机器学习--XGBoost(sklearn)
机器学习–XGBoost(sklearn)
XGBoost = eXtreme + GBDT
=eXtreme +(Gradient + BDT)
=eXtreme +Gradient + (Boosting + DecisionTree)
Boosting --> BDT --> GBDT -->XGBoost
提升决策树(BDT,Boosting Decision Tree)

梯度提升决策树(GBDT,Gradient Boosting Decision Tree)

极限梯度提升(XGBoost,eXtreme Gradient Boosting)


XGBoost的实现-sklearn库调用方式及参数解释
XGBoost分类
from xgboost import XGBClassifier
XGBClassifier(max_depth=3, learning_rate=0.1, n_estimators=100, silent=True,objective='binary:logistic', booster='gbtree', n_jobs=1, nthread=None, gamma=0,min_child_weight=1, max_delta_step=0, subsample=1, colsample_bytree=1,colsample_bylevel=1, reg_alpha=0, reg_lambda=1, scale_pos_weight=1,base_score=0.5,random_state=0, seed=None, missing=None, **kwargs)
三种参数
General parameters:参数控制在提升(boosting)过程中使用哪种booster,
常用的booster有树模型(tree)和线性模型(linear model)。
Booster parameters:这取决于使用哪种booster。
Task parameters:控制学习的场景,例如在回归问题中会使用不同的参数控制排序。
通用参数
这些参数用来控制XGBoost的宏观功能。
- booster[默认gbtree],选择每次迭代的模型,有两种选择:gbtree:基于树的模型和gbliner:线性模型
- silent[默认0],当这个参数值为1时,静默模式开启,不会输出任何信息。
3、nthread[默认值为最大可能的线程数] 用来进行多线程控制,应当输入系统的核数。
booster参数.
尽管有两种booster可供选择,这里只介绍tree booster,因为它的表现远远胜过linear booster,所以linear booster很少用到。
- learning_rate[默认0.1] 和GBM中的learning
rate参数类似。通过减少每一步的权重,可以提高模型的鲁棒性。典型值为0.01-0.2。 - min_child_weight[默认1] 决定最小叶子节点样本权重和。和GBM的 min_child_leaf 参数类似,但不完全一样。
XGBoost的这个参数是最小样本权重的和,而GBM参数是最小样本总数。
值越大,越容易欠拟合;值越小,越容易过拟合(值较大时,避免模型学习到局部的特殊样本)。 - max_depth[默认6] 为树的最大深度。值越大,越容易过拟合;值越小,越容易欠拟合。典型值:3-10
- max_leaf_nodes 树上最大的节点或叶子的数量。
可以替代max_depth的作用。因为如果生成的是二叉树,一个深度为n的树最多生成n2个叶子。如果定义了这个参数,GBM会忽略max_depth参数。 - gamma[默认0] 在节点分裂时,只有分裂后损失函数的值下降了,才会分裂这个节点。Gamma指定了节点分裂所需的最小损失函数下降值。这个参数的值越大,算法越保守。这个参数的值和损失函数息息相关,所以是需要调整的。
- max_delta_step[默认0] 这参数限制每棵树权重改变的最大步长。如果这个参数的值为0,那就意味着没有约束。如果它被赋予了某个正值,那么它会让这个算法更加保守。通常,这个参数不需要设置。但是当各类别的样本十分不平衡时,它对逻辑回归是很有帮助的。这个参数一般用不到,但是你可以挖掘出来它更多的用处。
- subsample[默认1] 训练每棵树时,使用的数据占全部训练集的比例。默认值为1,典型值为0.5-1减小这个参数的值,算法会更加保守,避免过拟合。但是,如果这个值设置得过小,它可能会导致欠拟合。
- colsample_bytree[默认1] 和GBM里面的max_features参数类似。训练每棵树时,使用的特征占全部特征的比例。默认值为1,典型值为0.5-1。
- colsample_bylevel[默认1] 用来控制树的每一级的每一次分裂,对列数的采样的占比。
- reg_lambda[默认1] 权重的L2正则化项。
- reg_alpha[默认1] 权重的L1正则化项。可以应用在很高维度的情况下,使得算法的速度更快。
- scale_pos_weight[默认1] 在各类别样本十分不平衡时,把这个参数设定为一个正值,可以使算法更快收敛。
学习目标参数
这个参数用来控制理想的优化目标和每一步结果的度量方法。
- objective[默认binary:logistic]
这个参数定义需要被最小化的损失函数。最常用的值有:
binary:logistic 二分类的逻辑回归,返回预测的概率(不是类别)。
multi:softmax 使用softmax的多分类器,返回预测的类别(不是概率)。
在这种情况下,你还需要多设一个参数:num_class(类别数目)。
multi:softprob 和multi:softmax参数一样,但是返回的是每个数据属于各个类别的概率。 - eval_metric[默认值取决于objective参数的取值]
对于有效数据的度量方法。
对于回归问题,默认值是rmse,对于分类问题,默认值是error。
典型值有:
rmse、mae、logloss 负对数似然函数值、error 二分类错误率(阈值为0.5)
merror 多分类错误率、mlogloss 多分类logloss损失函数、auc 曲线下面积 - seed(默认0)
随机数的种子。设置它可以复现随机数据的结果,也可以用于调整参数
属性
- feature_importances_ 给出每个特征的重要性。
方法
- apply(X[, ntree_limit]): 返回每个样本的每棵树的预测叶子索引
- evals_result(): 返回评估结果.
- fit(X[, y]): 训练模型
- get_booster(): 获取此模型的基础xgboost Booster.
- get_params([deep]): 获取参数.
- get_xgb_params(): 获取xgboost类型参数
- predict(X): 返回样本预测结果
- predict_proba(data[, ntree_limit]): 预测每个数据属于给定类的概率
- score(X, y[, sample_weight]): 模型准确率
- set_params(**params) :设定参数.
XGBoost回归
from xgboost import XGBRegressor
XGBRegressor(max_depth=3, learning_rate=0.1, n_estimators=100, silent=True,objective='reg:linear', booster='gbtree', n_jobs=1, nthread=None, gamma=0,min_child_weight=1, max_delta_step=0, subsample=1, colsample_bytree=1,colsample_bylevel=1, reg_alpha=0, reg_lambda=1, scale_pos_weight=1,base_score=0.5, random_state=0, seed=None, missing=None, **kwargs)
属性
- feature_importances_ 给出每个特征的重要性。
用法
- apply(X[, ntree_limit]): 返回每个样本的每棵树的预测叶子索引
- evals_result(): 返回评估结果.
- fit(X[, y]): 训练模型
- get_booster(): 获取此模型的基础xgboost Booster.
- get_params([deep]): 获取参数.
- get_xgb_params(): 获取xgboost类型参数
- predict(X): 返回样本预测结果
- score(X, y[, sample_weight]): 模型准确率
- set_params(**params) :设定参数.
糖尿病分类(XGBoost案例,直接调用sklearn)
from numpy import loadtxt
from xgboost import XGBClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
import pandas as pd
import os
os.environ['KMP_DUPLICATE_LIB_OK']='tree'
#加载数据
dataset = pd.read_csv(r"diabetes.csv") #网上都有。
print(dataset.shape)
x = dataset.iloc[:,0:8]
y = dataset.iloc[:,-1]
#划分数据集
seed = 7
test_size = 0.33
X_train,X_test,y_train,y_test = train_test_split(x,y,test_size=test_size,random_state=seed)
print(X_train.shape,X_test.shape,y_train.shape,y_test.shape)
#创建及训练模型
model = XGBClassifier(n_jobs=-1)
model.fit(X_train,y_train)
#使用训练后的模型对测试集进行预测,并计算预测值与实际之间的acc值
y_pred = model.predict(X_test)
accuracy = accuracy_score(y_test,y_pred)
print("accuracy:{:.2f}".format(accuracy * 100.0))
#使用训练后的模型对测试集进行预测,得到每个类别的预测概率:
y_pred = model.predict(X_test)
print(y_pred)
y_pred_proba = model.predict_proba(X_test)
print(y_pred_proba)
#输出各种特征重要程度
from xgboost import plot_importance
import matplotlib.pyplot as plt
%matplotlib inline
plot_importance(model)
plt.show()
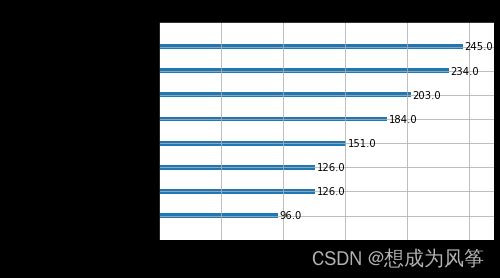
#画出模型树图
from xgboost import plot_tree
_, ax = plt.subplots(figsize=(30, 30))
plot_tree(model, ax=ax)
plt.show()
#调参
from sklearn.model_selection import GridSearchCV
from sklearn.model_selection import StratifiedKFold
#创建模型及参数搜索空间
model_GS = XGBClassifier()
learning_rate = [0.00001,0.001,0.01,0.1,0.2,0.3]
max_depth = [1,2,3,4,5]
param_grid = dict(learning_rate=learning_rate,max_depth=max_depth)
#设置分层抽样验证及创建搜索对象
kflod = StratifiedKFold(n_splits=10,shuffle=True,random_state=seed)
grid_search = GridSearchCV(model_GS,param_grid=param_grid,scoring='neg_log_loss',n_jobs=-1)
grid_result = grid_search.fit(x,y)
y_pred = grid_result.predict(X_test)
accuracy = accuracy_score(y_test,y_pred)
print("accuracy:{:.2f}".format(accuracy * 100.0))
grid_result.best_score_,grid_result.best_params_