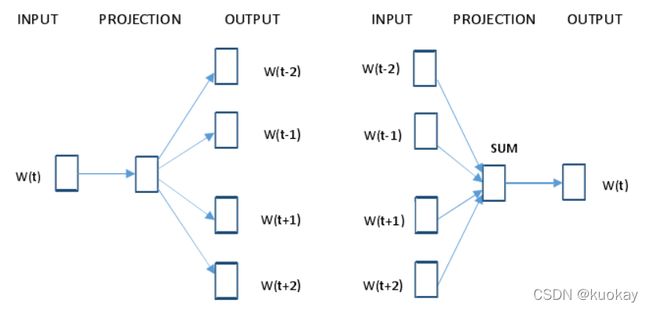
(左边为Skip-gram模型,右边为CBOW模型)
假设语料库中有这样一句话"The cat jumped over the puddle",以 Skip-gram模型为例,它是要根据给定词语预测上下文。如果给定单词"jumped"时,Skip-gram 模型要做的就是推出它周围的词:“The”, “cat”, “over”, “the”, “puddle”,如图所示。

要实现这样的目标就要让如公式1的条件概率值达到最大,也即在给定单词 W(t) 的前提下,使单词 W(t)周围窗口长度为 2n 内的上下文的概率值达到最大。为了简化计算,将公式1转化为公式2,即求公式2的最小值。
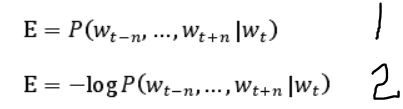
CBOW 模型和上面差不多,仅仅是将条件概率的前后两项颠倒了个,它是要根据上下文预测目标词语出现的概率。如给定上下文"The", “cat”, “over”, “the”, “puddle”,CBOW 模型的目标是预测词语"jumped"出现的概率,如图所示:

要实现这样的目标就要让如公式3的条件概率值达到最大,即在给定单词 W(t)上下文 2n 个词语的前提下,使单词 W(t)出现的概率值达到最大,同样为了简化计算,将公式3转化为公式4,即求公式4的最小值。
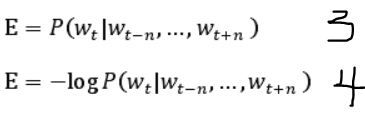
我们接下来会在pycharm中演示word2vec,这里首先要选取语料库,我从网上下载了一份三国演义的原文,并进行了中文分词处理,采用的是jieba库。
import jieba.analyse
import codecs
f=codecs.open('F:/nlp/SanGuoYanYi.txt','r',encoding="utf8")
target = codecs.open("F:/nlp/gushi.txt", 'w',encoding="utf8")
print('open files')
line_num=1
line = f.readline()
#循环遍历每一行,并对这一行进行分词操作
#如果下一行没有内容的话,就会readline会返回-1,则while -1就会跳出循环
while line:
print('---- processing ', line_num, ' article----------------')
line_seg = " ".join(jieba.cut(line))
target.writelines(line_seg)
line_num = line_num + 1
line = f.readline()
#关闭两个文件流,并退出程序
f.close()
target.close()
exit()
我们在上面的代码中进行了分词处理,得到类似下面的txt文档:

基于上面已经处理好的文档,我们进行word2vec的词向量训练:
# -*- coding: utf-8 -*-
from gensim.models import Word2Vec
from gensim.models.word2vec import LineSentence
import logging
logging.basicConfig(format='%(asctime)s : %(levelname)s : %(message)s', level=logging.INFO)
# Word2Vec第一个参数代表要训练的语料
# sg=1 表示使用Skip-Gram模型进行训练
# size 表示特征向量的维度,默认为100。大的size需要更多的训练数据,但是效果会更好. 推荐值为几十到几百。
# window 表示当前词与预测词在一个句子中的最大距离是多少
# min_count 可以对字典做截断. 词频少于min_count次数的单词会被丢弃掉, 默认值为5
# workers 表示训练的并行数
#sample: 高频词汇的随机降采样的配置阈值,默认为1e-3,范围是(0,1e-5)
def A():
#首先打开需要训练的文本
shuju = open('F:/nlp/gushi.txt', 'rb')
#通过Word2vec进行训练
model = Word2Vec(LineSentence(shuju), sg=1,size=100, window=10, min_count=5, workers=15,sample=1e-3)
#保存训练好的模型
model.save('F:/nlp/SanGuoYanYiTest.word2vec')
print('训练完成')
if __name__ == '__main__':
A()
显示“训练完成”后我们就得到了一个完好的模型,输出和“赤兔马”最相关的词语,以及其词向量,测试结果如下:
