UCIe技术——概览索引
一、Chiplet技术概述
chiplet技术顺应了芯片生产与集成技术发展的趋势,也开拓了半导体技术发展的新的发展方向,将创造出一种新的芯片设计和商业模式
1.1 芯片生产与集成技术发展的趋势
(1)低半径高带宽的物理连线(bandwidth / memory wall)
封装技术的进步给高速总线带来带宽密度的提升、摩尔定律(工艺进步推动芯片性能的提升)
(2)数据搬运开销(power wall)
(3)更高晶体管集成度 (dark silicon)
(4)商业模式的进步
降低成本(设计模块化)

1.2 Chiplet技术特征
如图(图片来源于奎芯科技直播课)是已有的一些chiplet技术,当前这些技术针对物理层有明确的规范要求,对协议层定义较模糊,需要定制化地对现有协议作配置

1.2.1 chiplet 接口形式
- 串行接口
传统的serdes架构,利用差分对传输,比较适合普通的基板封装(organic substrate)。
XSR/USR属于串行接口。
- 优势:
1)单lane数据传输率较高,带宽较高,目前以达到112GT/s、224GT/s
2)pin脚需求较小 - 劣势:
1)serdes架构,延迟较大
2)功耗较大
3)低密度route
- 并行接口
单端信号传输,forward clock,适合线距较短的先进封装使用。
AIB、HBM、Open-HBI、LIpincon、BOW、UCIe属于并行总线接口。
- 优势:
1)高密度route,整体布局较紧凑
2)低延时
3)低功耗 - 劣势:
1)为保证多组IO引脚之间延迟移植,数据传输率难以做高
2)IO数量多
1.2.2 chiplet技术优势
1)成本优势
2)die的可复用性,敏捷开发优势
1.2.3 chiplet技术难点
chiplet技术虽然不是一个新的技术,但是在即将大规模应用的当下,仍然有很多工程技术问题要解决。
-
芯粒互连
NoC或interposer上互联、Multi-Die计算体系结构的设计、系统级设计的片间划分、 -
芯片封装
先进封装是否足够可靠:
- 材料种类数量提升,材料物性不匹配
- 聚合物材料的引入恶化了先进封装的失效问题
-
EDA技术
Chiplet模块的DFT、验证、可靠性与DFM,封装设计仿真
Synopsys有最新的3DIC Compiler,这也是行业内第一个完整的Chiplet设计平台,具备360o视角的3D视图,支持2.5D/3D封装设计和实现的自动化和可视化,同时面向供电、发热和噪声进行优化。 -
供电和散热技术
集成规模的增大导致整个芯片功率的增大和供电难,散热成本和散热组件在整个计算系统中的体积占比高 -
测试验证
作为封装内的互联总线,无法像外封装一样通过测量仪器对芯片引出来的引脚进行信号质量检测
1.2.4 chiplet应用案例
-
英特尔:英特尔的Xeon Scalable处理器、FPGA加速器和Ethernet网卡等产品中都使用了UCIe技术。
第五代志强处理器Emerald Rapids -
AMD:AMD的EPYC处理器和Radeon Instinct加速器等产品中也采用了UCIe技术。
参考链接:从AMD CPU IO Die演进看高速接口IP发展趋势 -
NVIDIA:NVIDIA的Tesla加速器和DGX系统中也使用了UCIe技术。
-
Mellanox:Mellanox的InfiniBand和Ethernet互连解决方案中也采用了UCIe技术。
-
华为lego模式
EDA工具链
封装技术的发展
1.3 UCIe技术特征
并行接口,单端传输,直流耦合
线带宽密度:1.317 TB/s/mm
面带宽密度:1.35 TB/s/mm^2
传输速率:2/4/8/12/16/24/32 GT/s
传输延迟:<2 ns (发送端到接收端经过各自的adapter+physical layer的mainband接口的时间差,但不包括信号在有机衬底或者Interposer上的走线延迟)
1.3.1 封装要求
UCIe 1.0协议目前不适用于3D封装,适用于标准封装(2D)和先进封装(2.5D).
(1)标准封装
die直接在有机衬底上进行布局布线,适用于低成本、长线距(10mm ~ 25mm)互联的应用场景,相比封装外serdes互联方式,该方式能提供更好的误码率。


(2)先进封装
Die一般通过interposer或者silicon bridge互连。该封装方式成本较高,应用于更高带宽和更低延迟,能效比更好的场景。
先进封装可参考连接:


1.3.2 UCIe的module配置
- single module
标准封装下数据通道最多为x16,先进封装下数据通道最多为x64。
在设计中可以例化多个single module,每个被例化的single module都可以被独立操作,传输不同的协议

- multi module
该模式下有两种配置方式,分别是双模块和四模块配置。多个模块信号必须传输同一协议,且传输必须同步。
multi module的出现可以理解为扩展data channel的数量

1.3.3 bump pitch
凸块间距
1.3.4 Raw mode
针对UCIe protocol layer的一种数据透传模式,即flit报文中所有字段均由协议层填充,适配层不再填充CRC/FEC/retry等字段。通常用于UCIe retimer的设计,retimer只需完整的传递Flit报文即可,无需添加校验信息等。
用户自定义的协议层也可能会用到该模式
二、协议分析

2.1 协议层(protocol layer)
该层主要做业务协议的例化,将数据转换成Flit包传递到下一层
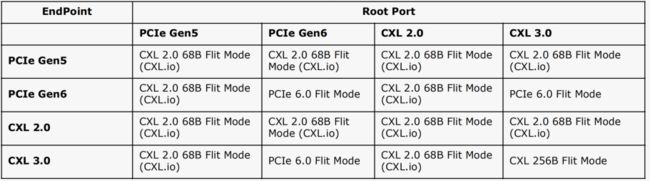
UCIe兼容业务协议包括:
1)PCIe 6.0 Flit模式(256B固定包长)
2)CXL2.0或更新版本,CXL 68B-enhanced定长和256B定长。
CXL.io/memory/cache视为独立的协议栈,详细参考链接:CXL技术分析
CXL.io 68B flit mode 可支持PCIe non-flit mode
3)streaming协议,用于用户使用UCIe的自定义的接口
2.1.1 协议间的协商
2.1.2 PCIe6.0 RAW mode
该模式可选,目标用于UCie retimer的off-package的连接
2.1.3 PCIe6.0 :standard 256B Flit mode
若支持PCie,则该模式必须支持。标准定长格式报文是PCIe6.0协议Flit mode的一部分

2.1.4 CXL3.0 RAW mode:256B Flit mode
该模式可选, 目标用于UCie retimer的off-package的连接,例如用于CPU和外置显卡的连接
2.1.5 CXL3.0:latency-optimized 256B Flit mode
强烈推荐支持该模式,相较于标准CXL3.0协议,该模式下对延迟实现了优化。
CXL.io协议中的Ack、Nak、PM和链路管理的DLLP在UCie 256B Flit mode中不再使用,DLLP和Flit_Marker的定义仍然一样


2.1.6 CXL3.0:standard 256B Flit mode
当支持CXL256B Flit mode时,该模式必须支持。
CXL.io协议中的Ack、Nak、PM和链路管理的DLLP在UCie 256B Flit mode中不再使用,DLLP和Flit_Marker的定义仍然一样

2.1.7 CXL2.0 or 68B-Enhanced Flit Mode:RAW mode
该模式可选,用于目标用于UCie retimer的off-package的连接,例如用于CPU和外置显卡的连接
2.1.8 CXL2.0:68B-Enhanced Flit Mode
当支持CXL2.0 or 68B-Enhanced Flit Mode时,该模式必须支持。
该模式下发送64B的定长报文到FDI,adapter将插入2B的Flit header和2B的CRC。
CXL.io协议中的Ack、Nak、PM的DLLP在该模式下不再使用,credit和其他的DLLP的定义仍然一样(数据重传在Adapter中进行)
CXL.mem/cache协议中定长报文的“AK”域保留了,retry保留但不使用
 如图是该模式下的报文格式,圆圈部分是第一个报文,方框部分是第二个报文。
如图是该模式下的报文格式,圆圈部分是第一个报文,方框部分是第二个报文。
2.1.9 streaming Protocol:RAW mode
若PCIe和CXL均不支持,则必须支持该模式,厂商可自由定义
2.2 适配层(adapter layer)
该层主要功能包括:
- 对protocol layer来的各种协议的报文做仲裁,分时复用
- 实现CRC校验码检测与重传功能,以获得更好误码率
- 实现更高阶的链路状态管理,与对端链路设备进行bring up、协议相关的数据交换
该层与PCIe的链路层类似,但是相较于PCIe,UCIe把链路的参数协商(包括链路训练的TS序列、链路管理报文等)从mainband中摘出来,交由sideband去做
对于接收端,adapter不会把nop flit传递到协议层
2.2.1 多协议仲裁
UCIe允许多个协议栈共同复用同一物理层,
为了解决物理层和RDI接口带宽的速率不匹配,adapter层需要在协议层后面插入一些空报文
2.2.2 链路初始化
在业务数据于mainband通路上传输时,链路初始化包含四个阶段
- sideband通道监测和训练
- mainband训练和修复 RDI状态机一旦进入active状态即该阶段完成
- 双方adapter的参数交换,协议和报文格式协商 定义本地主机的属性,adapter决定物理层训练的结果,更加给定链路速度和配置决定是否数据回传, 对于retimer,adapter还需要决定credits
协商的参数包括15种,对于PCIe/CXL协议来说,DP设备先从sideband发送报文给UP
参数协商一旦完成,adapter将会把协商结果传递给FDI,FDI层将会bring up;一旦FDI进入active状态,链路初始化的阶段三将结束,协议层可以进行业务报文传输
2.3 物理逻辑层(logical physical layer)
PHY layer的架构图如下图所示,主要功能包括:
- mainband数据通路: 负责业务数据的传输
- sideband数据通路: 负责管理类型事务的数据传输,包括链路训练,链路管理等

2.3.1 sideband组信号
sideband组信号每个方向都有一个前向时钟引脚和数据引脚,该部分逻辑必须有备用电源驱动,并始终处于"always on"电压域中。
前向时钟频率固定为800Mhz
优点:
1)减小了mainband协议设计的复杂性
2)增加了mainband的带宽利用率
3)加速链路训练的过程

2.3.2 mainband组信号
每个module的mainband信号包含一个前向时钟信号、一个数据有效信号、N个数据信号。
对于先进封装,N最大可达64,并且有4个额外的引脚用于lane的故障修复
对于标准封装,N最大可达16,无故障修复功能。
链路训练
2.4 物理电气层(electrical physical layer)
2.5 FDI
协议成和适配层的接口。
2.6 RDI
适配层和物理层的接口。
三、架构设计
单package上的通过UCIe互联的计算架构如图所示:

3.1 协议层设计
PCIe兼容模式
若兼容PCie6.0,为了获取更好的面积和功耗效能,PCIe中的non-flit模式相关逻辑、DLLP将不再使用,串行编码的逻辑也不再需要,该部分逻辑均可删除,CXL同理,即使这样如果协议层兼容PCIe或者CXL,协议层的延迟估计要超过10ns或者更多。因此如果需要更低的延迟,则需要用户自定义协议层。
(PCIe3.0事务传输的端到端延迟达200ns左右)
协议层支持的协议模式和Flit格式在SOC集成时固化在硬件中,或者Die bring up时通过寄存器写入配置。
在端到端协商过程中适配层通过FDI接口把这些信息作为Link Training的一部分传给对端协议层。
协议层的不同协议通过各自的FDI接口连接到adapter层,不同协议各自独立协商链路,当对端发来Flit报文时,通过判断Flit_Hdr中的相关Bit分发到对应的协议栈逻辑中。
CXL兼容模式
CXL.io协议中的Ack、Nak、PM和链路管理的DLLP在UCie 256B Flit mode中不再使用,DLLP和Flit_Marker的定义仍然一样
3.2 适配层设计
3.3 物理层设计
参考链接:
Universal Chiplet Interconnect Express (UCIe): An Open Industry Standard for Innovations with Chiplets at Package Level
3.4 应用场景
CPU+CPU
两块CPU不在一块die上,因此不能访问同级缓存,加上UCIe本身的延迟,势必会增大维护一致性的延迟开销,如果进程和内存页不在一个节点上,那么die之间的延迟将导致进程长时间等待,进而CPU空转。
3.5 UCIe retimer
打通封装内互联和片间互联的通路,本质上是将单端的并行信号转换为差分的串行serdes信号。

- 从die发送给retimer的数据是受流控的
- 从retimer发给die的数据是不受流控的,retimer在spec外自身定义的流控机制除外
四、软件架构
- OS驱动
OS层的驱动可以理解为业务驱动和管理驱动。
UCIe的业务驱动基于其协议层寄存器的属性,例如兼容PCIe协议的host downstream的UCIe端口将被软件示为PCIe Rootport设备,连接该端口的upstream port所在的设备可以是PCIe EP设备或者Switch
管理驱动主要对UCIe自身逻辑的adapter和physical层寄存器进行配置,同时功能包括:
- OS通过枚举UCIe查找表(CIDT)注册每个UCIe link的CiRB基地址,CiRB指主机端寄存器组,包含了UCIe link DVSEC(Designated Vendor-Specific Extended Capability)属性寄存器。
- firmware
UCIe的链路训练由固件完成