目标检测-常见网络的梳理
整合了一些博主的博文:ID分别为太阳花的小绿豆、AI菌、Bubbliiiing!!!
感谢上述博主!!!
从B站一个博主视频里听到的一句话,觉得很有道理,就写在博文的前面了:学习一个网络模型,可以试着从处理数据、构建网络、损失函数、优化函数、模型保存这五部分来进行梳理学习;后续这篇博客自己也会试着从这五个方面不断去修改这篇博文;还有自己主要做的是工业场景下的PCB缺陷检测,代码以及数据集的话可以私信我!
目录
1.Two-Stage
1.1 R-CNN
1.2 Fast R-CNN
1.3 Fater R-CNN
2.One-Stage
2.1 SSD
2.2 YOLO系列
2.2.1 YOLOv1
2.2.2 YOLOv2
2.2.3 YOLOv3
2.2.4 YOLOv4
3.DETR
1.Two-Stage
1.1 R-CNN
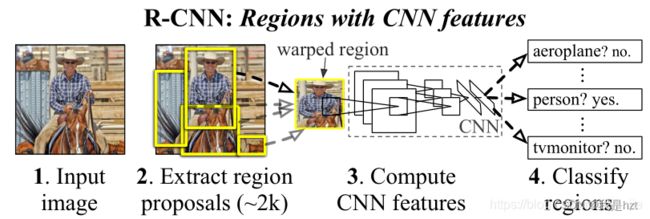
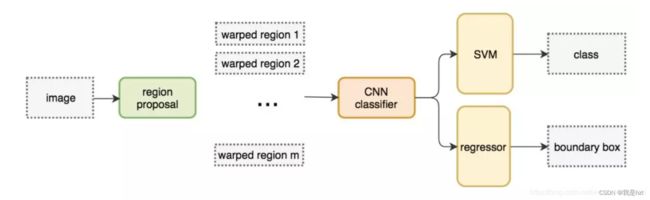
上图,R-CNN目标检测算法流程主要分为四步:
(1)利用 Selective Search 方法,在图像中确定大约1000-2000个候选框
(2)对于上述生成的所有候选框,每一个候选框均要利用CNN网络提取特征
(3)分类:将特征向量送入SVM分类器中,判断目标是否属于该类别
(4)回归:对于属于某一特征的候选框,用回归器进行位置上的调整
对上述涉及的几个点展开介绍:
第一:关于CNN网络提取特征,这里主要是利用ALexNet网络,其实第一个典型的CNN应该是LeNet5网络结构,有兴趣的可以自己查一查,包括其他的典型卷积网络;这里主要讲解AlexNet;
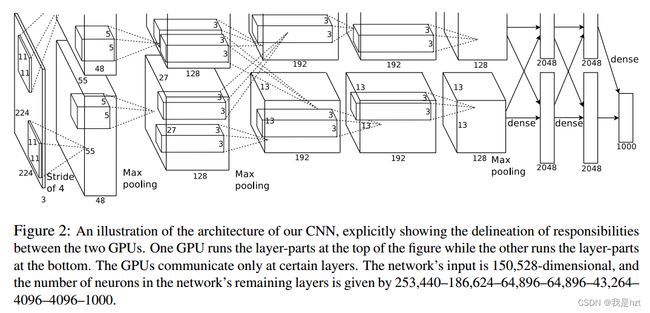
AlexNet网络结构图,其实可以简单理解为对称的网络,但是实际上并不是的,因为原论文写道的网络运行环境是两块GPU,这里主要讲解一个部分,以下面的网络进行部分讲解:
其中,上面AlexNet网络结构图并不是很清晰,原因在于网络结构中的参数其实并未体现出来,这里拿第一层进行简单分析。Input:224*224*3,彩色图像;Kernel大小为11*11*3(这里的3就是输入图像的通道数,且必须跟输入图像的通道数保持一致,否则无法计算的);图中已经说明:Stride is 4,Padding is 0,输出则:(224-11)/4+1=55,这里向上取整,55代表的是特征图的大小;维度就是图中所示:48*2=96,也可以理解为输出通道数;
图像变化:224*224*3 >>>>55*55*96
卷积结束之后,经过最大池化,最大池化与平均池化的区别基本就是区域内一个取最大值,一个取平均值;这里其实上图看不出来最大池化的相关参数,具体参数是:kernel大小:3*3*96;Stride is 2;卷积核的个数也就是输出通道数是96;经过最大池化特征图的大小:(55-3)/2+1=27;
图像变化:55*55*96>>>>27*27*96
这里可能跟图中的27*27*128无法对应,是因为还没有进行到这一步啦,这里再次经过卷积,Kernel:5*5*48(上面标注输入通道数是96,而这里写48,是从这只分析上下其中一个网络);Stride 和pad 其实更多的时候是需要我们自己去推算出来的,结合输出是27*27*128;可以得到卷积核的个数:128,与输出特征图的维度保持一致;Stride:1;Pad :2; (27-5+2*2)/1+1=27,这里的27虽然跟前面的输入特征图的27一样,但是并不是前面的27;
图像变化:27*27*96>>>>27*27*128
以上仅仅就是简单地对AlexNet的部分做了分析,可以按照此思路对网络进行梳理,包括训练参数的计算等等;
第二:R-CNN利用SS算法生成1000-2000个候选框,其实利用SS算法生成候选框的过程基本需要耗时2S左右,所以R-CNN算法的实时性其实很低很低,但是其实该算法实时性低的原因不单单只是因为SS算法这一块;关于CNN提取网络,需要把SS算法生成的所有框逐一送入CNN网络进行前向传播,SS生成的候选框尽管有重合,但是还是需要逐一送入CNN进行前向传播,计算比较繁琐;还有就是CNN中因为有全连接层的存在,因此的话,送入CNN的图(其实就是SS生成的所有候选框)是需要固定大小;
第三:网络其实可以看做几个部分(候选框的生成、CNN网络、分类器、回归器)组成,这几部分均需要单独进行训练,很麻烦,所以R-CNN并不是整整意义上实现端对端的检测;
1.2 Fast R-CNN
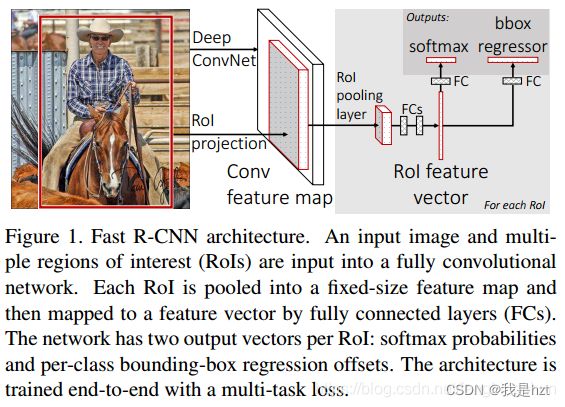
上图,Fast- R-CNN目标检测算法流程主要分为四步:
(1)利用SS算法生成1000-2000个候选框,其实这里的框后期网络并不是全部都要用的;
(2)整张图像送入BackBone,得到特征图,其次就是把SS算法生成的候选框投影到Feature Map,得到每一个候选框的特征矩阵;(结合SPP Net)
(3)每一个候选框通过在特征图上映射得到的特征矩阵,经过ROI Pooling,得到7*7的faeture Map;
(4)分类与回归;
这里的话,我主要把第二点具体说一些,关于R-CNN,可以看出来,每一个候选框送入CNN进行前向传播,假如2000框,此过程需要重复2000次;而Fast R-CNN改进之后,就是我先把图送入CNN,然后得到feature Map,在将候选框映射到Feature Map上,仅仅一次,所以这一块改进还是很有效的,其实就是第三点的尺寸问题,不再像R-CNN需要先把候选框必须强制缩放,可以最后通过ROI Pooling最后得到7*7的Feature Map;
1.3 Fater R-CNN
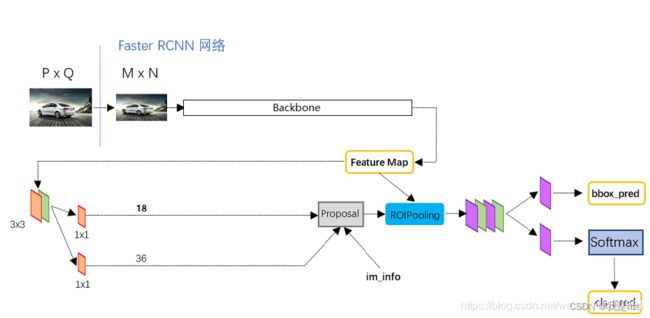
上图,Faster R-CNN目标检测算法流程主要分为四步:
(1)图像送入网络得到Feature Map;
(2)使用RPN生成候选框,将候选框投影到特征图上获得相应的特征矩阵
(3)每一个候选框通过在特征图上映射得到的特征矩阵,经过ROI Pooling,得到7*7的faeture Map;
(4)分类与回归;
2.One-Stage
2.1 SSD
讲解SSD之前,首先对VGG16进行相关介绍;首先VGG16中的16代表13个卷积层以及3个全连接层;当然,网络还包含了5个池化层;

224*224*3(Input)>>>224*224*64(卷积)>>>224*224*64(卷积)>>>112*112*64(池化)
>>>112*112*128(卷积)>>>112*112*128(卷积)>>>56*56*128(池化)
>>>56*56*256(卷积)>>>56*56*256(卷积)>>>56*56*256(卷积)>>>28*28*256(池化)
>>>28*28*512(卷积)>>>28*28*512(卷积)>>>28*28*512(卷积)>>>14*14*512(池化)
>>>14*14*512(卷积)>>>14*14*512(卷积)>>>14*14*512(卷积)>>>7*7*512(池化)
>>>7*7*49=25088(全连接)>>>1*1*4096(全连接)>>>1*1*1000(OutPut;1000分类,每个类别的分数)
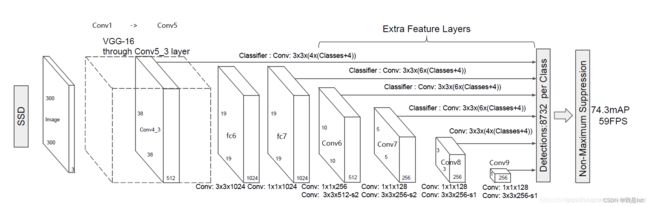
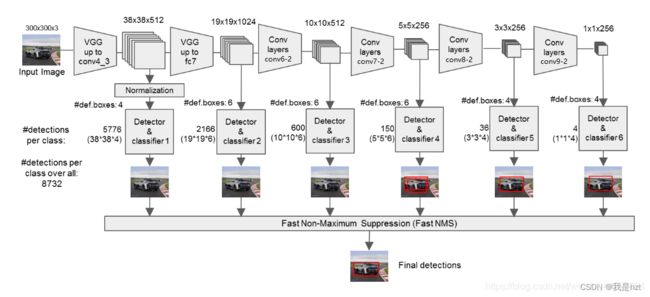 上面对VGG输入图像经过网路的每层之后的变化做了详细标注,大多时候其实没必要这些做,因为在Pycharm直接断点调试就可以看到每一层之后特征图的尺寸、维度变化的情况;这里做详细注释的原因是因为SSD对VGG做了轻微调整并且还有一部分特征图进行再次利用;
上面对VGG输入图像经过网路的每层之后的变化做了详细标注,大多时候其实没必要这些做,因为在Pycharm直接断点调试就可以看到每一层之后特征图的尺寸、维度变化的情况;这里做详细注释的原因是因为SSD对VGG做了轻微调整并且还有一部分特征图进行再次利用;
调整VGG16的改变,从图像看,就是标注的Extra Feature Layers,加上了四个卷积层,分别是conv6,conv7,conv8,conv9;后续分类与回归需要用到特征提取网络的六个特征层,分别是38*38*512,19*19*1024,10*10*512,5*5*256,3*3*256,1*1*256;4,6,6,6,4,4代表的是每个特征层中每一个特征点对应的先验框数量;就比图第一个38*38*512的特征层来讲,图像传入网络,会被分为38*38个小网格,每个网格中心对应4个先验框,一共有38*38*4=5776个先验框,网络会根据预测结果对这些先验框进行调整,并通过NMS最后得到一个预测框。
损失函数两部分组成:一部分位置损失函数,其实就是中心点坐标(x,y)与宽高w,h的损失计算;另一部分就是类别置信度的损失计算;
2.2 YOLO系列
2.2.1 YOLOv1
YOLO核心思想就是把目标检测转变成一个回归问题,利用整张图作为网络的输入,仅仅经过一个神经网络,得到预测框的位置以及所属的类别;

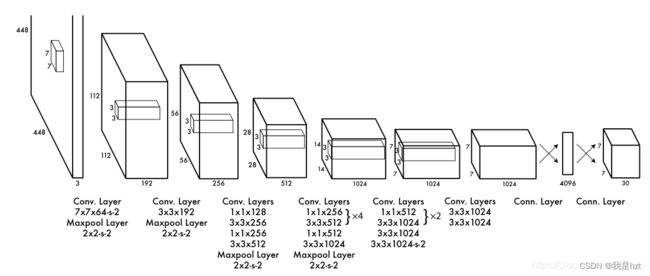
网络输入是448*448*3,经过一系列卷积与池化,用于提取图片的特征,全连接层网络最后有两个,主要是用来预测目标的位置以及类别得分情况,网络的输出是:7*7*30;这里7*7意思就是一张图片被分成了7*7个小网格,而30是两部分组成,第一部分是两个先验框,每个先验框的参数情况是(x,y,w,h,c),分别代表中心点坐标,长宽参数,类别置信度;20指的是类别的分类,这里网路用的是VOC数据集;
目标损失函数: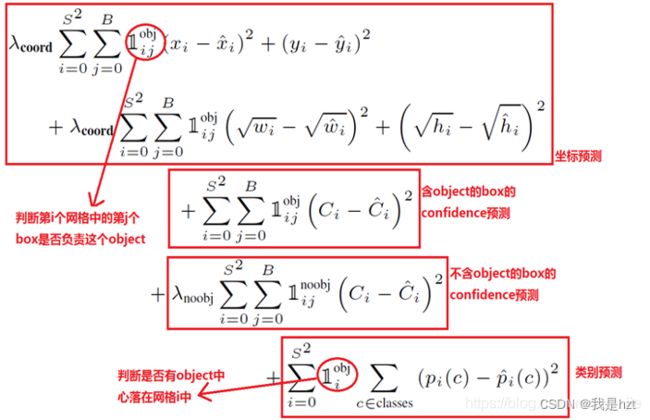
三部分组成:位置损失计算、置信度损失计算、类别损失计算;
其中位置损失计算,对整个模型损失计算影响比较大,所以设置权重因子5,而公式中中心点坐标直接做差进行平方运算,但是宽高并没有,主要是因为先验框的大小不一样,框比较大的时候,发生移动;与框比较小的时候,发生移动,这两个造成的影响是不一样的,所以这里先对宽高进行平方根运算,使得不论先验框尺寸大还是小,让它的计算误差尽可能准确;
置信度预测,含物体的先验框置信度的预测显然是我们关注的重点,因此包含物体先验框置信度的预测权重因子这里我们设定为1,而不含物体的先验框的置信度设定为0.5;
缺点:YOLO对于相互靠近的物体,或者密集的物体,检测效果很差;其次泛化能力比较差;
2.2.2 YOLOv2
YOLOv2是一个比较先进的目标检测算法,比其他的检测速度要快,还可以适应多种尺寸的图片输入,同时在精测精度以及速度上进行了很好的权衡;
(1)引入Anchor机制,利用K-means聚类训练更好的Anchor的尺寸;YOLOV1中,直接预测框的位置信息,其实网络训练前期是比较困难的,而且很难收敛;就好比现在让你猜一个数,但是我没有给你范围限定,这样基本很难猜中,但是我说了在0-1之间,虽然还是很多数,但从数学角度来讲,范围其实小了很多很多,或者说相比之前那个范围,这个已经是它的无穷小啦;


这里简单先接受一下,网络的位置预测结果输出是偏移量的信息,而不再是(x,y,w,h),其次考虑到每个网络的中心点仅仅负责预测自己网格的结果,又考虑因为网络预测结果的偏移量,使得先验框在图像上随便跑,因此使用sigmoid使得预测的偏移量固定在0-1之间,中心点坐标跑不出自己的小网格;
聚类:Anchor Box的大小比例,目前YOLO系列的源码中都会提供,但是假如换上自己的数据集进行训练预测,可能最后框的效果不是特别好,因此,目前大家更多的是:网络训练之前,利用聚类算法重新生成框的尺寸;
(2)采用Darknet-19作为特征提取网络

Darknet-19作为特征提取网络,可以从网络提取特征的速度以及计算速度考虑,可以在Pycharm中打印出VGG与Darknet-19网络中每层的结构参数以及总共需要训练的参数;
(3)Batch Normalization,批量标准化,BN层一般跟在卷积层或者池化层之后,激活函数之前,主要作用是对Data进行预处理,主要作用提高训练速度;
(4)特征融合;具体在YOLOV3中详细解释,其实就是一个特征图是13*13*2048;一个特征图是13*13*1024,这样特征图大小尺寸是相同的,但是维度不同,因此,将两个特征图进行融合,形成13*13*3072的特征图
2.2.3 YOLOv3
(1)特征提取网络的调整:Darkent19--->Darknet53,其实,从V1到V3,每一次改动都包含有backbone的调整;
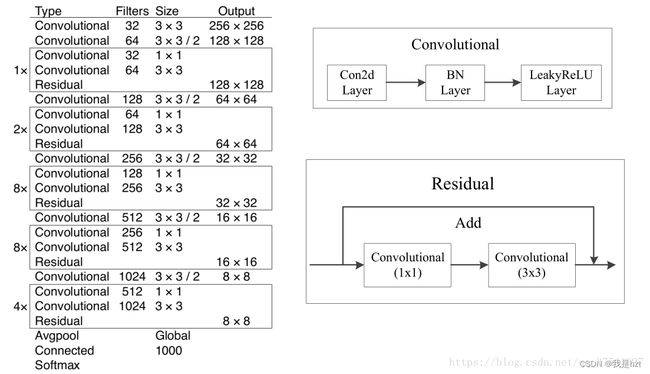
这里,Convolution不再仅仅说的是卷积,这里指的是一个卷积块:里面包含卷积、BN(前面V2中有介绍,批量标准化,为了让网络收敛更快)、LeakyReLu(激活函数)
53的由来:2+2+1+4+1+16+1+16+1+8=52,最后的一个Conected其实是全连接层,但是默认把它也算做卷积层啦,正好53层,而Residual并不是模块,仅仅想要说明的是1*1、3*3卷积构成残差网络的;
(2)特征金字塔实现多尺度检测

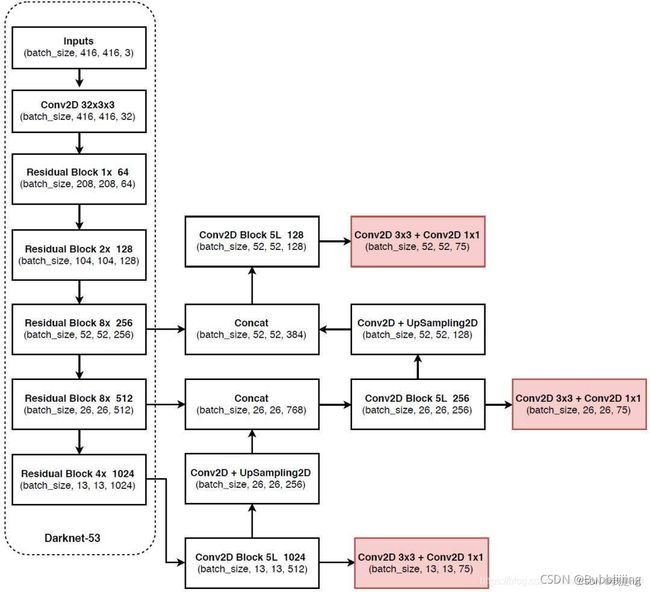
这里其实两张图都是V3的网络图,结合两张图对网络中特征金字塔部分进行讲解;从网络图中,可以看出来在特征提取网络提取到的特征层中,我们拿到了三个特征层,这里也叫做有效特征层,分别为52*52*256、26*26*512、13*13*1024(至于这个大小直接在代码断点调试看一下就行啦或者自己算一下),就拿一个有效特征层来讲,比图13*13*1024,从特征提取网络结束之后,进入Convolutional Set(1*1,3*3的卷积组成),再经过Convolutional(还是一样的,卷积+BN+激活函数组成的),最后经过Up Sampling,此时13*13*1024--->>>26*26*256,由特征提取网络得到的第二个有效特征层26*26*512,两个特征层尺寸一样,维度不同,这时就可以进行Conactenate;其余道理一样的;网络关键就在于我们要自己清楚,我们用的三个有效特整层来自那个地方,我们经过那些操作就可以进行特征层的融合啦;这样基本上YOLOv3的网络搭建就没啥问题啦;
输出:13*13*75,26*26*75,52*52*75;12,26,52就是我们需要把图片划分成多少个网格,至于75,是这样算出来的。75=3*(20+5),3说的是每个特征点上面都会有3个先验框,20是类别数,这里换成自己的数据集,输出相应做出改变,5的话指的是(x,y,w,h,c)
损失函数:目标位移偏移量损失(基本跟V2计算位置损失函数是一样的)、目标置信度损失(预测目标框内存在目标的概率,采用的是二值交叉熵损失)、目标分类损失(采用二值交叉熵损失);
2.2.4 YOLOv4

(1)主干特征提取网络:Darknet--->>>CSPDarknet53,其实Darket53大部分基本是由残差块组成的,这里第一点是,在V3的主干网络中,每一个卷积块都包含卷积+BN+激活函数;V4的主干网络中,激活函数换成了Mish,这是第一处小改变;第二处改变就是,图中所示,左图其实就是V3里面的残差块,残差块的组成V3已经介绍了;右图则是V4提出的残差结构,其实仅仅就是原来的残差结构继续视为残差结构,另一部分Part1直接像一条残差边连接至网络的输出;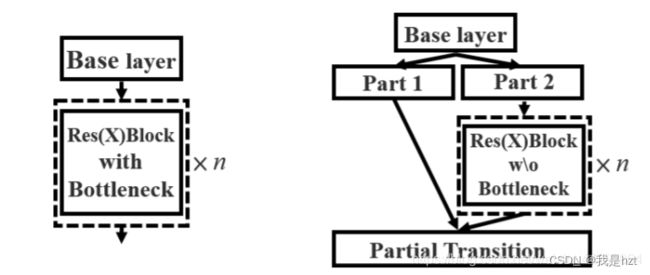
(2)SPP结构,其实主要组成就是四个池化核,分别为5*5,9*9,13*13,1*1(图中输入输出直接连接,其实就是1*1的池化核对特征图进行操作),这里池化核大小不一样,其实就是感受野不一样,进一步也就是对大小特征的敏感程度不一样,从SPP输出,先经过Concat,其实就是通道或者说特征图维度上的一个叠加;
(3)PANet:这部分其实有一些地方我们是见多的,比如SPP输出之后,自下往上;经过卷积,当然这里说的卷积还是三部分:卷积+BN+激活函数;之后上采样,然后就会发现可以看出在主干特征提取网络中,仍然有一个38*38*512的特征层与经过上述一些列操作的特征层进行了Concat,后续还有一次这样的操纵,这其实就是V3中的FPN(图像特征金字塔),但是到这里,V4的这部分结构并没有结束;多了一部分从底到顶的一次信息融合的流程,一样的道理,通过下采样减小特征图的尺寸,便可以进行Concat;
(4)预测与回归:与V3一样,输出层:19*19*75、38*38*75、76*76*75;这里75在V3中已经讲解啦,就是每一个特征点三个先验框,25是(x,y,w,h,c)与二十个类别,这个是VOC数据集;假设你换成了自己的数据集,这里以COCO数据集为例,80个类别,那就是3*(80+5)=255;
(5)Mosaic:V4中提出图像增强的技巧,该方法起源其实来自于CutMix,CutMix一般是利用两张图片进行拼接,这里提出的Trick,一般利用四张图像进行拼接,当作新的图像送入网络进行训练,当然标签图像也需要进行一模一样的处理,便于后续loss的计算;
2.2.5 YOLOV5
YOLOv5并没有论文,开源代码对应有n,s,m,l,x五个不同的版本,版本主要差别就在于精度与速度之间的权衡问题,自己可以灵活选择;
这里附上一个简单的网络结构图:

从整体来看,其实YOLOv3开始,基本的网络结构并没有太多的改变,V5其实也是分为三个部分,分别是Backbone、FPN、YOLO Head;
(1)对于主干特征提起网络:依旧使用残差网络,主干部分由1*1的卷积与3*3的卷积组成,残差边部分不做任何处理,直接将主干的输出与残差边的输出结合;

使用CSPnet网络结构,在v4中已经详细介绍了,且与v4是一样的;
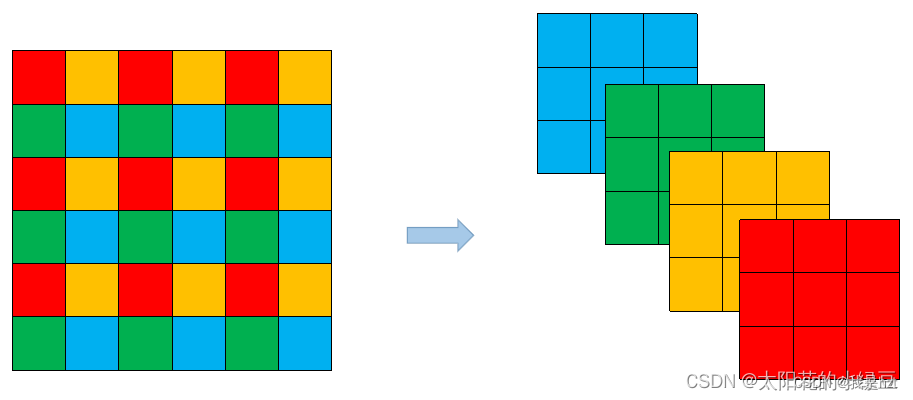
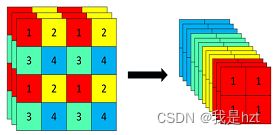
使用Focus网络结构,具体就是在一张图像中,各一个像素点拿一个值,这个时候就好比下图,就拿到了四个独立的特整层,可以抽象理解这其实就是卷积的操作,其次彩色图像三通道,这上述操作进行了三次,因此,一张图像输入通道就由原来的3变道了现在的12;
(2)SPP、PAnet一样的;