requests+BeautifulSoup入门——爬取2015-2020年中国大学排名并写入csv文件中
requests作为python第三方库,为用户爬取网页内容省下很多力气
BeautifulSoup同样也是python第三方库,它可以将用requests获取到的网页内容美化,也就是做成一碗“美味的汤”
目标:爬取2015年-2020年中国大学排名并写入csv文件中
思路:利用requests获取网页内容,再利用beautifulsoup对爬到的网页做处理,最终得到想要的数据
废话不多说,现在就开始做
首先找到我们要爬取的网页地址:https://www.shanghairanking.cn/
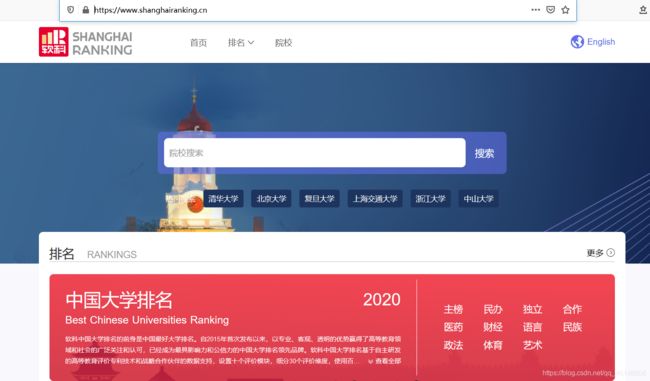 点击中国大学排名2020进入排名网址
点击中国大学排名2020进入排名网址
 选择年份-2015-
选择年份-2015-
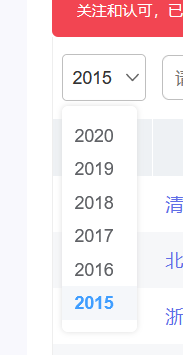
我们可以看到现在的排名情况:
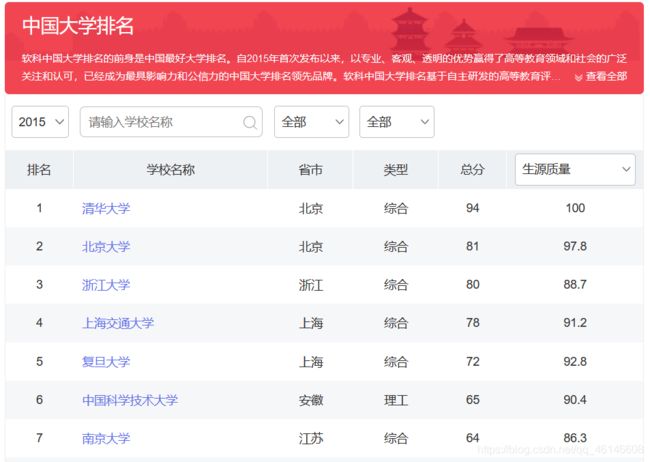
按键盘上的F12,查看网页元素,点击选取页面中的元素
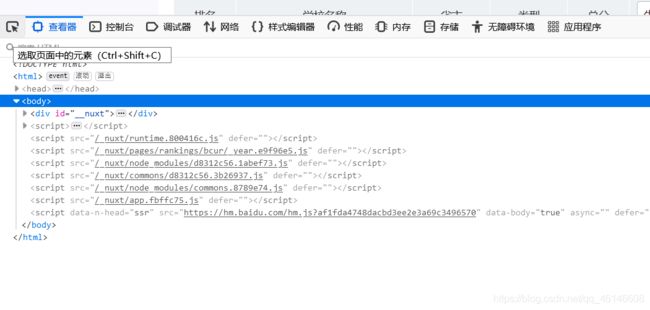
用鼠标点击第一个大学的排名

我们发现下方td被标记,也就是说,当前元素在网页中的位置在td的标签下,我们再重复上一个过程,但将鼠标点击到学校名称上
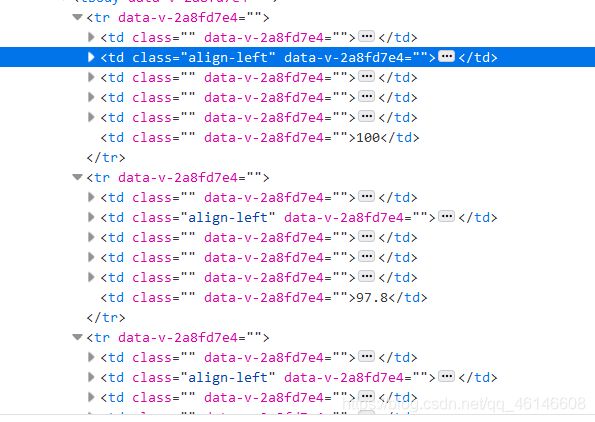
我们发现,大学的名称也是在td标签内,那么我们可以得到结论,每一个大学的信息都在td内,而每个大学都在一个tr标签内,那么同时可以发现,我们要找的所有tr都在一个tbody内

找到我们的元素位置之后我们就可以开始写代码了!
打开cmd,安装requests库:pip install requests
安装bs4库:pip install bs4
打开python编译器
添加库:
import requests
from bs4 import BeautifulSoup
import bs4
import csv
那么接下来进行第一步:获取网页内容
首先写一个函数getHTMLText
def getHTMLText(url):
#尝试获取网页内容
try:
r=requests.get(url)
#获取网页访问状态
r.raise_for_status()
#将编码方式改为中文
r.encoding=r.apparent_encoding
#返回得到的网页内容
return r.text
except:
#若获取失败则返回字符串
return '获取网页失败'
得到网页内容后,就要对网页内容进行筛选获取到想得到的信息
def catchData(ulist,html):
#利用BeautSoup对获取到的网页进行处理
soup=BeautifulSoup(html,'html.parser')
#我们找到tbody的孩子标签,也就是tr
for tr in soup.find('tbody').children:
#获取tr下的td标签内容,由于有多个td,所以将得到一个列表
if isinstance(tr,bs4.element.Tag):
tds=tr('td')
#将得到的td标签中的文字分别添加到ulist列表中
ulist.append([tds[0].text.strip(),tds[1].text.strip(),tds[2].text.strip(),tds[3].text.strip(),tds[4].text.strip()])
写完这一步,我们想要的数据已经获取到了,接下来就要将我们得到数据写道csv表格中
def writeList(ulist,num,year):
#创建一个年份+中国大学排名.csv的文件,编码方式为gb2312
f = open(year+'年中国大学排名.csv','w',encoding='gb2312',newline='')
csv_writer = csv.writer(f)
#写入标题:排名,名称,省份,类型,总分
csv_writer.writerow(['排名','名称','省份','类型','总分'])
#根据输入的写入量进行写入
for i in range(num):
u=ulist[i]
#写入每条数据的前五个数据分别是:排名,名称,省份,类型,总分
csv_writer.writerow([u[0],u[1],u[2],u[3],u[4]])
#写入完毕关闭文件
f.close()
#打印写入成功提示
print(year+'年中国大学排名爬取成功')
定义主函数
if __name__ == '__main__':
#从2015写到2020
for year in range(2015,2021):
#定义空列表
uinfo=[]
#定义网址
url = 'https://www.shanghairanking.cn/rankings/bcur/'+str(year)+'11'
#获取网页内容
html = getHTMLText(url)
#获取数据
catchData(uinfo,html)
#写入文件,写入20个
writeList(uinfo,20,str(year))
接下来查看运行效果

查看和py文件同一文件夹
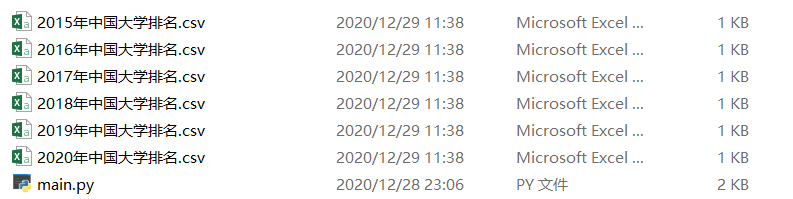
可以看到已经存在表格,那么现在随便打开一个表格

与网站进行对比
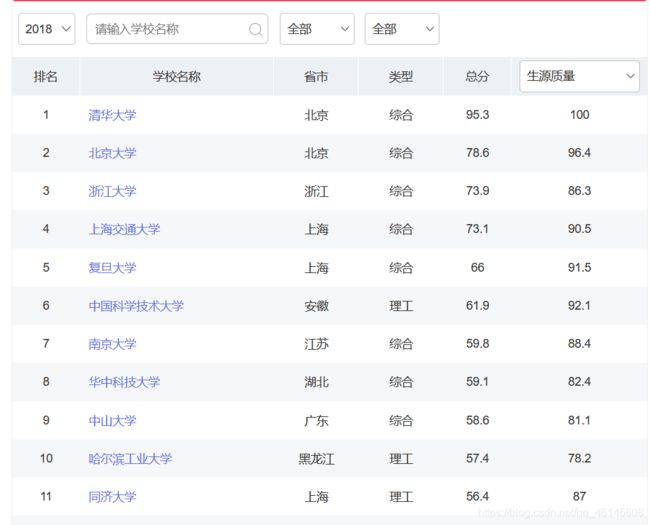
数据相同,爬取成功!
下面是完整代码:
import requests
from bs4 import BeautifulSoup
import bs4
import csv
def getHTMLText(url):
try:
r=requests.get(url)
r.raise_for_status()
r.encoding=r.apparent_encoding
return r.text
except:
return '获取网页失败'
def catchData(ulist,html):
soup=BeautifulSoup(html,'html.parser')
for tr in soup.find('tbody').children:
if isinstance(tr,bs4.element.Tag):
tds=tr('td')
ulist.append([tds[0].text.strip(),tds[1].text.strip(),tds[2].text.strip(),tds[3].text.strip(),tds[4].text.strip()])
def writeList(ulist,num,year):
f = open(year+'年中国大学排名.csv','w',encoding='gb2312',newline='')
csv_writer = csv.writer(f)
csv_writer.writerow(['排名','名称','省份','类型','总分'])
for i in range(num):
u=ulist[i]
csv_writer.writerow([u[0],u[1],u[2],u[3],u[4]])
f.close()
print(year+'年中国大学排名爬取成功')
if __name__ == '__main__':
for year in range(2015,2021):
uinfo=[]
url = 'https://www.shanghairanking.cn/rankings/bcur/'+str(year)+'11'
html = getHTMLText(url)
catchData(uinfo,html)
writeList(uinfo,20,str(year))
下一篇:利用爬取到的表格画出基于2015年前十名大学6年内的排名变化