HBase Shell操作HBase进行预分区
本文将介绍如何使用HBase Shell操作HBase进行预分区。预分区是指在创建表的时候,指定表的初始分区点,从而使表的数据能够均匀地分布在多个RegionServer上,提高读写性能和负载均衡。本文将使用HBase Shell命令,创建不同的预分区表,并演示如何删除、刷新、查看和验证表的数据。
主要内容如下:
- 创建预分区表,指定SPLITS参数和COMPRESSION参数。
- 删除表的数据,使用deleteall或truncate命令。
- 刷新表的数据,使用flush命令。
- 查看表的数据,使用scan命令。
- 验证表的分区,使用scan hbase:meta命令。
本文使用了HBase Shell命令,通过交互式方式操作HBase进行预分区。也可以使用Java API或其他语言API
一、环境准备
- 安装HBase环境,并配置好集群。本文使用的是HBase 1.4.13版本,运行在三个Ubuntu系统的虚拟机中,分别作为master和slave节点。
- 启动HBase Shell,进入交互式命令行界面。可以使用以下命令:
hbase shell
二、创建预分区表
- 使用create命令,创建预分区表。该命令接受表名、列族名和SPLITS参数作为输入。SPLITS参数是一个数组,指定了表的初始分区点。例如:
create 't2', 'f1', SPLITS => ['1|', '2|', '3|']
-
该命令会创建一个名为t2的表,有一个列族f1,并且有四个初始分区,分别是:
- rowkey < ‘1|’
- ‘1|’ <= rowkey < ‘2|’
- ‘2|’ <= rowkey < ‘3|’
- ‘3|’ <= rowkey
-
可以使用不同的SPLITS参数,创建不同的预分区表。例如:
create 't3', 'f1', SPLITS => ['0', '1', '2']
create 't3index', 'f1'
create 't3index2', 'f1', SPLITS => [ '4', '7']
create 't3geo', 'f1', SPLITS => ['1', '2']
create 't3geo', 'f1', SPLITS => ['0', '1', '2']
create 't32', 'f1', SPLITS => ['0', '1', '2']
create 'tgeo3', 'f1', SPLITS => ['0', '1', '2']
create 't3feature', 'f1', SPLITS => ['0', '1', '2']
- 可以使用COMPRESSION参数,指定列族的压缩方式。例如:
create 'rawdata', {NAME=>'f1',COMPRESSION=>'SNAPPY'},{SPLITS=> ['1', '2']}
-
该命令会创建一个名为rawdata的表,有一个列族f1,并且使用SNAPPY压缩方式,并且有三个初始分区,分别是:
- rowkey < ‘1’
- ‘1’ <= rowkey < ‘2’
- ‘2’ <= rowkey
三、删除表的数据
- 使用deleteall命令,删除表中某一行的所有数据。该命令接受表名和行键作为输入。例如:
deleteall 'test','row1'
-
该命令会删除test表中行键为row1的所有数据。
-
使用truncate命令,删除表中所有数据,并重新创建空表。该命令接受表名作为输入。例如:
truncate 'test'四、刷新表的数据
- 使用flush命令,刷新表的数据,将内存中的数据写入到HDFS中。该命令接受表名作为输入。例如:
flush 't3feature'
- 该命令会刷新t3feature表的数据,保证数据的持久性。
写入HBase少量数据spark可能读取不到,刷写到HDFS之后可解决。
五、查看表的数据
- 使用scan命令,扫描表的数据,并显示在控制台上。该命令接受表名和一些可选参数作为输入。例如:
scan 't3feature'
-
该命令会扫描t3feature表的所有数据,并显示行键和列值。
-
可以使用COLUMNS参数,指定要扫描的列族或列名。例如:
scan 't3feature',{COLUMNS=>'f1:2020-11NDVI'}
- 该命令会扫描t3feature表的f1列族下的2020-11NDVI列,并显示行键和列值。
六、验证表的分区
- 使用scan命令,扫描hbase:meta表的数据,查看表的分区信息。该命令接受表名作为输入。例如:
scan 'hbase:meta'
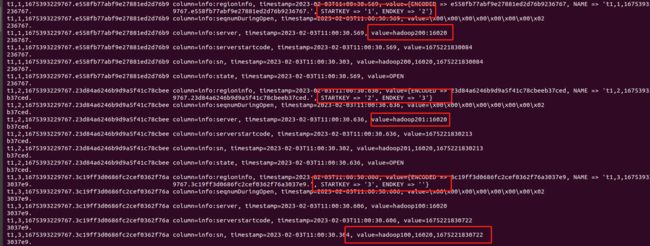
从上图可看出region均匀的分布在了3台regionserver上(集群就3台机器regionserver),达到预期效果。还可以在hbase的web UI界面中更加直观的查看建表的预分区信息。

-
该命令会扫描hbase:meta表的所有数据,并显示每个表的分区点和所在的RegionServer。
-
可以使用grep命令,过滤出某个表的分区信息。例如:
scan 'hbase:meta' | grep t3feature
- 该命令会扫描hbase:meta表的所有数据,并只显示t3feature表的分区点和所在的RegionServer。
- 再看看写数据是否均匀的命中各个region,是否能够做到对写请求的负载均衡:

