简易版python爬虫--通过关键字爬取网页
背景:
帮同学写了个爬虫程序,特此记录,怕以后忘了
这里是爬取百度https://www.baidu.com
不为什么,主要就是百度老实,能爬,爬着简单,爬着不犯法。。。
关键字爬取基本模板:
import requests
from bs4 import BeautifulSoup
import random
import time
def searchbaidu(keyword):
url = f"https://www.baidu.com/s?wd={keyword}"
user_agents = [
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Edge/20.10240.16384 Safari/537.36',
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Edg/85.0.564.44 Safari/537.36',
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Edg/80.0.361.109 Safari/537.36',
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Edg/80.0.361.57 Safari/537.36',
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Edg/79.0.309.68 Safari/537.36',
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Edg/78.0.276.19 Safari/537.36',
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Edg/77.0.235.9 Safari/537.36',
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Edg/75.0.139.8 Safari/537.36',
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Edg/74.1.96.24 Safari/537.36',
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Edg/73.0.3683.75 Safari/537.36'
]
headers = {
'User-Agent': random.choice(user_agents)
}
response = requests.get(url, headers=headers)
time.sleep(random.uniform(0.5, 3)) # 设置访问频率限制
soup = BeautifulSoup(response.content, "html.parser")
results = soup.find_all("div", class_="result")
for result in results:
try:
title = result.find("h3").text
link = result.find("a")["href"]
print(title)
print(link)
except:
continue
说明:
随机用户,反反爬虫
这个程序是有一点小优化的,主要就是进行了一点点小小的反反爬虫措施
如:
user_agents = [
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Edge/20.10240.16384 Safari/537.36',
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Edg/85.0.564.44 Safari/537.36',
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Edg/80.0.361.109 Safari/537.36',
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Edg/80.0.361.57 Safari/537.36',
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Edg/79.0.309.68 Safari/537.36',
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Edg/78.0.276.19 Safari/537.36',
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Edg/77.0.235.9 Safari/537.36',
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Edg/75.0.139.8 Safari/537.36',
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Edg/74.1.96.24 Safari/537.36',
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Edg/73.0.3683.75 Safari/537.36'
]
headers = {
'User-Agent': random.choice(user_agents)
}
time.sleep(random.uniform(0.5, 3)) # 设置访问频率限制
这一步是为了获取一个请求对象,说白了就是模拟一个用户来访问,由此避开百度的反爬机制捏。不过百度这样好爬,也方便了咱们这些初学者学习嘛~
综上,通过随机获取列表里的数值来模拟出随机的访客
获取数据
response = requests.get(url, headers=headers)
soup = BeautifulSoup(response.content, "html.parser")
results = soup.find_all("div", class_="result")
requests.get(url, headers=headers)就是以headers的身份获取链接里面的内容
BeautifulSoup(response.content, “html.parser”)就是提取出内容里面的html部分
soup.find_all(“div”, class_=“result”)就是寻找html里所有class为result的div。
展示数据:
for result in results:
try:
title = result.find("h3").text
link = result.find("a")["href"]
print(title)
print(link)
except:
continue
title = result.find(“h3”).text
link = result.find(“a”)[“href”]
result.find()也就是寻找标签为()里面内容的东西,这里也就不意义赘述了
总代码:
import requests
from bs4 import BeautifulSoup
import random
import time
def searchbaidu(keyword):
url = f"https://www.baidu.com/s?wd={keyword}"
user_agents = [
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Edge/20.10240.16384 Safari/537.36',
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Edg/85.0.564.44 Safari/537.36',
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Edg/80.0.361.109 Safari/537.36',
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Edg/80.0.361.57 Safari/537.36',
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Edg/79.0.309.68 Safari/537.36',
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Edg/78.0.276.19 Safari/537.36',
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Edg/77.0.235.9 Safari/537.36',
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Edg/75.0.139.8 Safari/537.36',
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Edg/74.1.96.24 Safari/537.36',
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Edg/73.0.3683.75 Safari/537.36'
]
headers = {
'User-Agent': random.choice(user_agents)
}
response = requests.get(url, headers=headers)
time.sleep(random.uniform(0.5, 3)) # 设置访问频率限制
soup = BeautifulSoup(response.content, "html.parser")
results = soup.find_all("div", class_="result")
for result in results:
try:
title = result.find("h3").text
link = result.find("a")["href"]
print(title)
print(link)
except:
continue
searchbaidu("python")
调用函数寻找关键字为"python"的内容
结果:
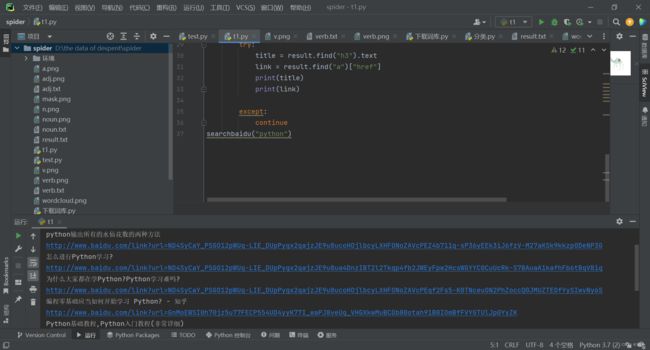
大概就这样了~~