基于SpringBoot和Vue的分布式爬虫系统(JavaWeb)
前言
本期案例分享,学长给大家上点干货,手把手带你开发一个分布式爬虫系统。通过这个项目,你将学习到下面几点:
架构设计。如果设计一个通用的爬虫系统?一个系统支持爬取所有的网站。
分布式开发经验。分布式系统开发考虑的点会更多,如何保证代码在多节点部署时还能正确的运行?
多线程开发经验。大量使用了concurrent包中的多线程类,多线程、线程池、锁。结合真实的业务场景教你怎么玩转多线程,跟你平时写的多线程demo是完全不同的。
郑重声明:本项目的出发点是学习和技术分享,项目中出现的爬虫案例也都是互联网上可以公开访问的网站,爬取时严格控制了爬取频率以及爬取速度(单线程去爬取,每爬取一个页面休眠1秒,最多爬取100个页面),绝不会影响目标网站的正常运行。
项目架构
爬虫组件

上面是爬虫系统的经典架构图,简单说下每个组件的职责:
Spiders:每个spider负责处理一个特殊的网站,负责抽取目标网站的数据
Scheduler:调度器从引擎接受request并将他们入队,以便之后引擎请求他们时提供给引擎
Downloader:根据request对象去执行网络下载
Pipeline:负责将spider抽取出来的item数据进行存储,这里我们存储在MySQL
最后我们合起来说明下爬虫流程:
1.首先创建一个spider爬虫任务,这时候会有一个入口URL,spider从这个入口开始爬取
2.调用Downloader组件去执行http请求下载整个页面
3.spider解析页面中的内容,将需要的内容放入item里面,同时将页面中的子URL放入Scheduler组件
4.Pipeline负责将item中的数据就行持久化存储
5.URL放入Scheduler组件,Scheduler组件会对URL进行去重,避免重复爬取
6.spider爬完当前页面后就继续从Scheduler拿URL,如果有URL则继续爬取,没有则说明所有页面都爬完了,spider任务结束
分布式爬虫
什么是分布式爬虫?用大白话来说就是:我部署了多个爬虫模块,这几个模块可以一起来爬虫。从上面架构图的分析,只需要将Scheduler模块基于redis实现,那么所有的模块的spider只需要从redis获取URL,然后爬到新的子URL时也放入redis中,此时我们的架构已经是支持分布式爬虫了。(代码细节较多,文章篇幅有限,不展开细说了)
定制化爬虫
对于一些页面静态化的网站,做了SEO可以直接被搜索引擎爬取的网站、没有做反爬的网站,这些网站我们是可以定制一个通用的爬虫策略来爬取,直接http请求,然后解析内容和图片等资源。而对于一些做了反爬策略的,例如分页的数据、动态渲染的网页、请求头拦截、ip高频拦截等等。对于这类网站的爬虫需要做一些定制化的逻辑,所以在架构设计上,学长提供了一个爬虫订制模板的入口,通过在代码中开发针对具体网站的定制化爬虫策略,这样就可以避开大多数的反爬规则,从而实现一个爬虫系统可以支持绝大多数的网站爬取。
领域模型
DO(DataObject):与数据库表结构一一对应,通过DAO层向上传输数据源对象
BO(BusinessObject):业务对象。由Service层输出的封装业务逻辑的对象
VO(View Object):显示层对象,通常是Web向模板渲染引擎层传输的对象
BO和VO领域模型又分为BoRequest(输入模型)、BoResponse(输出模型)、VoRequest(输入模型)、VoResponse(输出模型)
技术栈
前端:vue + element
后端:jdk1.8 + springboot + redis + mysql + jsoup + httpClient
权限:security+spring-session
接口设计
整个项目接口采用的目前互联网比较流行的restful风格设计,每个接口、每个参数都有详细的文档说明。因为企业中开发必然是团队协作,必然前后端分离的开发模式,你得先把接口定义出来,然后前端可以和后端同步开发。还有一种就是对外提供接口,比如你们隔壁团队也想调用你这个服务的接口,但是你两排期是同一周,这时候你得先把接口定义出来给人家,然后大家同步开发,开发完了之后再进行联调。

运行效果
系统登录
dashboard
实时统计系统数据

任务管理
页面菜单、“查询”、“创建”、“编辑”、“删除”按钮都支持单独的权限分配,这里列举了爬虫案例,“爬取百度新闻”、“爬取必应壁纸”、“爬取当当网书籍信息”、“爬取新浪新闻”
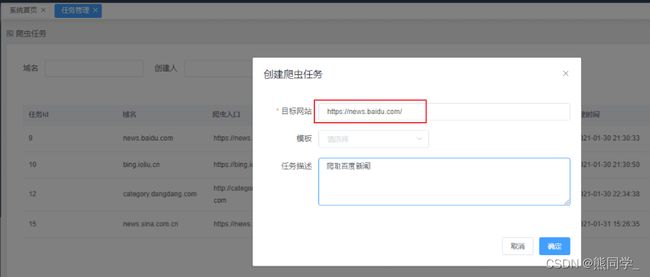
创建爬虫任务
爬取必应壁纸
很多人用必应搜索是因为喜欢必应的高清壁纸(学长就是这样的),这里演示必应壁纸的爬虫。因为必应壁纸涉及分页,这里刚好用到我们的订制模板功能,通过写一个BingTemplate模板,我们可以轻松地搞定分页数据爬虫。
文明爬虫,我们只爬了100页数据,每页的图片都在资源详情里面,非常漂亮,可以点击放大图片并下载


爬取当当网
之前学长在专栏分享过《图书管理系统》,当时为了让内容更真实,从当当网爬取了一些书籍信息,比如书名、作者、出版社、价格、简介等信息。(感兴趣的可以去专栏回顾下图书管理系统的设计和实现)
订制一个当当网的爬虫模板DangDangTemplate,只须一个URL,开始我们的订制爬虫之旅。
爬取百度和新浪新闻
百度新闻和新浪新闻都比较好爬,不需要模板,直接新建任务,只需要填入一个URL,立即开始爬虫。


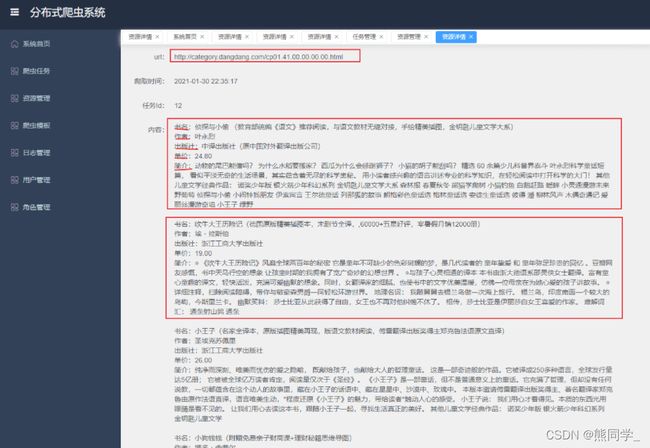
资源管理
所有爬取到的数据都可以在资源管理界面查询到,点击“资源详情”可以看到具体的文本、图片内容,图片支持放大、下载、以及幻灯片播放

模板管理
前面已经说过,对于有反爬策略的网站和定制化的爬虫都可以通过开发一个爬虫模板来实现,这样的设计对系统扩展性是非常好的,等于说一个爬虫系统可以爬取所有的内容。
日志管理
日志管理默认是开给管理员的,在系统中的所有操作都会被记录,在系统出现异常时也便于管理员进行问题排查。
用户管理
默认也是只有管理员拥有用户管理菜单的权限,可以新建/编辑用户、分配用户角色、禁用/启用等操作
编辑用户信息
拥有账号编辑权限的用户可以进行编辑操作
角色管理
默认也是只有管理员拥有角色管理菜单的权限,这里的权限是细粒度到按钮权限的,每个按钮都可以进行权限管理,假如给用户只分配了任务的“查询”权限,但是这个用户是个程序员,他想通过接口请求直接访问任务修改接口,这时候后端是会权限校验的,返回“未授权”的错误码,然后前端根据“未授权”错误码会重定向到一个403页面(这也是为什么说只有前端校验是不安全的,后端也必须得校验,这在实际企业里开发也是这样的,还没有实际开发经验的学弟学妹拿个小本本记一记,哈哈哈)
权限设计
权限基于security和spring-session实现。权限可以分为认证和授权,认证其实就是登录,用户登录时会进行账号密码的校验,校验成功后会,会把session存入redis中。授权指的是用户是否拥有访问后端资源的权限,每个新用户在创建后都会分配角色,角色其实就是一个权限集合,这里的权限可以理解为访问后端一个个接口(资源)的权限。
这里权限设计的非常灵活,细粒度到按钮级别,比如课程菜单的新增、删除、修改、查询动作,学生可能只有课程的查询权限,无法新增和修改课程,即使通过接口直接访问后端的修改或者新增接口,后端也会返回授权失败错误,因为后端每个需要权限的接口都打了权限标识,只有拥有资源权限用户才能访问。
日志方案
日志采用lombok注解+slf4j+log4j2的实现方案,基于profile实现了多环境的日志配置,因为不同环境的日志打印策略是不一样,比如开发环境我可能需要打印到console控制台,需要debug级别的日志以便于本地开发调试,测试环境可能就需要打印到日志文件里,线上环境可能需要打印到文件的同时将日志发送到kafka然后收集到es中,这样当线上部署了多台机器后我们查日志不用一台一台机器去查日志了,因为都收集到es了,我们只需要登录kibana去搜索,这样就非常方便。这里说到的kafka+es+kibana这样一套日志解决方案也是目前互联网公司比较常用的一套解决方案。如果你动手能力够强,你可以本地搭一套kafka、es、kibana,然后只需要在配置文件中加入几行配置就实现了这么一套企业级的日志解决方案(默认是输出到日志文件)。
下面是部分关键配置,如果要配置kafka,只需要在标签中配置配置即可
<?xml version="1.0" encoding="UTF-8"?>
<Configuration status="WARN" xmlns:xi="http://www.w3.org/2001/XInclude">
<Properties>
<Property name="LOG_FILE">system.log</Property>
<Property name="LOG_PATH">./logs</Property>
<Property name="PID">????</Property>
<Property name="LOG_EXCEPTION_CONVERSION_WORD">%xwEx</Property>
<Property name="LOG_LEVEL_PATTERN">%5p</Property>
<Property name="LOG_DATE_FORMAT_PATTERN">yyyy-MM-dd HH:mm:ss.SSS</Property>
<Property name="CONSOLE_LOG_PATTERN">%clr{%d{${LOG_DATE_FORMAT_PATTERN}}}{faint} %clr{${LOG_LEVEL_PATTERN}} %clr{${sys:PID}}{magenta} %clr{---}{faint} %clr{[%15.15t]}{faint} %clr{%-40.40c{1.}}{cyan} %clr{:}{faint} %m%n${sys:LOG_EXCEPTION_CONVERSION_WORD}
</Property>
<Property name="FILE_LOG_PATTERN">%d{${LOG_DATE_FORMAT_PATTERN}} ${LOG_LEVEL_PATTERN} ${sys:PID} --- [%t] %-40.40c{1.}:%L : %m%n${sys:LOG_EXCEPTION_CONVERSION_WORD}
</Property>
</Properties>
<Appenders>
<xi:include href="log4j2/file-appender.xml"/>
</Appenders>
<Loggers>
<logger name="com.senior.book" level="info"/>
<Root level="info">
<AppenderRef ref="FileAppender"/>
</Root>
</Loggers>
</Configuration>
服务监控
服务监控基于 Actuator + Prometheus + Grafana 实现,代码侵入很小,只需要在pom中加入依赖。数据大盘Dashboard可以自己设置,也可以去Dashboard市场下载你想要的模板,总之,这块完全是看动手能力,大家自己玩吧~~~
<!--服务监控-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
<dependency>
<groupId>io.micrometer</groupId>
<artifactId>micrometer-registry-prometheus</artifactId>
</dependency>

感兴趣的可以联系:
q2680555242