近期关于Transformer结构有潜力的改进方法总结
目录
- 0 引言
- 1 Gated Linear Unit (GLU)
-
- 1.1 思路
- 2 Gated Attention Unit (GAU)
-
- 2.1 思路
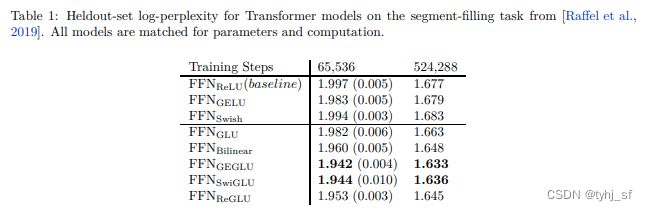
- 2.2 实验结论
- 2.3 混合注意力
- 3 FlashAttention
-
- 3.1 标准Attention的实现
- 3.2 FlashAttention的实现
-
- 针对目标1
- 针对目标2
- 4 总结
- 5 参考资料
0 引言
标准Transformer在最新的实际大模型中并没有被采用了,而是使用其相关的改进版本,原因是标准Transformer的实现有比较显著的缺点:
- Attention的时间复杂度较高,为 O ( n 2 ) O(n^2) O(n2),导致输入token序列长度较无法设置得过大。
- 显存占用大,是因为Attention、多头、FFN导致的参数量大。
以下总结了几个较受关注及个人认为比较有潜力的改进,帮助快速了解,同时推荐大家仔细研读原论文。
1 Gated Linear Unit (GLU)
论文:GLU Variants Improve Transformer,2020.2
1.1 思路
GLU主要是改进并替换掉Transformer结构中的FFN层,Attention层并没有变化。
标准的FFN是两层MLP:
O = ϕ ( X W u ) W o O = \phi (XW_u) W_o O=ϕ(XWu)Wo
其中 X ∈ R n × d , W u ∈ R d × e , W o ∈ R e × d X \in \R^{n \times d},W_u\in \R^{d \times e},W_o\in \R^{e \times d} X∈Rn×d,Wu∈Rd×e,Wo∈Re×d, ϕ \phi ϕ为激活函数,通常是ReLU。
GLU将FFN的两个参数矩阵拆分成了三个参数矩阵,其形式为:
U = ϕ u ( X W u ) V = ϕ v ( X W v ) O = ( U ⊙ V ) W o \begin{equation} \begin{split} U &= \phi_u (XW_u) \\ V &= \phi_v (XW_v) \\ O &= (U \odot V) W_o \end{split} \end{equation} UVO=ϕu(XWu)=ϕv(XWv)=(U⊙V)Wo
其中 U ∈ R d × e , V ∈ R d × e U\in \R^{d \times e},V\in \R^{d \times e} U∈Rd×e,V∈Rd×e, ϕ \phi ϕ为激活函数( U , V U,V U,V是否带激活函数是可选项,并且激活函数也可选择不同的), ⊙ \odot ⊙是对应位置元素相乘(Hadamard 积)。使用了GLU代替标准FFN的效果更好,并为后来的 mT5 所用。
论文中, U , V U,V U,V是否带激活函数 ϕ \phi ϕ是可选项,并且激活函数也可选择不同的。作者给出几种GLU变体组合: U U U不加激活函数, V V V的激活函数分别选择Sigmoid、ReLU、GELU、Swish、缺省等情况。并做了实验表明 V V V的激活函数选择GELU、Swish时效果较其他几种更好,实验结果如下图。
一般情况下的GLU是 U U U不加激活函数,而 V V V加Sigmoid,但这篇论文的代码实现中 U , V U,V U,V都加了激活函数Swish(也叫 SiLU,Sigmoid Linear Unit)。
2 Gated Attention Unit (GAU)
论文:Transformer Quality in Linear Time,Google Research, 2022.1
开源实现(非官方):https://github.com/lucidrains/FLASH-pytorch
论文中提出了一个新的模型代替Transformer,命名为 FLASH:Fast Linear Attention with a Single Head
2.1 思路
虽然GLU论文通过实验证明很有效,但是它并不能取代Attention,因为它的各个token之间没有进行交互,即矩阵 U , V U,V U,V的每一行都是独立运算的。所以GAU想办法将 U , V U,V U,V与Attention结合,在GLU基础上做出了如下设计:
O = ϕ ( U ⊙ A V ) W o O = \phi (U \odot AV) W_o O=ϕ(U⊙AV)Wo
其中, A ∈ R n × n A\in \R^{n \times n} A∈Rn×n是 Attention 矩阵,负责融合 token 之间的信息。这样输出的 O O O就包含了token之间的交互,原则上可以取代 标准Attention。事实上,可以用只用GAU堆叠实现Transformer,替换其中的Attention和FFN层。
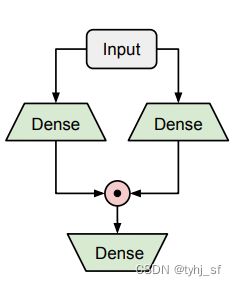
GAU结构示意图如下:

GAU伪代码:

2.2 实验结论
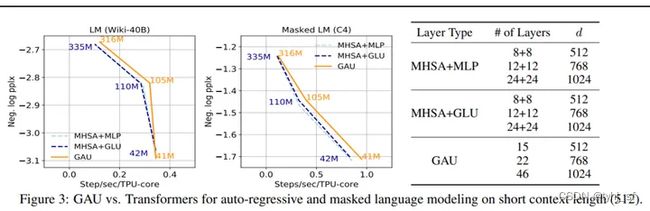
研究者在下图中展示了 GAU 与 Transformers 的比较情况,结果显示对于不同模型大小,GAU 在 TPUs 上的性能可与 Transformers 竞争。需要注意,这些实验是在相对较短的上下文大小(512)上进行的。
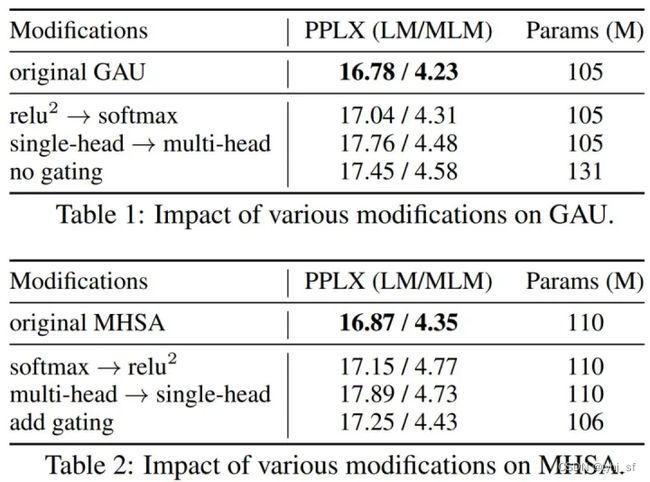
下表 1 和表 2 为层消融实验,结果显示 GAU 和 Transformers 各自都是局部最优的。
研究者从上述实验中得到了以下两个重要的观察结果,并受到启发将 GAU 扩展至建模长序列中。
- 其一,GAU 中的门控机制使得可以使用没有质量损失的更弱的(单头、无softmax)的注意力。如果进一步将这一思路引入到使用注意力建模长序列中,GAU也可以提升近似(弱)注意力机制的有效性,比如局部、稀疏和线性注意力。
- 其二,使用 GAU使注意力模块的数量自然地增加一倍,就开销而言,MLP+MHSA 约等于两个
GAU。由于近似注意力通常需要更多层来捕获完整依赖,因此这一特征使得 GAU 更适宜建模长序列。
2.3 混合注意力
根据现有线性复杂度的优缺点,研究者提出了混合块注意力(mixed chunk attention),它融合了局部二次注意力和块间全局线性注意力的优点。这是使GAU在长序列任务上线性时间内实现Transformer级的性能。具体推导不细讲,可以看一下伪代码。
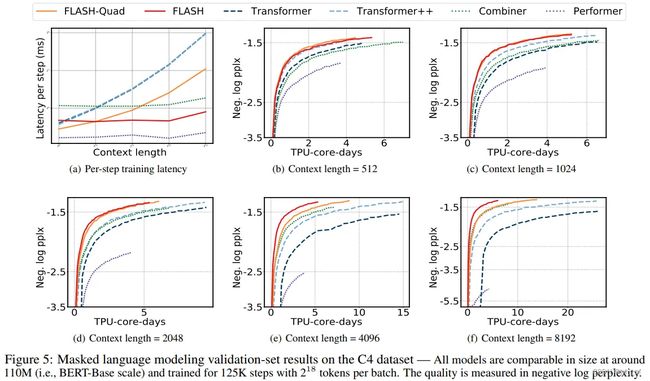
实验效果也不错,对于从512到8192的所有序列长度,FLASH模型总是在相同的计算资源下获得最佳质量(即最低的复杂度)。如下图红色曲线所示。
3 FlashAttention
论文:FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness,2022.5
官方源码:https://github.com/hazyresearch/flash-attention
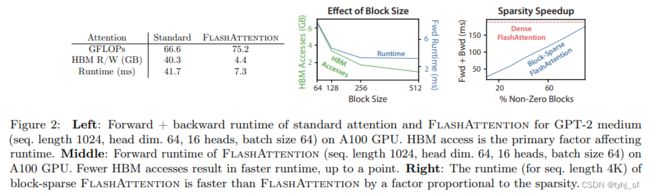
该方法在增加了一定的FLOPs情况下显著节省显存和加速,我们重点关注这个方法。
3.1 标准Attention的实现
在标准的Attention中,Q、K、V作为输入,大小为N×d,如下图所示,在计算中需要存储中间值S和P到显存HBM(High Bandwidth Memory)中,这会极大占用HBM。

3.2 FlashAttention的实现
FlashAttention旨在避免从 HBM中读取和写入注意力矩阵,这需要做到:
目标1:在不访问整个输入的情况下计算softmax函数;
目标2:在后向传播中不能存储中间注意力矩阵。
针对目标1
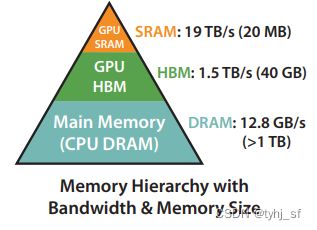
已知SRAM、HBM、DRAM存储容量依次升高,数据IO速度依次降低,如下图所示。那么可以将Q,K,V矩阵划分成多个小的子块,这些子块的大小恰好能从HBM加载进SRAM中,循环将子块传递进SRAM中以增量方式计算出Softmax值。

针对目标2
在后向传播中不存储中间注意力矩阵,以FlashAttention所提供的算法为例,通过对比标准Attention算法在实现过程中,标准Attention算法的实现需要将计算过程中的S、P写入到HBM中,而这些中间矩阵的大小与输入的序列长度有关且为二次型,因此Flash Attention就提出了不使用中间注意力矩阵,通过存储归一化因子来减少HBM内存的消耗。
在Flash Attention的前向计算算法(上图 Algorithm 2中)中我们可以看出,Flash Attention算法并没有将S、P写入HBM中去,而是通过分块写入到HBM中去,存储前向传递的 softmax 归一化因子,在后向传播中快速重新计算片上注意力,这比从HBM中读取中间注意力矩阵的标准方法更快。
优点是:即使由于重新计算导致FLOPs增加,但其运行速度更快并且使用更少的内存(序列长度线性),主要是因为大大减少了 HBM 访问量。实验对比如下图。
4 总结
- MLM类模型中测试显示,在序列较短的情况下,GAU没什么优势,但是序列长度较长(超过512),GAU更省显存并且更快。
- FlashAttention是在考虑不同存储IO速度的情况下对标准Attention中的Softmax进行分块计算,算是一种动态规划的方法。这是一种加速和减少显存占用的方法,并没有改变Transformer的结构。这可以用来大幅增加token序列长度而不显著地增加显存占用和降低推理速度,该方法已经获得广泛关注,可以在一些新近实现的开源模型代码中看见该方法的应用。
5 参考资料
[1]. https://xiaosheng.run/2022/05/16/glu-to-gau.html
[2]. https://zhuanlan.zhihu.com/p/618533434
[3]. FLASH:可能是近来最有意思的高效Transformer设计,苏剑林