pySCENIC单细胞转录因子分析更新:数据库、软件更新
***pySCENIC全部往期精彩系列:
1、PySCENIC(一):python版单细胞转录组转录因子分析
2、PySCENIC(二):pyscenic单细胞转录组转录因子分析
3、PySCENIC(三):pyscenic单细胞转录因子分析可视化
4、PySCENIC(四):pyscenic结果之差异转录因子分析及其他可视化首先说一句,我们之前也发过R语言版本的SCENIC,但是后来我们感觉容易出错,而且费时,所以就没有再探究过。可是总是有小伙伴喜欢跑R,然后说这里错了,那里找不见,其实我们的帖子写于2022年,但是数据库已经更新了,去官网下载新的数据库,不能无脑跑代码。回到pySCENIC,之前我们写过整个系列4篇帖子,分析可视化都是很完善了。可是近期跑的时候发现在第一步有点问题,要么跑不动,要么出错,怀疑是软件和数据库没有更新的缘故,故而更新一下测试。这个帖子主要有两部分内容。
Section1
首先准备单细胞数据,我们准备了27001个基因6000个细胞的数据:提取表达数据,这些操作和之前的一样,没有区别。
#====================================================================================
# 1、R中提取seurat单细胞counts矩阵
#====================================================================================
setwd("D:/KS项目/公众号文章/pySCENIC更新")
library(Seurat)
dim(uterus)
# [1] 27001 27914
table(uterus$orig.ident)
# AEH EEC HC
# 9525 12033 6356
#对于每个样本抽取2000个细胞进行分析,这里只是演示,太多细胞没有意义,也是为了降低文件大小
Idents(uterus) <- 'orig.ident'
sce_test <- subset(x = uterus, downsample = 2000)
table(sce_test$orig.ident)
# AEH EEC HC
# 2000 2000 2000
table(sce_test$celltype)
# Ciliated epithelial cells Endothelial cells Lymphocytes
# 427 631 2844
# Macrophages Smooth muscle cells Stromal fibroblasts
# 110 474 593
# Unciliated epithelial cells
# 921
dim(sce_test)#我们用这6000个细胞进行演示
# [1] 27001 6000
#提取表达矩阵,用于后续分析
Idents(sce_test) <- 'celltype'
write.csv(t(as.matrix(sce_test@assays$RNA@counts)),file = "sce_exp.csv")
saveRDS(sce_test, file = 'sce_test.rds')
我们这次干脆一不做二不休,将之前的pyscenic的环境删除干净,重新建立环境,重新下载最新版软件pyscenic0.12.1好了。准备的数据集也用最新的。数据库网址:cisTarget databases,需要什么自己下载选择即可。
#删除之前的环境,重新建立环境并下载软件
conda info --envs
conda env remove -n pyscenic
#创建环境
conda create -y -n pyscenic python=3.7
conda activate pyscenic
pip install pyscenic -i http://pypi.douban.com/simple/ --trusted-host pypi.douban.com
pip install scanpy -i http://pypi.douban.com/simple/ --trusted-host pypi.douban.com
#需要的数据库下载
#1、Databases ranking the whole genome :https://resources.aertslab.org/cistarget/databases/
#我这里是人的:#需要下载什么。自己实际选择
wget https://resources.aertslab.org/cistarget/databases/homo_sapiens/hg38/refseq_r80/mc_v10_clust/gene_based/hg38_10kbp_up_10kbp_down_full_tx_v10_clust.genes_vs_motifs.rankings.feather
#2、Motif to TF annotations database
wget https://resources.aertslab.org/cistarget/motif2tf/motifs-v10nr_clust-nr.hgnc-m0.001-o0.0.tbl
#3、A list of transcription factors
wget https://resources.aertslab.org/cistarget/tf_lists/allTFs_hg38.txt
这是所有软件版本

image.png
分析的话很好办,还是和之前一样,标准的3步。第一步我们花了大概12多小时。后面的步骤就比较快了。运行是没有任何问题。甚至最后的结果loom文件我们用之前的R可视化代码直接“闭眼”运行,没有任何问题,所以在这里出问题的小伙伴,考虑下自己数据的问题,软件的问题。
pyscenic grn --num_workers 10 \
--sparse \
--method grnboost2 \
--output grn.csv \
sce.loom \
allTFs_hg38.txt
pyscenic ctx --num_workers 10 \
--output regulons.csv \
--expression_mtx_fname sce.loom \
--mode "custom_multiprocessing" \
--motifs-v10nr_clust-nr.hgnc-m0.001-o0.0.tbl\
grn.csv \
hg38_10kbp_up_10kbp_down_full_tx_v10_clust.genes_vs_motifs.rankings.feather
pyscenic aucell --num_workers 6 \
--output sample_SCENIC.loom \
sce.loom \
regulons.csv
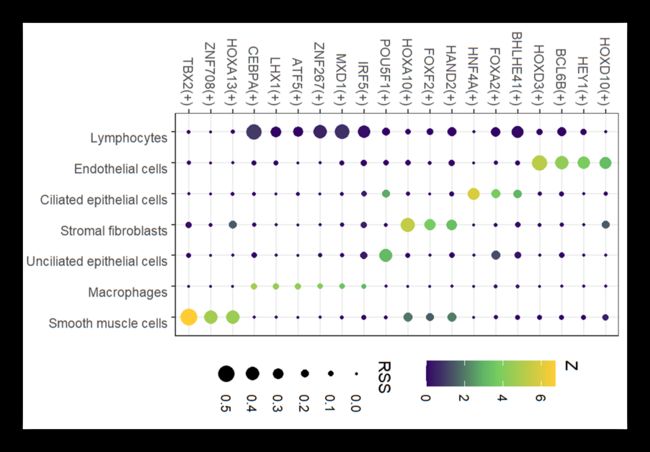
image.png
到这里我们还想探讨一个问题,那就是第一步为什么那么慢,如果仔细了解过的话都知道,第一步的目的是推断转录因子与提供的表达矩阵基因的共表达模块,所以慢就是因为基因多,所以前面我们第一步就是因为运行了所有的基因。这里我们测试了两个数据,一个是1000个基因1500个细胞,一个是1000个6000个细胞,发现运行时间是一样的。
#一个比对
#1000个基因1500个细胞的运行时间
2023-05-30 09:06:44,608 - pyscenic.cli.pyscenic - INFO - Loading expression matrix.
2023-05-30 09:06:44,765 - pyscenic.cli.pyscenic - INFO - Inferring regulatory networks.
2023-05-30 09:09:02,645 - pyscenic.cli.pyscenic - INFO - Writing results to file.
#1000个基因6000个细胞的运行时间
2023-05-30 09:32:42,268 - pyscenic.cli.pyscenic - INFO - Loading expression matrix.
2023-05-30 09:32:42,531 - pyscenic.cli.pyscenic - INFO - Inferring regulatory networks.
2023-05-30 09:35:03,436 - pyscenic.cli.pyscenic - INFO - Writing results to file.
所以我们建议在运行之前,可以对基因进行过滤,例如只有几个细胞表达的基因,或者大多数细胞表达为0的基因可以过滤后在进行分析,因为这些基因没有实质的意义和贡献,对于数据的分析结果也没有影响,还能提高效率。这个思路我认为是没有什么问题的。
Section2
Section1的方式我们之前的帖子说过,相信很多小伙伴已经了解掌握了,只需要更新数据库和软件即可。那么这一部分我们增加的是利用docker镜像进行pyscenic分析。关于docker这里不展开说,可以自行百度。其实爱学习的小伙伴在pyscenic官网的步骤中已经看到了作者讲的,docker镜像分析的步骤。docker的一个优势是速快稍微快一点,不容易出错,我们也测试了,好像是快那么一点。docker的安装需要root权限,所以不懂linux的小伙伴最好不要动,因为sudo很容易搞坏电脑。如果是服务器,一般共享的也没root权限。docker的安装可联系管理员。本地的linux子系统当然是可以安装的。
#安装docker,需要root权限
# 参考:
# 知乎:https://zhuanlan.zhihu.com/p/433898505
# docker官网:https://docs.docker.com/engine/install/ubuntu/
sudo apt-get update
sudo apt-get install ca-certificates curl gnupg
sudo install -m 0755 -d /etc/apt/keyrings
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo gpg --dearmor -o /etc/apt/keyrings/docker.gpg
sudo chmod a+r /etc/apt/keyrings/docker.gpg
echo \
"deb [arch="$(dpkg --print-architecture)" signed-by=/etc/apt/keyrings/docker.gpg] https://download.docker.com/linux/ubuntu \
"$(. /etc/os-release && echo "$VERSION_CODENAME")" stable" | \
sudo tee /etc/apt/sources.list.d/docker.list > /dev/null
sudo apt-get update
sudo apt-get install docker-ce docker-ce-cli containerd.io docker-buildx-plugin docker-compose-plugin
docker --help
# Usage: docker [OPTIONS] COMMAND
#
# A self-sufficient runtime for containers
#
# Common Commands:
# run Create and run a new container from an image
# exec Execute a command in a running container
# ps List containers
# build Build an image from a Dockerfile
# pull Download an image from a registry
# push Upload an image to a registry
# images List images
# login Log in to a registry
sudo service docker start
service docker status
安装好docker后,我们就可以下载pyscenic了。
#docker安装最新版pyscenic
sudo docker pull aertslab/pyscenic:0.12.1
# sudo: /etc/sudoers.d is owned by uid 1000000, should be 0
# [sudo] password for tq_ziv:
# 0.12.1: Pulling from aertslab/pyscenic
# 1efc276f4ff9: Pull complete
# 126aaa6587b8: Pull complete
# 0dd06b55ca68: Pull complete
# 3950cece0b72: Pull complete
# a4cc5c9d5acb: Pull complete
# bdf10448670a: Pull complete
# 6c5350e3d2c5: Pull complete
# Digest: sha256:0c06b8b0a00117e1a4b61303e9ad775bf53c9e410d4c344151c15bf0d143a288
# Status: Downloaded newer image for aertslab/pyscenic:0.12.1
# docker.io/aertslab/pyscenic:0.12.1
# pySCENIC CLI version + ipython kernel + scanpy.
docker pull aertslab/pyscenic_scanpy:0.12.1_1.9.1
分析也是基本的三部:
#run pyscenic
#step1
sudo docker run -it --rm \
-v /home/tq_ziv/pyscenic:/pyscenic aertslab/pyscenic:0.12.1 \
pyscenic grn \
--num_workers 10 \
--method grnboost2 \
--output /pyscenic/grn.csv \
--sparse \
/pyscenic/sce.loom \
/pyscenic/allTFs_hg38.txt
#step2
sudo docker run -it --rm \
-v /home/tq_ziv/pyscenic:/pyscenic aertslab/pyscenic:0.12.1 \
pyscenic ctx \
/pyscenic/grn.csv \
/pyscenic/hg38_10kbp_up_10kbp_down_full_tx_v10_clust.genes_vs_motifs.rankings.feather \
--annotations_fname /pyscenic/motifs-v10nr_clust-nr.hgnc-m0.001-o0.0.tbl \
--expression_mtx_fname /pyscenic/sce.loom \
--mode "custom_multiprocessing" \
--output /pyscenic/regulons.csv \
--num_workers 10
#step3
sudo docker run -it --rm \
-v /home/tq_ziv/pyscenic:/pyscenic aertslab/pyscenic:0.12.1 \
pyscenic aucell \
/pyscenic/sce.loom \
/pyscenic/regulons.csv \
-o /pyscenic/sample_SCENIC.loom \
--num_workers 6
这样就完成了,分析结束后按照之前的帖子进行下游的分析和可视化即可。这就是pyscenic的全部内容了。时不时更新下数据库,更新下软件,切记不可拿到别人的代码不思考便运行,不可能顺利拿到结果。觉得分享有用的点个赞、分享一下再走呗!当然了一般的共享服务器是没有root权限的,也不可能用sudo命令进行操作。可以参考我们专属的服务器:专属注册链接:西柚云超算