【Kafka】Kafka消费者相关策略
一、消费者消费消息流程
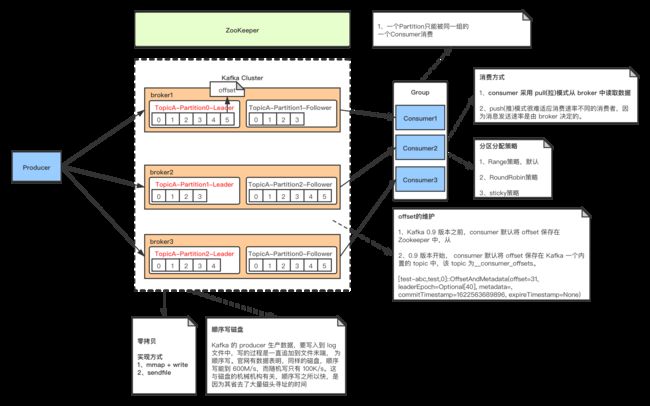
二、消费方式
consumer 采用 pull(拉)模式从 broker 中读取数据。
push(推)模式很难适应消费速率不同的消费者,因为消息发送速率是由 broker 决定的。 它的目标是尽可能以最快速度传递消息,但是这样很容易造成 consumer 来不及处理消息,典型的表现就是拒绝服务以及网络拥塞。而 pull 模式则可以根据 consumer 的消费能力以适 当的速率消费消息。
pull 模式不足之处是,如果 kafka 没有数据,消费者可能会陷入循环中,一直返回空数据。针对这一点,Kafka 的消费者在消费数据时会传入一个时长参数 timeout,如果当前没有 数据可供消费,consumer 会等待一段时间之后再返回,这段时长即为 timeout。
三、分区分配策略
一个 consumer group 中有多个 consumer,一个 topic 有多个 partition,所以必然会涉及 到 partition 的分配问题,即确定那个 partition 由哪个 consumer 来消费。
1、Range 范围分区(默认的)
假如有10个分区,3个消费者,把分区按照序号排列0,1,2,3,4,5,6,7,8,9;消费者为C1,C2,C3,那么用分区数除以消费者数来决定每个Consumer消费几个Partition,除不尽的前面几个消费者将会多消费一个,最后分配结果如下
C1:0,1,2,3 C2:4,5,6 C3:7,8,9
如果有11个分区将会是:
C1:0,1,2,3 C2:4,5,6,7 C3:8,9,10
假如我们有两个主题T1,T2,分别有10个分区,最后的分配结果将会是这样:
C1:T1(0,1,2,3) T2(0,1,2,3) C2:T1(4,5,6) T2(4,5,6) C3:T1(7,8,9) T2(7,8,9)
在这种情况下,C1多消费了两个分区
2、RoundRobin 轮询分区
把所有的partition和consumer列出来,然后轮询consumer和partition,尽可能的让把partition均匀的分配给consumer,假如有3个Topic T0(三个分区P0-0,P0-1,P0-2),T1(两个分区P1-0,P1-1),T2(四个分区P2-0,P2-1,P2-2,P2-3),有三个消费者:C0(订阅了T0,T1),C1(订阅了T1,T2),C2(订阅了T0,T2)
那么分区过程如下图所示
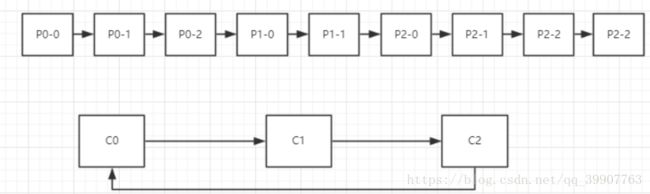
分区将会按照一定的顺序排列起来,消费者将会组成一个环状的结构,然后开始轮询。
- P0-0分配给C0
- P0-1分配给C1但是C1并没订阅T0,于是跳过C1把P0-1分配给C2,
- P0-2分配给C0
- P1-0分配给C1,
- P1-1分配给C0,
- P2-0分配给C1,
- P2-1分配给C2,
- P2-2分配给C1,
- p2-3分配给C2
C0: P0-0,P0-2,P1-1 C1:P1-0,P2-0,P2-2 C2:P0-1,P2-1,P2-3
3、Sticky分区
初始时分配策略与round-robin类似,但是在rebalance的时候,需要保证如下两个原则。 1)分区的分配要尽可能均匀 。
分区的分配尽可能与上次分配的保持相同。当两者发生冲突时,第一个目标优先于第二个目标 。这样可以最大程度维持原来的分区分配的策略。 比如对于第一种range情况的分配,如果第三个consumer挂了,那么重新用sticky策略分配的结果如下:
consumer1除了原有的0~3,会再分配一个7
consumer2除了原有的4~6,会再分配8和9
参考:https://www.cnblogs.com/hzmark/p/sticky_assignor.html
四、offset的维护
Kafka 0.9 版本之前,consumer 默认将 offset 保存在 Zookeeper 中,从 0.9 版本开始, consumer 默认将 offset 保存在 Kafka 一个内置的 topic 中,该 topic 为__consumer_offsets
每个consumer会定期将自己消费分区的offset提交给kafka内部topic:__consumer_offsets,提交过去的时候,key是 consumerGroupId+topic+分区号,value就是当前offset的值,kafka会定期清理topic里的消息,最后就保留最新的 那条数据
因为__consumer_offsets可能会接收高并发的请求,kafka默认给其分配50个分区(可以通过 offsets.topic.num.partitions设置),这样可以通过加机器的方式抗大并发。
五、高效读写数据
顺序写磁盘
Kafka 的 producer生产数据,要写入到log文件中,写的过程是一直追加到文件末端,为顺序写。数据表明,同样的磁盘,顺序写能到600M/s,而随机写只有100K/s。这与磁盘的机械结构有关,顺序写之所以快,是因为其省去了大量磁头寻址的时间。
零拷贝技术
零拷贝主要的任务就是避免CPU将数据从一块存储拷贝到另外一块存储,主要就是利用各种零拷贝技术,避免让CPU做大量的数据拷贝任务,减少不必要的拷贝,或者让别的组件来做这一类简单的数据传输任务,让CPU解脱出来专注于别的任务。这样就可以让系统资源的利用更加有效。