PostgreSql根据给的时间范围统计15分钟粒度、小时粒度、天粒度、周粒度、月粒度工单
PostgreSql根据给的时间范围统计15分钟粒度、小时粒度、天粒度、周粒度、月粒度工单
- 说明
- 实现
-
- 15分钟粒度工单统计
- 小时粒度工单统计
- 天粒度工单统计
- 周粒度工单统计
- 月粒度工单统计
说明
项目有个需求是统计故障工单每15分钟、每小时、每天、每周和每月共有多少工单。
这里先做个笔记,怕以后忘记怎么使用。
如果不知道generate_series()函数用法,可以参考我的这篇博客进行了解:数据库(postgresql和mysql)统计一个范围内的日期,没有当天日期的数据统计补0
实现
这里只统计2022-10-27那一天的数据,可以看到这天一共有160条数据。

然后我们根据时间分组看看,每个时间段都有多少数据,可以看到我们表中的时间格式是yyyy-MM-dd HH24:mi:ss这种年月日时分秒的格式。数据库表里面create_time类型为timestamp。
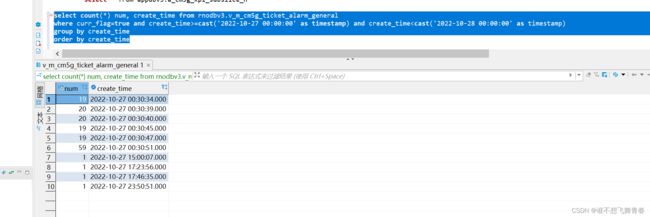
15分钟粒度工单统计
在实际开发中,我们就只需要传一个开始时间和结束时间这2个参数就行。
代码中只有2个参数,一个#{startTime}代表开始时间,一个#{endTime}代表结束时间,代码里面传给mybatis的时间类型为String字符串,格式为yyyy-MM-dd或者yyyy-MM-dd HH24:mi:ss都行,因为这里有用cast将时间格式转为timestamp(yyyy-MM-dd HH24:mi:ss)这种类型。
原mybatis中sql代码:
select '故障' type,c.date,
coalesce(d.order_num,0) order_num,
coalesce(d.archived_num,0) archived_num,
coalesce(d.timeout_soon_num,0) timeout_soon_num,
coalesce(d.no_timeout_num,0) no_timeout_num,
coalesce(d.order_inprogress,0) order_inprogress,
coalesce(d.order_overtime,0) order_overtime
from
(select to_char(t,'yyyy-MM-dd HH24:mi:00') date
from generate_series(cast(#{startTime} as timestamp),cast(#{endTime} as timestamp),'15 minute') t) c
left join
(select to_char(b.starttime,'yyyy-MM-dd HH24:mi:00') date,
count(distinct a.ticket_id) order_num,
count(distinct case when a.ticket_status ='已归档' then a.ticket_id end) archived_num,
count(distinct case when a.ticket_status !='已归档' and a.is_time_out !='是' and a.timeout_soon =true then a.ticket_id end) timeout_soon_num,
count(distinct case when a.is_time_out !='是' then a.ticket_id end) no_timeout_num,
count(distinct case when a.ticket_status !='已归档' then a.ticket_id end) order_inprogress,
count(distinct case when a.ticket_status !='已归档' and a.is_time_out ='是' then a.ticket_id end) order_overtime
from rnodbv3.v_m_cm5g_ticket_alarm_general a
left join
(select t as starttime ,t +'15 minute' as endtime
from generate_series(cast(#{startTime} as timestamp),cast(#{endTime} as timestamp),'15 minute') t
) b on a.create_time >=b.starttime and a.create_time <b.endtime
where a.curr_flag=true
and a.create_time>=cast(#{startTime} as timestamp) and a.create_time<cast(#{endTime} as timestamp)+interval '15 minute'
group by b.starttime
order by b.starttime) d on c.date=d.date
sql实际执行结果:
这里将ticket_id前的distinct去重删除是为了给你们方便比对统计结果是不是160条。
select '故障' type,c.date,
coalesce(d.order_num,0) order_num,
coalesce(d.archived_num,0) archived_num,
coalesce(d.timeout_soon_num,0) timeout_soon_num,
coalesce(d.no_timeout_num,0) no_timeout_num,
coalesce(d.order_inprogress,0) order_inprogress,
coalesce(d.order_overtime,0) order_overtime
from
(select to_char(t,'yyyy-MM-dd HH24:mi:00') date
from generate_series(cast('2022-10-27 00:00:00' as timestamp),cast('2022-10-27 23:45:00' as timestamp),'15 minute') t) c
left join
(select to_char(b.starttime,'yyyy-MM-dd HH24:mi:00') date,
count(a.ticket_id) order_num,
count(distinct case when a.ticket_status ='已归档' then a.ticket_id end) archived_num,
count(distinct case when a.ticket_status !='已归档' and a.is_time_out !='是' and a.timeout_soon =true then a.ticket_id end) timeout_soon_num,
count(distinct case when a.is_time_out !='是' then a.ticket_id end) no_timeout_num,
count(distinct case when a.ticket_status !='已归档' then a.ticket_id end) order_inprogress,
count(distinct case when a.ticket_status !='已归档' and a.is_time_out ='是' then a.ticket_id end) order_overtime
from rnodbv3.v_m_cm5g_ticket_alarm_general a
left join
(select t as starttime ,t +'15 minute' as endtime
from generate_series(cast('2022-10-27 00:00:00' as timestamp),cast('2022-10-27 23:45:00' as timestamp),'15 minute') t
) b on a.create_time >=b.starttime and a.create_time <b.endtime
where a.curr_flag=true
and a.create_time>=cast('2022-10-27 00:00:00' as timestamp) and a.create_time<cast('2022-10-27 23:45:00' as timestamp)+interval '15 minute'
group by b.starttime
order by b.starttime) d on c.date=d.date
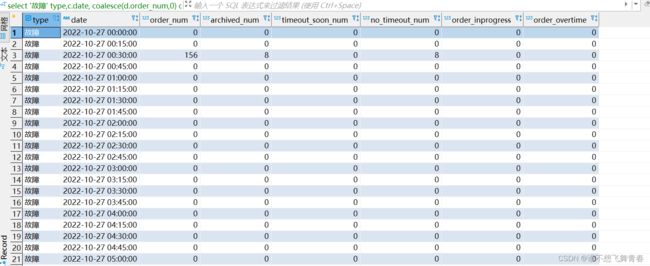
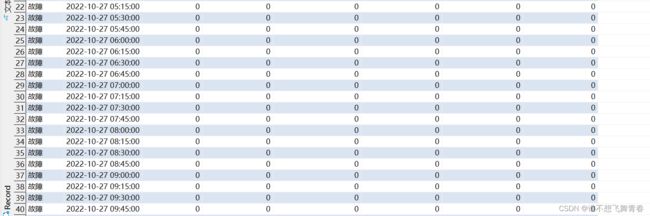
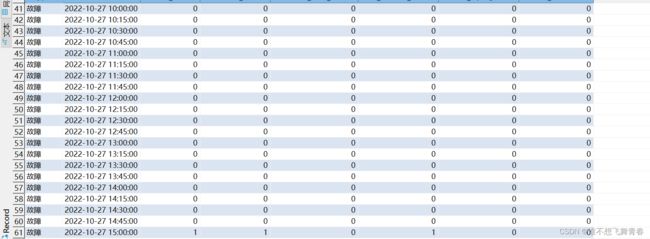
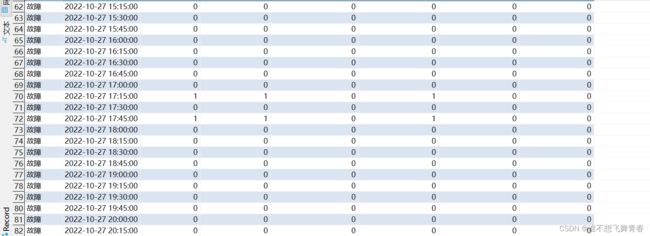
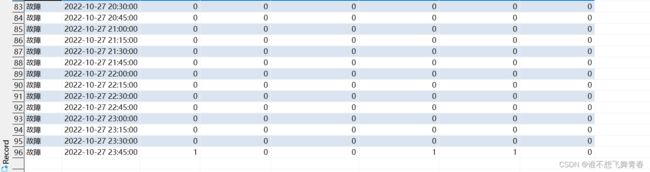
统计结果看order_num工单数量可以看到[2022-10-27 00:30:00,2022-10-27 00:45:00)这个前闭后开区间共有156条数据。将create_time>=2022-10-27 00:30:00 and create_time<2022-10-27 00:45:00这个时间段的数据全部汇聚统计到了2022-10-27 00:30:00这个时间段。
同理[2022-10-27 15:00:00,2022-10-27 15:15:00)这个区间一条数据。
[2022-10-27 17:15:00,2022-10-27 17:30:00)这个区间一条数据。
[2022-10-27 17:45:00,2022-10-27 18:00:00)这个区间一条数据。
[2022-10-27 23:45:00,2022-10-28 00:00:00)这个区间一条数据。
一共160条数据,全部符合范围匹配。
小时粒度工单统计
在实际开发中,也是只需要传一个开始时间和结束时间这2个参数就行
原mybatis中sql代码(比15分钟粒度sql要简单一些):
这个符合是mybatis中不编译的意思,不加这个的话>和<或者其他特殊符号提交给gitlab后会转义成字符,如:>变为& gt;这种形式。符号
select '故障' type,a.date||':00:00' date,
coalesce(b.order_num,0) order_num,
coalesce(b.archived_num,0) archived_num,
coalesce(b.timeout_soon_num,0) timeout_soon_num,
coalesce(b.no_timeout_num,0) no_timeout_num,
coalesce(b.order_inprogress,0) order_inprogress,
coalesce(b.order_overtime,0) order_overtime
from
(select to_char(t,'yyyy-MM-dd HH24') date
from generate_series(cast(#{startTime} as timestamp),cast(#{endTime} as timestamp),'1 hour') t) a
left join
(select to_char(create_time,'yyyy-MM-dd HH24') date,
count(distinct ticket_id) order_num,
count(distinct case when ticket_status ='已归档' then ticket_id end) archived_num,
count(distinct case when ticket_status !='已归档' and is_time_out !='是' and timeout_soon =true then ticket_id end) timeout_soon_num,
count(distinct case when is_time_out !='是' then ticket_id end) no_timeout_num,
count(distinct case when ticket_status !='已归档' then ticket_id end) order_inprogress,
count(distinct case when ticket_status !='已归档' and is_time_out ='是' then ticket_id end) order_overtime
from rnodbv3.v_m_cm5g_ticket_alarm_general
where curr_flag=true
<![CDATA[and create_time>=cast(#{startTime} as timestamp) and create_time<cast(#{endTime} as timestamp)+interval '1 hour' ]]>
group by date) b on a.date=b.date
sql实际执行结果:
这里将ticket_id前的distinct去重删除是为了给你们方便比对统计结果是不是160条。
select '故障' type,a.date,
coalesce(b.order_num,0) order_num,
coalesce(b.archived_num,0) archived_num,
coalesce(b.timeout_soon_num,0) timeout_soon_num,
coalesce(b.no_timeout_num,0) no_timeout_num,
coalesce(b.order_inprogress,0) order_inprogress,
coalesce(b.order_overtime,0) order_overtime
from
(select to_char(t,'yyyy-MM-dd HH24:00:00') date
from generate_series(cast('2022-10-27 00:00:00' as timestamp),cast('2022-10-27 23:00:00' as timestamp),'1 hour') t) a
left join
(select to_char(create_time,'yyyy-MM-dd HH24:00:00') date,
count(ticket_id) order_num,
count(distinct case when ticket_status ='已归档' then ticket_id end) archived_num,
count(distinct case when ticket_status !='已归档' and is_time_out !='是' and timeout_soon =true then ticket_id end) timeout_soon_num,
count(distinct case when is_time_out !='是' then ticket_id end) no_timeout_num,
count(distinct case when ticket_status !='已归档' then ticket_id end) order_inprogress,
count(distinct case when ticket_status !='已归档' and is_time_out ='是' then ticket_id end) order_overtime
from rnodbv3.v_m_cm5g_ticket_alarm_general
where curr_flag=true
and create_time>=cast('2022-10-27 00:00:00' as timestamp) and create_time<cast('2022-10-27 23:00:00' as timestamp)+interval '1 hour'
group by date) b on a.date=b.date
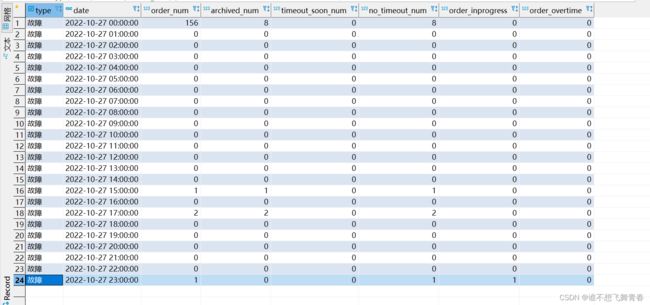
统计结果符合预期。
天粒度工单统计
在实际开发中,也是只需要传一个开始时间和结束时间这2个参数就行。
原mybatis中sql代码:
sql写法和小时粒度一样,唯一区别就是时间格式不一样
select '故障' type,a.date,
coalesce(b.order_num,0) order_num,
coalesce(b.archived_num,0) archived_num,
coalesce(b.timeout_soon_num,0) timeout_soon_num,
coalesce(b.no_timeout_num,0) no_timeout_num,
coalesce(b.order_inprogress,0) order_inprogress,
coalesce(b.order_overtime,0) order_overtime
from
(select to_char(t,'yyyy-MM-dd') date
from generate_series(cast(#{condition.startTime} as timestamp),cast(#{condition.endTime} as timestamp),'1 day') t) a
left join
(select to_char(create_time,'yyyy-MM-dd') date,
count(distinct ticket_id) order_num,
count(distinct case when ticket_status ='已归档' then ticket_id end) archived_num,
count(distinct case when ticket_status !='已归档' and is_time_out !='是' and timeout_soon =true then ticket_id end) timeout_soon_num,
count(distinct case when is_time_out !='是' then ticket_id end) no_timeout_num,
count(distinct case when ticket_status !='已归档' then ticket_id end) order_inprogress,
count(distinct case when ticket_status !='已归档' and is_time_out ='是' then ticket_id end) order_overtime
from rnodbv3.v_m_cm5g_ticket_alarm_general
where curr_flag=true
<![CDATA[and create_time>=cast(#{condition.startTime} as timestamp) and create_time<cast(#{condition.endTime} as timestamp)+interval '1 day' ]]>
group by date) b on a.date=b.date
sql实际执行结果:
这里将ticket_id前的distinct去重删除是为了给你们方便比对统计结果是不是160条。
select '故障' type,a.date,
coalesce(b.order_num,0) order_num,
coalesce(b.archived_num,0) archived_num,
coalesce(b.timeout_soon_num,0) timeout_soon_num,
coalesce(b.no_timeout_num,0) no_timeout_num,
coalesce(b.order_inprogress,0) order_inprogress,
coalesce(b.order_overtime,0) order_overtime
from
(select to_char(t,'yyyy-MM-dd') date
from generate_series(cast('2022-10-01 00:00:00' as timestamp),cast('2022-10-31 00:00:00' as timestamp),'1 day') t) a
left join
(select to_char(create_time,'yyyy-MM-dd') date,
count(ticket_id) order_num,
count(distinct case when ticket_status ='已归档' then ticket_id end) archived_num,
count(distinct case when ticket_status !='已归档' and is_time_out !='是' and timeout_soon =true then ticket_id end) timeout_soon_num,
count(distinct case when is_time_out !='是' then ticket_id end) no_timeout_num,
count(distinct case when ticket_status !='已归档' then ticket_id end) order_inprogress,
count(distinct case when ticket_status !='已归档' and is_time_out ='是' then ticket_id end) order_overtime
from rnodbv3.v_m_cm5g_ticket_alarm_general
where curr_flag=true
and create_time>=cast('2022-10-01 00:00:00' as timestamp) and create_time<=cast('2022-10-31 00:00:00' as timestamp)
group by date) b on a.date=b.date
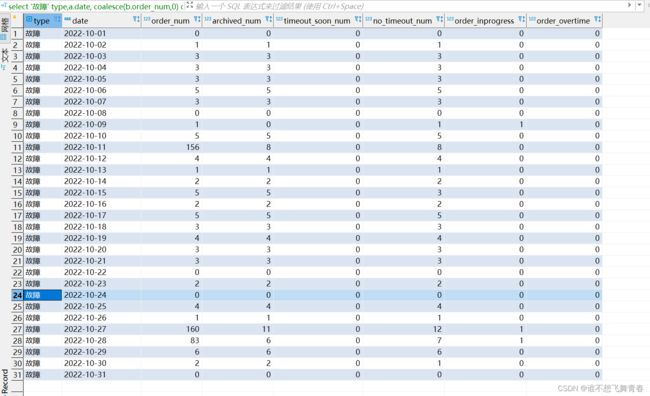
统计结果符合预期。
周粒度工单统计
在实际开发中,也是只需要传一个开始时间和结束时间这2个参数就行。
原mybatis中sql代码:
sql写法和15分钟粒度一样
select '故障' type,c.date,
coalesce(d.order_num,0) order_num,
coalesce(d.archived_num,0) archived_num,
coalesce(d.timeout_soon_num,0) timeout_soon_num,
coalesce(d.no_timeout_num,0) no_timeout_num,
coalesce(d.order_inprogress,0) order_inprogress,
coalesce(d.order_overtime,0) order_overtime
from
(select to_char(t,'yyyy-MM-dd') date
from generate_series(cast(#{startTime} as timestamp),cast(#{endTime} as timestamp),'1 week') t) c
left join
(select to_char(b.starttime,'yyyy-MM-dd') date,
count(distinct a.ticket_id) order_num,
count(distinct case when a.ticket_status ='已归档' then a.ticket_id end) archived_num,
count(distinct case when a.ticket_status !='已归档' and a.is_time_out !='是' and a.timeout_soon =true then a.ticket_id end) timeout_soon_num,
count(distinct case when a.is_time_out !='是' then a.ticket_id end) no_timeout_num,
count(distinct case when a.ticket_status !='已归档' then a.ticket_id end) order_inprogress,
count(distinct case when a.ticket_status !='已归档' and a.is_time_out ='是' then a.ticket_id end) order_overtime
from rnodbv3.v_m_cm5g_ticket_alarm_general a
left join
(select t as starttime ,t +'1 week' as endtime
from generate_series(cast(#{startTime} as timestamp),cast(#{endTime} as timestamp),'1 week') t
) b on <![CDATA[ a.create_time >=b.starttime and a.create_time <b.endtime ]]>
where a.curr_flag=true
<![CDATA[and a.create_time>=cast(#{startTime} as timestamp) and a.create_time<cast(#{endTime} as timestamp)+interval '1 week' ]]>
group by b.starttime
order by b.starttime) d on c.date=d.date
sql实际执行结果:
这里将ticket_id前的distinct去重删除是为了给你们方便比对统计结果是不是160条。
select '故障' type,c.date,
coalesce(d.order_num,0) order_num,
coalesce(d.archived_num,0) archived_num,
coalesce(d.timeout_soon_num,0) timeout_soon_num,
coalesce(d.no_timeout_num,0) no_timeout_num,
coalesce(d.order_inprogress,0) order_inprogress,
coalesce(d.order_overtime,0) order_overtime
from
(select to_char(t,'yyyy-MM-dd') date
from generate_series(cast('2022-08-01 00:00:00' as timestamp),cast('2022-10-31 00:00:00' as timestamp),'1 week') t) c
left join
(select to_char(b.starttime,'yyyy-MM-dd') date,
count(a.ticket_id) order_num,
count(distinct case when a.ticket_status ='已归档' then a.ticket_id end) archived_num,
count(distinct case when a.ticket_status !='已归档' and a.is_time_out !='是' and a.timeout_soon =true then a.ticket_id end) timeout_soon_num,
count(distinct case when a.is_time_out !='是' then a.ticket_id end) no_timeout_num,
count(distinct case when a.ticket_status !='已归档' then a.ticket_id end) order_inprogress,
count(distinct case when a.ticket_status !='已归档' and a.is_time_out ='是' then a.ticket_id end) order_overtime
from rnodbv3.v_m_cm5g_ticket_alarm_general a
left join
(select t as starttime ,t +'1 week' as endtime
from generate_series(cast('2022-08-01 00:00:00' as timestamp),cast('2022-10-31 00:00:00' as timestamp),'1 week') t
) b on a.create_time >=b.starttime and a.create_time <b.endtime
where a.curr_flag=true
and a.create_time>=cast('2022-08-01 00:00:00' as timestamp) and a.create_time<cast('2022-10-31 00:00:00' as timestamp)+interval '1 week'
group by b.starttime
order by b.starttime) d on c.date=d.date
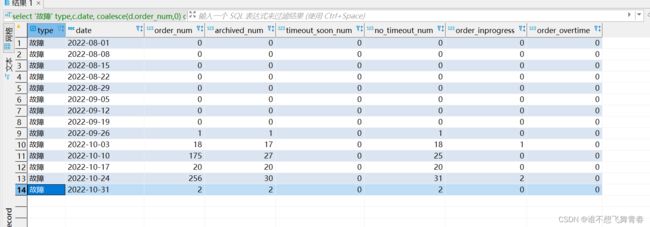
可以看到这里是统计每周一到周日这7天的工单。2022-10-24刚好是周一,2022-10-31也是周一。结果也是符合预期。

月粒度工单统计
在实际开发中,也是只需要传一个开始时间和结束时间这2个参数就行。
原mybatis中sql代码:
sql写法和小时粒度、天粒度一样。
select '故障' type,a.date,
coalesce(b.order_num,0) order_num,
coalesce(b.archived_num,0) archived_num,
coalesce(b.timeout_soon_num,0) timeout_soon_num,
coalesce(b.no_timeout_num,0) no_timeout_num,
coalesce(b.order_inprogress,0) order_inprogress,
coalesce(b.order_overtime,0) order_overtime
from
(select to_char(t,'yyyy-MM') date
from generate_series(cast(#{condition.startTime} as timestamp),cast(#{condition.endTime} as timestamp),'1 month') t) a
left join
(select to_char(create_time,'yyyy-MM') date,
count(distinct ticket_id) order_num,
count(distinct case when ticket_status ='已归档' then ticket_id end) archived_num,
count(distinct case when ticket_status !='已归档' and is_time_out !='是' and timeout_soon =true then ticket_id end) timeout_soon_num,
count(distinct case when is_time_out !='是' then ticket_id end) no_timeout_num,
count(distinct case when ticket_status !='已归档' then ticket_id end) order_inprogress,
count(distinct case when ticket_status !='已归档' and is_time_out ='是' then ticket_id end) order_overtime
from rnodbv3.v_m_cm5g_ticket_alarm_general
where curr_flag=true
and create_time>=cast(#{condition.startTime} as timestamp) and create_time<cast(#{condition.endTime} as timestamp)+interval '1 month' ]]>
group by date) b on a.date=b.date
sql实际执行结果:
这里将ticket_id前的distinct去重删除是为了给你们方便比对统计结果是不是160条。
select '故障' type,a.date,
coalesce(b.order_num,0) order_num,
coalesce(b.archived_num,0) archived_num,
coalesce(b.timeout_soon_num,0) timeout_soon_num,
coalesce(b.no_timeout_num,0) no_timeout_num,
coalesce(b.order_inprogress,0) order_inprogress,
coalesce(b.order_overtime,0) order_overtime
from
(select to_char(t,'yyyy-MM') date
from generate_series(cast('2022-01-01 00:00:00' as timestamp),cast('2022-12-01 00:00:00' as timestamp),'1 month') t) a
left join
(select to_char(create_time,'yyyy-MM') date,
count(ticket_id) order_num,
count(distinct case when ticket_status ='已归档' then ticket_id end) archived_num,
count(distinct case when ticket_status !='已归档' and is_time_out !='是' and timeout_soon =true then ticket_id end) timeout_soon_num,
count(distinct case when is_time_out !='是' then ticket_id end) no_timeout_num,
count(distinct case when ticket_status !='已归档' then ticket_id end) order_inprogress,
count(distinct case when ticket_status !='已归档' and is_time_out ='是' then ticket_id end) order_overtime
from rnodbv3.v_m_cm5g_ticket_alarm_general
where curr_flag=true
and create_time>=cast('2022-01-01 00:00:00' as timestamp) and create_time<cast('2022-12-01 00:00:00' as timestamp)+interval '1 month'
group by date) b on a.date=b.date
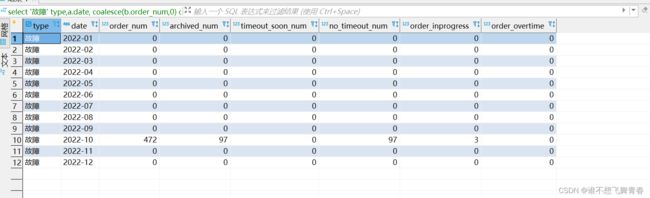
可以看到这里是统计每月1号到月底的工单。结果也是符合预期。

好了,我得分享到这里就结束了。