Hive 库表相关操作
1、Hive内部表和外部表
1.内部表:未被external修饰;外部表:被external修饰。
区别:
(1)内部表数据由Hive自身管理,外部表数据由HDFS管理;
(2)内部表数据存储的位置是hive.metastore.warehouse.dir(默认:/user/hive/warehouse), 外部表数据的存储位置由自己制定;
(3)删除内部表会直接删除元数据(metadata)及存储数据;删除外部表仅仅会删除元数据,HDFS上的文件并不会被删除;
对内部表的修改会将修改直接同步给元数据,而对外部表的表结构和分区进行修改,则需要修复(MSCK REPAIR TABLE table_name;)
2.Hive 创建内部表时,会将数据移动到数据仓库指向的路径;若创建外部表,仅记录数据所在的路径,不对数据的位置做任何改变。在删除表的时候,内部表的元数据和数据会被一起删除,而外部表只删除元数据,不删除数据。这样外部表相对来说更加安全些,数据组织也更加灵活,方便共享源数据。
需要注意的是传统数据库对表数据验证是 schema on write(写时模式),而 Hive 在load时是不检查数据是否符合schema的,hive 遵循的是 schema on read(读时模式),只有在读的时候hive才检查、解析具体的数据字段、schema。
读时模式的优势是load data 非常迅速,因为它不需要读取数据进行解析,仅仅进行文件的复制或者移动。
写时模式的优
势是提升了查询性能,因为预先解析之后可以对列建立索引,并压缩,但这样也会花费要多的加载时间。
2、库表操作
1、库操作
show databases;
hive 的表存放位置模式是由 hive-site.xml 当中的一个属性指定的,默认是存放在该配置文件设置的路径下,也可在创建数据库时单独指定存储路径。
hive.metastore.warehouse.dir /user/hive/warehouse
1、创建数据库
create database if not exists test_001; use test_001; 创建数据库并指定位置 create database test_002 location '/user/hive/warehouse/test.db';
2、删除数据库
删除一个空数据库,如果数据库下面有数据表,那么就会报错
drop database test_003; 强制删除数据库,包含数据库下面的表一起删除(请谨慎操作) drop database test_003 cascade;
2、表操作
1、建语句格式说明
[]里的属性为可选属性,不是必须的,但是如果有可选属性,会使 sql 语句的易读性更好,更标准与规范。
例如:[comment '字段注释信息'][comment '表的描述信息']等,[external]属性除外
CREATE [EXTERNAL] TABLE [IF NOT EXISTS] table_name( column_name data_type [comment '字段注释信息'] column_name data_type [comment '字段注释信息'] ... [comment '表的描述信息'] [PARTITIONED BY(column_name data_type, ...)] [CLUSTERED BY (column_name, column_name, ...) [SORTED BY(col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS] [ROW FORMAT row_format] [STORED AS file_format] [LOCATION '指定表在 hdfs 中的存储路径'] )
1. CREATE TABLE
创建一个指定名字的表,如果相同名字的表已存在,则抛出异常提示:表已存在,使用时可以使用IF NOT EXISTS语句来忽略这个异常。
如果创建的表名已存在,则不会再创建,也不会抛出异常提示:表已存在。否则则自动创建该表。
2. EXTERNAL
顾名思义是外部的意思,此关键字在建表语句中让使用者可以创建一个外部表,如果不加该关键字,则默认创建内部表。
外部表在创建时必须同时指定一个指向实际数据的路径(LOCATION),Hive在创建内部表时,会将数据移动到数据仓库指向的路径;
若创建外部表,仅记录数据所在的路径,不对数据的位置作任何改变。
内部表在删除后,其元数据和数据都会被一起删除。
外部表在删除后,只删除其元数据,数据不会被删除。
3. COMMENT
用于给表的各个字段或整张表的内容作解释说明的,便于他人理解其含义。
4. PARTITIONED BY
区分表是否是分区表的关键字段,依据具体字段名和类型来决定表的分区字段。
5. CLUSTERED BY
依据column_name对表进行分桶,在 Hive 中对于每一张表或分区,Hive 可以通过分桶的方式将数据以更细粒度进行数据范围划分。Hive采用对列值哈希,然后除以桶的个数求余的方式决定该条记录存放在哪个桶当中。
6. SORTED BY
指定表数据的排序字段和排序规则,是正序还是倒序排列。
7. ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
指定表存储中列的分隔符,这里指定的是'\t',也可以是其他分隔符。
8. STORED AS SEQUENCEFILE|TEXTFILE|RCFILE
指定表的存储格式,如果文件数据是纯文本格式,可以使用STORED AS TEXTFILE,如果数据需要压缩,则可以使用STORED AS SEQUENCEFILE。
9. LOCATION
指定 Hive 表在 hdfs 里的存储路径,一般内部表(Managed Table)不需要自定义,使用配置文件中设置的路径即可。
如果创建的是一张外部表,则需要单独指定一个路径。
2、Hive创建表的三种方式
1. 使用create table语句创建表
例子:
create table if not exists `t_student`(
id int,
s_name string,
s_age int)
partitioned by(date string)
row format delimited fields terminated by '\t';
2. 使用create table ... as select...语句创建表
例子:
create table sub_student as select * from t_student;
使用 create table ... as select ...语句来创建新表sub_student,此时sub_student 表的结构及表数据与 t_student 表一模一样,相当于直接将 t_student 的表结构和表数据复制一份到 sub_student 表。
注意:
(1). select 中选取的列名(如果是 * 则表示选取所有列名)会作为新表 sub_student 的列名。
(2). 该种创建表的方式会改变表的属性以及结构,例如不能是外部表,只能是内部表,也不支持分区、分桶。
如果as select后的表是分区表,并且使用select *,则分区字段在新表里只是作为字段存在,而不是作为分区字段存在。
在使用该种方式创建时,create 与 table 之间不能加 external 关键字,即不能通过该种方式创建外部目标表,默认只支持创建内部目标表。
(3). 该种创建表的方式所创建的目标表存储格式会变成默认的格式textfile。
3.使用like语句创建表
例子:
create table sub1_student like t_student;
注意:
(1). 只是将 t_student 的表结构复制给 sub1_student 表。
(2). 并不复制 t_student 表的数据给 sub1_student 表。
(3). 目标表可以创建为外部表,即:
create external table sub2_student like t_student;
3、建表和数据加载实战
1、准备文件
E:\hadoop\local\t_user.txt
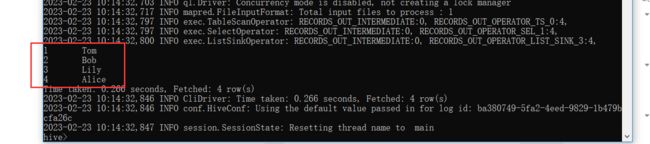
1,Tom 2,Bob 3,Lily 4,Alice
2、建库 建表
create database test2;
use test2;
select current_database();
create table test_user(
id int,
name string
)
row format delimited
fields terminated by ','
lines terminated by '\n'
stored as textfile;
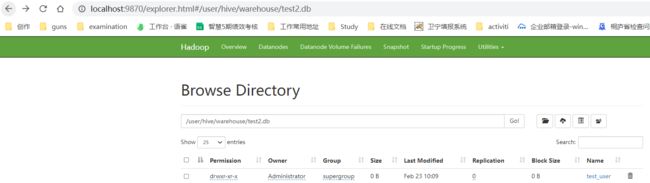
可以看到库表已经建立成功
http://localhost:9870/explorer.html#/user/hive/warehouse/test2.db
3、文件导入的几种方式
1、使用hdfs命令将本地数据文件上传至hdfs中我们创建的数据库下面的表目录下面:
到hadoop sbin下执行
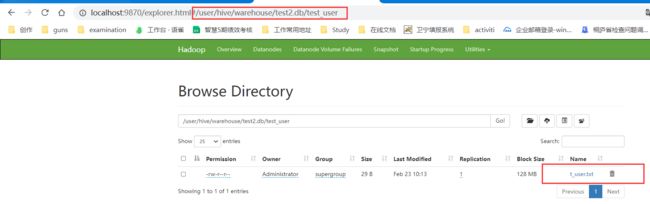
hdfs dfs -put E:\hadoop\local\t_user.txt /user/hive/warehouse/test2.db/test_user

这个目录我们可以从HDFS ui上找到我们的表对应的目录直接拷贝:
上传好之后我们刷新ui界面,可以看到已上传的数据文件:
回到hive客户端查询数据:
select * from test_user;
2、直接在hive客户端将linux系统本地文件上传至hive中:
load data local inpath 'E:\hadoop\local\t_user.txt' into table test_user;
hive> load data local inpath '/root/t_user.txt' into table test_user; #在使用metastore的方式启动hive服务时,如果你是从hive客户端linux文件系统中上传文件,就加上local,如果是从hdfs的文件系统中上传数据文件,就不需要加local,inpath后面的路径参数就是你要上传的文件的路径,这个路径可以是相对路径也可以是绝对路径,但是如果你写相对路径,要特别注意这个相对路径是相对于你当前进入hive时所在的位置,也就是你从哪个路径的位置登创建的hive session,那么相对路径就是从这个位置算起的。 #如果使用hiveserver2/beeline的方式启动hive服务,那么上面的语句中的local指的就是hive服务端的文件系统了,对应的inpath后面的路径也应该是hive服务端中的文件路径。 #load data local inpath '/root/t_user.txt' overwrite into table test_user; #如果表是已经存在的,且表中有数据,那么你在上传数据文件时可以加上overwrite来表示重写表中的数据,如果不写overwrite,则上传的数据会在表中原数据基础上进行追加。
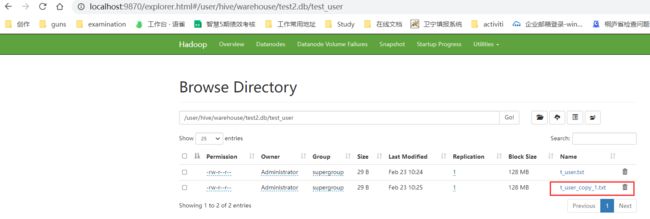
由于这里我没有加上overwrite参数,所以在使用了方式一导入数据之后,这次再导入数据就相当于是追加数据:

刷新ui也可以看到多了一个copy_1的文件,因为两次上传的文件名相同:
上述两种方式中,如果是将linux文件系统中的数据上传至hive时,本质是将linux文件系统中的数据文件拷贝一份放在hdfs的表目录下面,如果是将hdfs文件系统中的数据文件上传至hive时,本质是将hdfs文件系统中的该数据文件移动至hdfs的表目录下面。注意,一个是拷贝,一个是移动。
3、将其他表中的数据导入至目标表中
上述两种方式中一直在使用的是test_user这个表,现在再建一个新表
create table test_user_new(
id int,
name string
)
row format delimited
fields terminated by ','
lines terminated by '\n'
stored as textfile;
hive 然后将test_user表中的数据插入到test_user_new表中:
insert into table test_user_new select * from test_user;
这里还支持:不一一解释了
- 同时向多张表中插入数据
- 将表中的特定列数据插入至另一个表中
- 克隆表数据
会将test_user表结构及表中的数据全部克隆过来
create table test_user_clone as select * from test_user;
- 克隆表结构
使用like关键字,只会克隆表结构,不会将数据也克隆过来
create table test_user_structure like test_user;