python 图片识别_python识别图片文字
python识别图片文字
哈喽,大家好呀,我是滑稽君。大家在写论文时可能经常碰到无法复制文字的文章。明明找到了需要的内容却无法直接复制使用,这让我们十分苦恼。那么本期滑稽君就告诉大家如何使用python识别图片中的文字。
滑稽君整理了网上使用率最高的两种方法。
一是pytesseract+Tessseract-OCR进行图片识别。
二是调用百度文字识别提供的API进行图片文字的处理。
下面我将告诉大家这两种方法一些容易跳坑的地方。

视频讲解:
 ❂ pytesseract+Tessseract-OCR
❂ pytesseract+Tessseract-OCR
第一种方法需要注意的地方是一些第三方库的下载,我们需要用到pytesseract库和pillow库,这两个库我们都可以在cmd中直接pip下载,需要注意的是我们还需额外下载一个文件——tesseract-ocr。下载这个文件之后我们直接安装注意不要修改他的默认路径(大神忽略)。一些小伙伴可能需要配置一下环境路径,滑稽君安装之后它自动帮我添加了,大家注意一下即可。
下载链接:
https://pan.baidu.com/s/1OL0g1MBzeijD23JN0UGC0Q这个工具默认支持英文,我们需要下载支持中文的包,然后放在这个目录下。C:\Program Files (x86)\Tesseract-OCR\tessdata 里面已经有了支持英文的包是eng开头的,我们放入的支持中文的包是chi_sim开头的意思是中文简体。
接着我们需要在这个目录下找到图片中的最后一个文件,打开文件(用记事本即可)找到如图所示位置后进行如下修改。这个路径一般是通用的,这也是一开始为什么不修改默认路径的原因。当我们准备工作都完成后代码部分就比较简单了。


源代码:
import pytesseractfrom PIL import Image pytesseract.pytesseract.tesseract_cmd = r"C:\Program Files (x86)\Tesseract-OCR\tesseract.exe"text = pytesseract.image_to_string(Image.open('C:\\Users\\86157\\pysw.png'),lang="eng")#识别英文参数为 lang="eng" 中文为lang="chi_sim" 如果参数不对识别就会乱码。# 创建一个txt文件,文件名为mytxtfile,并向文件写入msgdef text_create(name, msg): desktop_path = "C:\\Users\\86157\\Desktop\\" # 新创建的txt文件的存放路径 full_path = desktop_path + name + '.txt' # 也可以创建一个.doc的word文档 file = open(full_path, 'w') file.write(msg) #msg也就是下面的Hello world! file.close() text_create('saveworld',text)这个方法主要是使用百度文字识别提供的API接口,来完成对图片文字的识别。需要用到baidu-api这个第三方库,cmd中可以直接pip安装。我们需要去百度云免费申请一个百度云文字识别api的接口,获得你自己的APP_ID,API_KEY,SECRET_KEY。
源代码:
#-*- coding: UTF-8 -*-#前提是python已安装aip库--》pip install baidu-aip import osfrom aip import AipOcrimport jsonAPP_ID = '' #你的APP_IDAPI_KEY = '' #你的API_KEYSECRET_KEY = '' #你的SECRET_KEYaipOcr = AipOcr(APP_ID, API_KEY, SECRET_KEY)os.chdir("") #你需要转换的图片目录,大家自行替换。dirs = os.listdir()def get_file_content(filePath): with open(filePath, 'rb') as fp: return fp.read()options = {}options["language_type"] = "CHN_ENG"options["detect_direction"] = "true"options["detect_language"] = "true"options["probability"] = "true" print('开始处理,共'+str(len(dirs))+"张图片。")flag=0T = 0 #统计处理图片成功的数量for filePath in dirs: if filePath.split('.')[-1]=='txt':continue flag+=1 print('正在处理第'+str(flag)+'张图片') try: result = aipOcr.basicGeneral(get_file_content(filePath), options) except BaseException as e: print(e) else: try: with open(filePath.split('.')[0]+'.txt','w',encoding='utf-8') as f: for i in result['words_result']: f.write(i['words']+'\n') T += 1 except BaseException as e : print(e) else: print('处理完成')print('{}全部处理完成!{}'.format("="*30,"="*30))print('处理成功的图片有{}张,处理失败的图片有{}张'.format(T,len(dirs)-T))效果图:
方法一:左边为滑稽君自制的图片,右边为识别之后转txt的效果。
可以看到中文识别正确率还说一点低的。英文识别的效果倒是还可以没有出现错误的情况,这里就不展示了。

方法二:左边为滑稽君自制的图片,右边为识别之后转txt的效果。
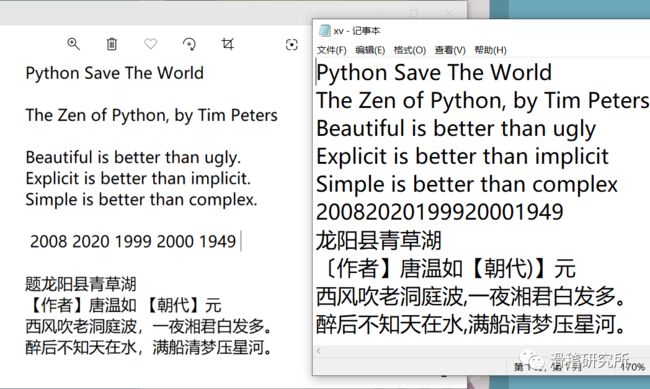
可以看到第一种方法对图片中文字的识别准确率较第二种要差很多,特别是在中文的识别上。因此大家日常使用的话还是推荐第二种方法,还有就是下载安装文件和配置环境变量对小白来说不是那么友好。
第一种方法识别图片中文字,如果图片里有中英混杂的情况,就只能识别一种语言。而调用百度文字API的方法可以英文、中文、数字混合在一张图里识别,并且准确率高。前者可以单机识别,后者则是要求网络的。
本期素材来源:
https://blog.csdn.net/zhangshaohua1603/article/details/79722399https://blog.csdn.net/L141210113/article/details/88835914?utm_medium=distribute.pc_relevant_t0.none-task-blog-BlogCommendFromMachineLearnPai2-1.compare&depth_1-utm_source=distribute.pc_relevant_t0.none-task-blog-BlogCommendFromMachineLearnPai2-1.compare ❂ END
❂ END
两种方法都为大家整理完毕了,有什么问题欢迎私信滑稽君。