电影数据分析
项目介绍
1.项目背景
电影公司制作一部新电影推向市场时,要想获得成功,通常要了解电影市场趋势,观众喜好的电影类型,电影的发行情况,改编电影和原创电影的收益情况,以及观众喜欢什么样的内容
2.项目来源
本案例来源于 kaggle上的 TMDB 5000 Movie Dataset 数据集
下载地址:https://www.kaggle.com/tmdb/tmdb-movie-metadata
3.项目解决的问题
(1)电影类型如何随着时间的推移发生变化的?
(2)电影类型与利润的关系?
(3)Universal 和 Paramount 两家影视公司的对比情况如何?
(4)改编电影和原创电影的对比情况如何?
(5)电影时长与电影票房及评分的关系?
(6)分析电影关键字
(7)问题七 分析收益的影响因素
3.编程环境:vscode,python3
数据源整理
- 将数据下载,导入并输出
# coding= gbk
import seaborn as sns
from wordcloud import WordCloud
import collections
import numpy as np
from copy import deepcopy
import pandas as pd
import json
import matplotlib.pyplot as plt
# 数据集加载
# 加载数据 --credits
credits = pd.read_csv('./tmdb_5000_credits.csv')
print('credits:\n', credits)
print("_"*50)
print('credits:\n', credits.columns)
print("_"*50)
print('credits:\n', credits.info())
print("_"*50)
# 加载数据 --movies
movies = pd.read_csv('./tmdb_5000_movies.csv')
print('movies:\n', movies)
print("_"*50)
print('movies:\n', movies.columns)
print("_"*50)
print('movies:\n', movies.info())
print("_"*50)
- 得到两个csv文件的具体信息,如数据规模,及行、列索引等,整理得到如下电影数据说明表。
| 字段名 | 意义 |
|---|---|
| id | 标识号 |
| imdb_id | IMDB 标识号 |
| popularity | 在 Movie Database 上的相对页面查看次数 |
| budget | 预算(美元) |
| revenue | 收入(美元) |
| original_title | 电影名称 |
| cast | 演员列表 |
| crew | 中国人员 |
| homepage | 电影首页的 URL |
| director | 导演列表,按 |
| tagline | 电影的标语 |
| keywords | 与电影相关的关键字,按 |
| overview | 剧情摘要 |
| runtime | 电影时长 |
| genres | 风格列表,按 |
| production_companies | 制作公司列表,按 |
| release_date | 首次上映日期 |
| vote_count | 评论次数 |
| vote_average | 平均评分 |
| release_year | 发行年份 |
credits数据集主要记载了电影名称、演员列表,工作人员等信息,而movies数据集则记载了电影成本与收入、电影风格、电影关键字、上映时间等信息。注意到其中有许多与本项目无关的信息,合并时将除去这些片段
数据清洗
- 将credits和movies两个数据集进行合并,查看合并后的数据集信息
# 合并数据
# credits 中存在 movie_id 和 title, movies 中存在 id 和 title,因而采用这两列进行数据合并
# 将 credits 中的 movie_id 修改为 id,与movies达成一致
credits.rename(columns={'movie_id': 'id'}, inplace=True)
# 主键合并 --合并依据为 id 和 title
all_data = pd.merge(left=credits, right=movies, on=[
'id', 'title'], how='outer')
print('all_data:\n', all_data)
print('all_data:\n', all_data.columns)
print('all_data:\n', all_data.dtypes)
- 从中选取对本项目有帮助的数据列
# 选取数据列
all_data = all_data[['original_title', 'crew', 'release_date', 'genres', 'keywords','production_companies', 'production_countries', 'revenue','budget', 'runtime', 'vote_average']]
print('all_data:\n', all_data)
print('all_data:\n', all_data.columns)
print('all_data:\n', all_data.dtypes)
- 处理缺失值
#寻找缺失值并输出
serach_null = pd.isnull(all_data).sum()
print('缺失值检测结果:\n', serach_null)
#检测到release_date列存在一个缺失值,可以通过填充数据或者删除该行进行处理
#此处采用填充数据的方式
# 借助bool数组来获取缺失值位置的电影名称
null_array = all_data.loc[:, 'release_date'].isnull()
movie_name = all_data.loc[null_array, 'original_title']
print('the null_value movie is', movie_name)
#得到输出"America Is Still the Place",查询得到该电影最初上映于2014-06-01
#将数据填充到空值处
all_data.loc[null_array, 'release_date'] = '2014-06-01'
-
增加对本项目有帮助的数据列
本项目涉及电影利润分析,此处利用revenue和budget两列获得利润列profit
#增加profit列
all_data['profit'] = all_data['revenue'] - all_data['budget']
-
数据格式处理
注意到电影风格genres列为json类型,首映日期release_date列为object类型,希望转其转化为python类型
此外,注意到数据集中电影涉及范围较大,但release_date列精确到日,可以降低精确度,精确到年足以应对本项目分析需求。
# genres列处理
all_data.loc[:, 'genres'] = all_data.loc[:, 'genres'].transform(json.loads)
# release_date列处理
# 将 release_date 转化为 pandas支持的时间序列
all_data.loc[:, 'release_date'] = pd.to_datetime(all_data.loc[:, 'release_date'])
# 将 release_date精确到年,并删除release_date列
all_data.loc[:, 'release_year'] = all_data.loc[:, 'release_date'].dt.year
all_data = all_data.drop(columns='release_date')
print(all_data.columns)
- 将处理完成的数据保存为all_data.csv
# 将处理完成的数据导入csv文件
all_data.to_csv("all_data.csv", index=False)
数据分析及可视化
问题一:电影类型如何随着时间的推移发生变化的?

代码实现:
# 问题一:电影类型如何随着时间的推移发生变化的?
# 构建所有的电影的类型
all_movie_type = set()
# 定义一个函数,来提取电影类型
def get_movie_type(val):
# 构建一个空列表,用来存储每一个电影的电影类型
type_list = []
# 遍历 列表
for item in val:
# 如果item存在
if item:
# 获取该电影的电影类型
movie_type = item['name']
# 将其加入到 type_list
type_list.append(movie_type)
# 将其加入到 all_movie_type
all_movie_type.add(movie_type)
return ','.join(type_list)
# 调用
all_data.loc[:, 'genres'] = all_data.loc[:, 'genres'].transform(get_movie_type)
# 将所有的电影类型转化为 list
all_movie_type = list(all_movie_type)
# 拷贝all_data,并增加种类列
all_data_genres = deepcopy(all_data)
for column in all_movie_type:
all_data_genres.loc[:, column] = 0
# 构建bool数组
mask = all_data_genres.loc[:, 'genres'].str.contains(column)
# 修改
all_data_genres.loc[mask, column] = 1
# 按照年份对电影类型进行聚类分析
year_genres = all_data_genres.groupby(by='release_year')[all_movie_type].sum()
plt.figure(figsize=(20, 8), dpi=80)
x = year_genres.index
for movie_type in year_genres.columns:
y = year_genres[movie_type]
plt.plot(x, y)
plt.title('year_genres')
plt.legend(year_genres.columns, fontsize='x-small')
plt.ylabel('number')
plt.xlabel('year')
plt.grid(b=True, alpha=0.2)
plt.title = "year_genres"
# 保存图片
plt.savefig('./year_genres')

代码实现:
#绘制不同种类电影占比图
genres_sum = all_data_genres[all_movie_type].sum()
plt.figure(figsize=(16, 8), dpi=80)
plt.pie(genres_sum, labels=genres_sum.index, autopct="%1.2f%%")
plt.legend(bbox_to_anchor=(1.4, 0.8))
plt.title = "genres_sum"
plt.savefig('./genres_sum')
结论: 从图中观察到,随着时间的推移,所有电影类型都呈现出增长趋势,尤其是 1992 年以 后各个类型的电影均增长迅速,其中 Drama(戏剧)和 Comedy(喜剧)增长最快,目前仍是最热 门的电影类型。此外,在所有电影类型中,电影数量排名前 5 的电影类型分别为:Drama(戏剧)、Comedy(喜剧)、Thriller(惊悚)、Action(动作)、Romance(冒险)。其中,Drama(戏剧)类型占所有电影类型的 18.89%, Comedy(喜剧)占所有电影类型的14.16%,而Thriller(恐怖片)类型占所有电影类型的 10.48%
问题二:电影类型与利润的关系?
对电影类型进行处理,获得所有电影类型,并对不同类型的电影利润进行统计
# 问题二:电影类型与利润的关系
# 存在多列的数据为电影类型,不能使用分组聚合
# 构建一个list来存储各种类型电影的平均利润
type_profit = []
# 遍历 所有的 电影类型
for column in all_movie_type:
mask = all_data_genres.loc[:, column] == 1
mean_profit = all_data_genres.loc[mask, 'profit'].mean()
# 加入到 movie_type_profit
type_profit.append(mean_profit)
# 创建series
type_profit_series = pd.Series(data=type_profit,index=all_movie_type).sort_values()

代码实现:
# 绘制柱状图
plt.figure(figsize=(25, 10), dpi=80)
plt.bar(type_profit_series.index, type_profit_series, width=0.4)
plt.title = "type_profit"
plt.xticks(rotation=90)
plt.ylabel("billion")
plt.grid(linestyle="--", alpha=0.5)
plt.text("TV Movie", 3e+06, "-1.15")
plt.text("Foreign", 3e+06, "-2.93")
plt.savefig('./type_profit')
分析结论:拍摄 Animation、Adventure、Fantasy 这三类电影盈利最好,平均盈利为15.9、14.2、13.0千万,而拍摄 Foreign、TV Movie 这两类电影会存在亏本的风险。选材及拍摄时最好选择 Animation、Adventure、Fantasy 三种类型。
问题三:Universal Pictures 和 Paramount Pictures 两家影视公司发行 电影的对比情况如何?
拷贝all_data,并增加两列,以判断电影属于哪一公司。绘制两家公司电影总量占比图。

代码实现:
# 问题三:Universal Pictures 和 Paramount Pictures 两家影视公司发行 电影的对比情况如何?
all_data_firm = deepcopy(all_data)
# 由于一部电影可能对应多个公司,不直接使用聚合函数
all_data_firm.loc[:, 'Universal Pictures'] = 0
all_data_firm.loc[:, 'Paramount Pictures'] = 0
# bool数组
mask1 = all_data_firm.loc[:, 'production_companies'].str.contains(
'Universal Pictures')
# 修改
all_data_firm.loc[mask1, 'Universal Pictures'] = 1
# bool数组
mask2 = all_data_firm.loc[:, 'production_companies'].str.contains(
'Paramount Pictures')
# 修改
all_data_firm.loc[mask2, 'Paramount Pictures'] = 1
print('all_data_firm):\n', all_data)
~~~python
#绘制不同公司电影占比图
all_firm= ['Universal Pictures','Paramount Pictures']
firm_sum = all_data_firm[all_firm].sum()
plt.figure(figsize=(16, 8), dpi=80)
plt.pie(firm_sum, labels=all_firm, autopct="%1.2f%%")
plt.legend(bbox_to_anchor=(1.4, 0.8))
plt.title = "firm_sum_pie"
plt.savefig('./firm_sum_pie')

代码实现:
# 按照年份对电影所属公司进行聚类分析
year_firm = all_data_firm.groupby(by='release_year')[all_firm].sum()
plt.figure(figsize=(20, 8), dpi=80)
x = year_firm.index
for firm in year_firm.columns:
y = year_genres[firm]
plt.plot(x, y)
plt.title('year_genres')
plt.legend(year_genres.columns, fontsize='x-small')
plt.ylabel('number')
plt.xlabel('year')
plt.grid(b=True, alpha=0.2)
plt.title = "year_firm"
# 保存图片
plt.savefig('./year_firm')
问题四:改编电影和原创电影的对比情况如何?
对原创、非原创两种电影进行对比,绘制柱状图。

对原创、非原创两种电影的成本、收入、利润进行比较。

结论:电影市场的主流为非原创电影,将近是原创电影的十倍,这些电影平均成本和收益都很高,平均利润达到了原创电影的两倍,这可能是由于非原创电影早期有更多的受众支持。
代码实现:
#问题四:改编电影和原创电影的对比情况如何?
all_data_original = deepcopy(all_data)
all_data_original.loc[:, 'original'] = 'original'
# 含有base on的是非原创电影
mask = all_data_original.loc[:, 'keywords'].str.contains('based on')
all_data_original.loc[mask, 'original'] = 'not_original'
original_table = all_data_original.groupby(by='original', as_index=True)[
['budget', 'revenue', 'profit']].mean()
plt.figure()
plt.bar([1, 2, 3], original_table.loc["not_original"],
width=0.4, label="not_original")
plt.bar([1.4, 2.4, 3.4], original_table.loc["original"],
width=0.4, label="original")
plt.legend()
plt.xticks([1.2, 2.2, 3.2], ['budget', 'revenue', 'profit'])
plt.ylabel('million')
plt.title("original_analyse")
plt.savefig('./original_analyse')
plt.close()
original_sum = all_data_original.groupby(by='original', as_index=True)[
"original_title"].count()
print(original_sum)
plt.figure()
plt.pie(original_sum, labels=original_sum.index, autopct="%1.2f%%")
plt.legend(bbox_to_anchor=(0.8, 0.75))
plt.title("original_sum")
plt.savefig('./original_sum')
plt.close()
问题五:电影时长与电影票房及评分的关系

结论:时长在[150,180)这一区间的票房最佳,在[120,240)区间的电影平均能够取得较好的票房,而[150,360)区间内的电影平均能够获得较高均分。总体而言,电影时长最好控制在[150,240)z这一区间内。
代码实现:
# 问题五:电影时长与电影票房及评分的关系
all_data_time = deepcopy(all_data)
print(all_data_time)
#处理缺失值
mask = all_data_time.loc[:, 'runtime'].isnull()
movie_name = all_data_time.loc[mask, 'original_title'].index
#数据补全
all_data_time.loc[all_data.loc[:, 'original_title'] ==
'Chiamatemi Francesco - Il Papa della gente', 'runtime'] = 94
all_data_time.loc[all_data.loc[:, 'original_title']
== 'To Be Frank, Sinatra at 100', 'runtime'] = 81
# 进行离散化
bucket = [0, 60, 90, 120, 150, 180, 240, 360]
all_data_time.loc[:, 'runtime'] = pd.cut(all_data_time.loc[:, 'runtime'],
bins=bucket, include_lowest=True, right=False)
print(all_data_time.loc[:, 'runtime'].head)
# 分组聚合
runtime_table = all_data_time.groupby(
by='runtime')[['revenue', 'vote_average']].mean()
print(runtime_table["revenue"])
#绘制双坐标系图
figure, axes = plt.subplots(nrows=1, ncols=2, figsize=(20, 8), dpi=80)
axes[0].bar(x=[0, 1, 2, 3, 4, 5, 6], height=runtime_table["revenue"],
width=0.4, label="revenue")
axes[1].bar(x=[0, 1, 2, 3, 4, 5, 6], height=runtime_table["vote_average"],
width=0.4, label="vote_average")
x_label = ['[0, 60)', '[60, 90)', '[90, 120)',
'[120, 150)', '[150, 180)', '[180, 240)', '[240, 360)']
axes[0].set_xticks([0, 1, 2, 3, 4, 5, 6], x_label)
axes[1].set_xticks([0, 1, 2, 3, 4, 5, 6], x_label)
axes[0].legend(bbox_to_anchor=(0.2, 1))
axes[1].legend(bbox_to_anchor=(0.25, 1))
axes[0].set_title('runtime_revenue')
axes[1].set_title('runtime_vote_average')
plt.savefig("./runtime_table.png")
plt.close()
问题六 分析电影关键字
对处理keywords列,使其成为字符串列表,并作出词云。

出现次数前十的关键词信息如下
| 关键词 | 出现次数 |
|---|---|
| woman director | 324 |
| independent film | 318 |
| based on novel | 197 |
| murder | 189 |
| violence | 150 |
| dystopia | 139 |
| sport | 126 |
| revenge | 118 |
| sex | 111 |
| friendship | 106 |
all_data_kw = all_data["keywords"]
key_words_list = []
for item in all_data_kw:
item = eval(item)
if item:
key_words_list.extend([x['name'] for x in item if x['name'] not in [
'aftercreditsstinger', 'duringcreditsstinger']])
#建立计数列
words_count = collections.Counter(key_words_list)
print(words_count)
#创建词云对象,背景为白色
wc = WordCloud(
background_color='white',
max_words=2000,
max_font_size=100,
random_state=8,
)
wc.generate_from_frequencies(words_count)
plt.imshow(wc)
plt.axis('off')
plt.savefig('keyword_wordcloud.png')
问题七 分析收益的影响因素
对runtime,vote_average ,budget,release_year ,popularity ,revenue 等列进行回归分析,其中受欢迎度(popularity)和票房相关性:0.64,电影预算(budget)和票房相关性:0.73
做出相关性散点图和回归线如下
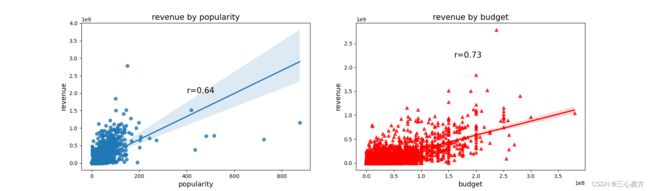
结论:受欢迎度、电影预算和票房呈现强相关性,制作电影时,应格外注意电影前期资金投入,并做好后期宣传等工作。可进一步挖掘数据集中受欢迎度的计算方法,并根据影响因素有的放矢。
代码实现:
# 问题七 分析收益的影响因素
influ = all_data[['runtime', 'vote_average', 'budget',
'release_year', 'popularity', 'revenue']].corr()
print(influ.loc["revenue", :])
fig = plt.figure(figsize=(17, 5))
ax1 = plt.subplot(1, 2, 1)
ax1 = sns.regplot(x=all_data['popularity'], y=all_data['revenue'],
data=all_data['revenue'], x_jitter=.1)
ax1.text(400, 2e9, 'r=0.64', fontsize=15)
plt.title('revenue by popularity', fontsize=15)
plt.xlabel('popularity', fontsize=13)
plt.ylabel('revenue', fontsize=13)
ax2 = plt.subplot(1, 2, 2)
ax2 = sns.regplot(x=all_data['budget'], y=all_data['revenue'],
data=all_data['revenue'], x_jitter=.1, color='r', marker='^')
ax2.text(1.6e8, 2.2e9, 'r=0.73', fontsize=15)
plt.title('revenue by budget', fontsize=15)
plt.xlabel('budget', fontsize=13)
plt.ylabel('revenue', fontsize=13)
fig.savefig('revenue_infu.png')
plt.close()
完整源码
# coding= gbk
import seaborn as sns
from wordcloud import WordCloud
import collections
import numpy as np
from copy import deepcopy
import pandas as pd
import json
import matplotlib.pyplot as plt
# 数据集加载
# 加载数据 --credits
credits = pd.read_csv('./tmdb_5000_credits.csv')
# 加载数据 --movies
movies = pd.read_csv('./tmdb_5000_movies.csv')
# 数据清洗
# 合并数据
# credits 中存在 movie_id 和 title, movies 中存在 id 和 title,因而采用这两列进行数据合并
# 将 credits 中的 movie_id 修改为 id,与movies达成一致
credits.rename(columns={'movie_id': 'id'}, inplace=True)
# 主键合并 --合并依据为 id 和 title
all_data = pd.merge(left=credits, right=movies, on=[
'id', 'title'], how='outer')
# 选取数据列
all_data = all_data[['original_title', 'crew', 'release_date', 'genres', 'keywords',
'production_companies', 'production_countries', 'revenue',
'budget', 'runtime', 'vote_average', 'popularity']]
# 寻找缺失值并输出
serach_null = pd.isnull(all_data).sum()
# 检测到release_date列存在一个缺失值,可以通过填充数据或者删除该行进行处理
# 此处采用填充数据的方式
# 根据bool数组来获取缺失值位置的电影名称
null_array = all_data.loc[:, 'release_date'].isnull()
movie_name = all_data.loc[null_array, 'original_title']
# 得到输出"America Is Still the Place",查询得到该电影最初上映于2014-06-01
# 将数据填充到空值处
all_data.loc[null_array, 'release_date'] = '2014-06-01'
# 增加profit列
all_data['profit'] = all_data['revenue'] - all_data['budget']
# 数据格式处理
# genres列处理
all_data.loc[:, 'genres'] = all_data.loc[:, 'genres'].transform(json.loads)
# release_date列处理
# 将 release_date 转化为 pandas支持的时间序列
all_data.loc[:, 'release_date'] = pd.to_datetime(
all_data.loc[:, 'release_date'])
# 将 release_date精确到年,并删除release_date列
all_data.loc[:, 'release_year'] = all_data.loc[:, 'release_date'].dt.year
all_data = all_data.drop(columns='release_date')
# 将处理完成的数据导入csv文件
all_data.to_csv("all_data.csv", index=False)
# 问题一:电影类型如何随着时间的推移发生变化的?
# 构建所有的电影的类型
all_movie_type = set()
# 定义一个函数,来提取电影类型
def get_movie_type(val):
# 构建一个空列表,用来存储每一个电影的电影类型
type_list = []
# 遍历 列表
for item in val:
# 如果item存在
if item:
# 获取该电影的电影类型
movie_type = item['name']
# 将其加入到 type_list
type_list.append(movie_type)
# 将其加入到 all_movie_type
all_movie_type.add(movie_type)
return ','.join(type_list)
# 调用
all_data.loc[:, 'genres'] = all_data.loc[:, 'genres'].transform(get_movie_type)
# 将所有的电影类型转化为 list
all_movie_type = list(all_movie_type)
# 拷贝all_data,并增加种类列
all_data_genres = deepcopy(all_data)
for column in all_movie_type:
all_data_genres.loc[:, column] = 0
# 构建bool数组
mask = all_data_genres.loc[:, 'genres'].str.contains(column)
# 修改
all_data_genres.loc[mask, column] = 1
# 按照年份对电影类型进行聚类分析
year_genres = all_data_genres.groupby(by='release_year')[all_movie_type].sum()
plt.figure(figsize=(20, 8), dpi=80)
x = year_genres.index
for movie_type in year_genres.columns:
y = year_genres[movie_type]
plt.plot(x, y)
plt.title('year_genres')
plt.legend(year_genres.columns, fontsize='x-small')
plt.ylabel('number')
plt.xlabel('year')
plt.grid(b=True, alpha=0.2)
plt.title = "year_genres"
# 保存图片
plt.savefig('./year_genres')
plt.close()
# 统计不同风格电影数量
genres_sum = all_data_genres[all_movie_type].sum()
plt.figure(figsize=(16, 8), dpi=80)
plt.pie(genres_sum, labels=genres_sum.index, autopct="%1.2f%%")
plt.legend(bbox_to_anchor=(1.4, 0.8))
plt.title = "genres_sum"
plt.savefig('./genres_sum')
plt.close()
# 问题二:电影类型与利润的关系
# 存在多列的数据为电影类型,不能使用分组聚合
# 构建一个list来存储各种类型电影的平均利润
type_profit = []
# 遍历 所有的 电影类型
for column in all_movie_type:
mask = all_data_genres.loc[:, column] == 1
mean_profit = all_data_genres.loc[mask, 'profit'].mean()
# 加入到 movie_type_profit
type_profit.append(mean_profit)
# 创建series
type_profit_series = pd.Series(
data=type_profit, index=all_movie_type).sort_values()
# 绘制柱状图
plt.figure(figsize=(25, 10), dpi=80)
plt.bar(type_profit_series.index, type_profit_series, width=0.4)
plt.title = "type_profit"
plt.xticks(rotation=90)
plt.ylabel("million")
plt.grid(linestyle="--", alpha=0.5)
plt.text("TV Movie", 3e+06, "-1.15")
plt.text("Foreign", 3e+06, "-2.93")
plt.savefig('./type_profit')
plt.close()
# 问题三:Universal Pictures 和 Paramount Pictures 两家影视公司发行 电影的对比情况如何?
all_data_firm = deepcopy(all_data)
# 由于一部电影可能对应多个公司,不直接使用聚合函数
all_data_firm.loc[:, 'Universal Pictures'] = 0
all_data_firm.loc[:, 'Paramount Pictures'] = 0
# bool数组
mask1 = all_data_firm.loc[:, 'production_companies'].str.contains(
'Universal Pictures')
# 修改
all_data_firm.loc[mask1, 'Universal Pictures'] = 1
# bool数组
mask2 = all_data_firm.loc[:, 'production_companies'].str.contains(
'Paramount Pictures')
# 修改
all_data_firm.loc[mask2, 'Paramount Pictures'] = 1
#绘制不同种类电影占比图
all_firm = ['Universal Pictures', 'Paramount Pictures']
firm_sum = all_data_firm[all_firm].sum()
plt.figure(figsize=(16, 8), dpi=80)
plt.pie(firm_sum, labels=all_firm, autopct="%1.2f%%")
plt.legend(bbox_to_anchor=(1.4, 0.8))
plt.title = "firm_sum_pie"
plt.savefig('./firm_sum_pie')
plt.close()
# 按照年份对电影所属公司进行聚类分析
year_firm = all_data_firm.groupby(by='release_year')[all_firm].sum()
plt.figure(figsize=(20, 10), dpi=80)
x = year_firm.index
for firm in year_firm.columns:
y = year_firm[firm]
plt.plot(x, y)
plt.title('year_firm')
plt.legend(year_firm.columns, fontsize='x-small')
plt.ylabel('number')
plt.xlabel('year')
plt.grid(b=True, alpha=0.2)
plt.title = "year_firm"
# 保存图片
plt.savefig('./year_firm')
plt.close()
# 问题四:改编电影和原创电影的对比情况如何?
all_data_original = deepcopy(all_data)
all_data_original.loc[:, 'original'] = 'original'
# 含有base on的是非原创电影
mask = all_data_original.loc[:, 'keywords'].str.contains('based on')
all_data_original.loc[mask, 'original'] = 'not_original'
original_table = all_data_original.groupby(by='original', as_index=True)[
['budget', 'revenue', 'profit']].mean()
plt.figure()
plt.bar([1, 2, 3], original_table.loc["not_original"],
width=0.4, label="not_original")
plt.bar([1.4, 2.4, 3.4], original_table.loc["original"],
width=0.4, label="original")
plt.legend()
plt.xticks([1.2, 2.2, 3.2], ['budget', 'revenue', 'profit'])
plt.ylabel('million')
plt.title("original_analyse")
plt.savefig('./original_analyse')
plt.close()
original_sum = all_data_original.groupby(by='original', as_index=True)[
"original_title"].count()
print(original_sum)
plt.figure()
plt.pie(original_sum, labels=original_sum.index, autopct="%1.2f%%")
plt.legend(bbox_to_anchor=(0.8, 0.75))
plt.title("original_sum")
plt.savefig('./original_sum')
plt.close()
# 问题五:电影时长与电影票房及评分的关系
all_data_time = deepcopy(all_data)
print(all_data_time)
#处理缺失值
mask = all_data_time.loc[:, 'runtime'].isnull()
movie_name = all_data_time.loc[mask, 'original_title'].index
#数据补全
all_data_time.loc[all_data.loc[:, 'original_title'] ==
'Chiamatemi Francesco - Il Papa della gente', 'runtime'] = 94
all_data_time.loc[all_data.loc[:, 'original_title']
== 'To Be Frank, Sinatra at 100', 'runtime'] = 81
# 进行离散化
bucket = [0, 60, 90, 120, 150, 180, 240, 360]
all_data_time.loc[:, 'runtime'] = pd.cut(all_data_time.loc[:, 'runtime'],
bins=bucket, include_lowest=True, right=False)
print(all_data_time.loc[:, 'runtime'].head)
# 分组聚合
runtime_table = all_data_time.groupby(
by='runtime')[['revenue', 'vote_average']].mean()
print(runtime_table["revenue"])
#绘制双坐标系图
figure, axes = plt.subplots(nrows=1, ncols=2, figsize=(20, 8), dpi=80)
axes[0].bar(x=[0, 1, 2, 3, 4, 5, 6], height=runtime_table["revenue"],
width=0.4, label="revenue")
axes[1].bar(x=[0, 1, 2, 3, 4, 5, 6], height=runtime_table["vote_average"],
width=0.4, label="vote_average")
x_label = ['[0, 60)', '[60, 90)', '[90, 120)',
'[120, 150)', '[150, 180)', '[180, 240)', '[240, 360)']
axes[0].set_xticks([0, 1, 2, 3, 4, 5, 6], x_label)
axes[1].set_xticks([0, 1, 2, 3, 4, 5, 6], x_label)
axes[0].legend(bbox_to_anchor=(0.2, 1))
axes[1].legend(bbox_to_anchor=(0.25, 1))
axes[0].set_title('runtime_revenue')
axes[1].set_title('runtime_vote_average')
plt.savefig("./runtime_table.png")
plt.close()
# 问题六
all_data_kw = all_data["keywords"]
key_words_list = []
for item in all_data_kw:
item = eval(item)
if item:
key_words_list.extend([x['name'] for x in item if x['name'] not in [
'aftercreditsstinger', 'duringcreditsstinger']])
#建立计数列
words_count = collections.Counter(key_words_list)
print(words_count)
#创建词云对象,背景为白色
wc = WordCloud(
background_color='white',
max_words=2000,
max_font_size=100,
random_state=8,
)
wc.generate_from_frequencies(words_count)
plt.imshow(wc)
plt.axis('off')
plt.savefig('keyword_wordcloud.png')
# 问题七 分析收益的影响因素
influ = all_data[['runtime', 'vote_average', 'budget',
'release_year', 'popularity', 'revenue']].corr()
print(influ.loc["revenue", :])
fig = plt.figure(figsize=(17, 5))
ax1 = plt.subplot(1, 2, 1)
ax1 = sns.regplot(x=all_data['popularity'], y=all_data['revenue'],
data=all_data['revenue'], x_jitter=.1)
ax1.text(400, 2e9, 'r=0.64', fontsize=15)
plt.title('revenue by popularity', fontsize=15)
plt.xlabel('popularity', fontsize=13)
plt.ylabel('revenue', fontsize=13)
ax2 = plt.subplot(1, 2, 2)
ax2 = sns.regplot(x=all_data['budget'], y=all_data['revenue'],
data=all_data['revenue'], x_jitter=.1, color='r', marker='^')
ax2.text(1.6e8, 2.2e9, 'r=0.73', fontsize=15)
plt.title('revenue by budget', fontsize=15)
plt.xlabel('budget', fontsize=13)
plt.ylabel('revenue', fontsize=13)
fig.savefig('revenue_infu.png')
plt.close()
savefig('keyword_wordcloud.png')
# 问题七 分析收益的影响因素
influ = all_data[['runtime', 'vote_average', 'budget',
'release_year', 'popularity', 'revenue']].corr()
print(influ.loc["revenue", :])
fig = plt.figure(figsize=(17, 5))
ax1 = plt.subplot(1, 2, 1)
ax1 = sns.regplot(x=all_data['popularity'], y=all_data['revenue'],
data=all_data['revenue'], x_jitter=.1)
ax1.text(400, 2e9, 'r=0.64', fontsize=15)
plt.title('revenue by popularity', fontsize=15)
plt.xlabel('popularity', fontsize=13)
plt.ylabel('revenue', fontsize=13)
ax2 = plt.subplot(1, 2, 2)
ax2 = sns.regplot(x=all_data['budget'], y=all_data['revenue'],
data=all_data['revenue'], x_jitter=.1, color='r', marker='^')
ax2.text(1.6e8, 2.2e9, 'r=0.73', fontsize=15)
plt.title('revenue by budget', fontsize=15)
plt.xlabel('budget', fontsize=13)
plt.ylabel('revenue', fontsize=13)
fig.savefig('revenue_infu.png')
plt.close()