puppet 入门详解 超详细!!!
目录
一、puppet概述
二、Puppet的工作模式是什么?
三、Puppet的适用场景是什么?
四、原理
(一)工作模型
(二)工作流程
(三)使用模型
1、单机使用模型
2、master/agent 模型
(四)名词解释
五、puppet 资源详解
(一)程序安装及环境
(二)puppet 资源简介
1、资源抽象
2、资源定义
3、资源属性
(三)常用资源
1、查看资源
2、group(管理系统上的用户组。)
3、user(管理系统上的用户)
4、package(puppet的管理软件包)
5、service(定义服务的状态)
6、file(管理文件、目录、软链接)
7、exec(执行命令,慎用。通常用来执行外部命令)
8、cron(定义周期性任务)
9、notify(调试输出)
(四)资源的特殊属性
1、puppet 中也提供了 before、require、notify 和 subscribe 四个参数来定义资源之间的依赖关系和通知关系。
2、同时,依赖关系还可以使用 -> 和 ~> 来表示:
3、举例如下:
4、我们还可以使用在最下面统一写依赖关系的方式来定义:
5、tag 标签:
6、实例:
(五)puppet 变量
1、数据类型:
2、正则表达式:
3、puppet的变量种类
4、变量的作用域
(六)puppet 流程控制语句
1、if 语句
2、case 语句
3、selector 语句
六、class类
(一)什么是类?
1、类是 puppet 中命名的代码模块,常用于定义一组通用目标的资源,可在 puppet 全局调用;类可以被继承,也可以包含子类;
2、具体定义的语法如下:
3、我们来看一个简单的例子:
(二)带有参数的类
1、我们定义的类也可以进行参数设置,可以进行参数的传递。
2、具体语法如下所示:
3、举例:
4、由上,我们可以总结出,调用类的方式有两种:
5、一个比较全面的例子
(三)类的继承
1、类似于其它编程语言中的类的功能,puppet 的Class 可以被继承,也可以包含子类。
2、其定义的语法如下:
3、举例:
七、模板
(一)模板通常以 erb 结尾。
(二)模板均使用 erb 语法。
(三)关于 puppet 兼容的 erb 语法,我们可以去官方文档查看,下面附上官方文档地址:https://docs.puppet.com/puppet/latest/reference/lang_template_erb.html。以下,附上部分重要内容:
(四)实例:puppet 模板实现修改 redis 端口地址
1、我们使用 puppet 模板来实现,将 redis 监听端口修改为本机的 ip 地址。首先,我们先来定义一个 file.pp 文件,在该文件中调用我们的模板:
2、接着,我们去修改配置文件的源,也就是我们的模板文件:
3、修改完成以后,我们就可以执行查看结果了:
4、然后,我们去查看一下 /tmp/redis.conf文件:
八、模块
(一)什么是模块?
(二)模块的命名规范
(三)实例:定义一个redis主从模块
1、我们先来创建对应的目录格式:
2、目录格式创建完成之后,我们就可以来创建对应的父类子类文件了。首先,我们来创建父类文件:
3、创建完成后,我们再来创建对应的子类文件:
4、准备文件:
5、查看目录结构
6、模块放入系统模块
7、调用模块
九、master/agent 模型
(一)实验前准备
1、下载包
2、解析主机名
3、时间同步
(二)开启 master 端的 puppet 服务
1、手动前台开启,观察服务开启过程:
2、直接 systemctl 开启服务,监听在 8140 端口
(三)在 agent 端开启服务
1、在配置文件中指明server端的主机名:
2、开启 agent 服务
3、在 master 端签署证书
4、终止服务开启,再次开启
(四)配置站点清单,且测试agent 端是否实现
1、设置站点清单
2、给puppet 用户授权
3、手动前台开启 agent 端服务
4、直接开启服务,agent 会自动去master 端获取配置
十、实战
使用 master-agent 模型完成完整的 redis 主从架构
(一)准备环境
(二)实验前准备
1、下载包
2、主机名解析
3、时间同步
(三)开启puppet 的master、agent 服务
1、开启服务
2、master 签署颁发证书
(四)配置站点清单
(五)检测主从架构
(六)再添加个模块准备配置进站点清单
1、创建一个 chrony 模块,前准备
2、配置chrony 模块
3、puppet 添加这个模块,并生效
(七)再配置站点清单
(八)测试
一、puppet概述
1、Puppet是一种Linux、Unix、windows平台的集中配置管理系统,使用自有的Puppet描述语言,可管理配置文件、用户、cron任务、软件包、系统服务等。
2、puppet 是一个 IT 基础设施自动化管理工具,它能够帮助系统管理员管理基础设施的整个生命周期: 供应(provisioning)、配置(configuration)、联动(orchestration)及报告(reporting)。
3、puppet也是目前互联网企业的自动化运维工具之一,其使用一种描述性的语言给客户端声明了一些状态配置,比如,一个服务应该被安装等。
4、puppet也是目前互联网企业的自动化运维工具之一,其使用一种描述性的语言给客户端声明了一些状态配置,比如,一个服务应该被安装等。
5、基于 puppet ,可实现自动化重复任务、快速部署关键性应用以及在本地或云端完成主动管理变更和快速扩展架构规模等。puppet 遵循 GPL 协议(2.7.0-),基于ruby语言开发。2.7.0 以后使用(Apache 2.0 license),对于系统管理员是抽象的,只依赖于 ruby 与 facter。能管理多达40 多种资源,例如:file、user、group、host、package、service、cron、exec、yum repo等。
6、puppet既可以工作在主动模式下,也可以工作在被动模式下,在主动模式下,puppet客户端主动拉取服务器配置文件;在被动模式下,puppet服务器主动通知puppet客户端,使puppet客户端开启同步工作。
7、对于puppet而言,如果硬件设备性能比较高,在被管理客户端配置一致的情况下,管理成千上百台设备是非常简单的。但是在一些大型的企业中,如果只有一台puppet服务器,则puppet服务器的压力则会非常大,这时可以考虑把puppet扩展成一个服务器集群组。
8、puppet使用ruby语言编写,而ruby语言是解析型语言,所谓解析型语言,就是ruby语言的每次执行,都需要借助翻译器将ruby语言翻译成可以被CPU直接执行的机器码。由于多了这么一个“翻译”的过程,因此,ruby语言编写的程序执行速度较慢。
二、Puppet的工作模式是什么?
Puppet采用C/S星状的结构,所有的客户端和一个或几个服务器交互。每个客户端周期的(默认半个小时)向服务器发送请求,获得其最新的配置信息,并且严格按照配置文件来配置客户端,保证和该配置信息同步。配置完成以后,Puppet客户端可以反馈给服务器端一个消息. 如果出错,也会给服务器端反馈一个消息。
三、Puppet的适用场景是什么?
1、由于Puppet的工作模式是agent节点到master节点“拉取同步信息”,它适用于有非常多的节点的大集群,对配置生效时间不敏感的场景。
2、puppet把这些系统实体称之为资源,Puppet的设计目标是简化对这些资源的管理以及妥善处理资源间的依赖关系。
3、Puppet的全部就是管理资源,因此Puppet语言的焦点就是处理这些资源,避免重复配置。
4、Puppet的编译器会避免在不同的代码段里面管理同一个资源, 如果在不同的代码段对同一个资源进行配置,执行Puppet的时候你会得到一个语法错误.Puppet探测这种冲突的情况是通过判断资源类型和资源的title(标题),如果两个资源有相同的资源类型和title,那么就认为这两个资源是表示同一个资源。
四、原理
(一)工作模型
puppet 通过声明性、基于模型的方法进行IT自动化管理:
定义:通过puppet 的声明性配置语言定义基础设置配置的目标状态;
模拟:强制应用改变的配置之前先进行模拟性应用;
强制:自动、强制部署达成目标状态,纠正任何偏离的配置;
报告:报告当下状态及目标状态的不同,以及达成目标状态所进行的任何强制性改变;
puppet 三层模型如下:

(二)工作流程

(三)使用模型
puppet 的使用模型分为单机使用模型和 master/agent 模型
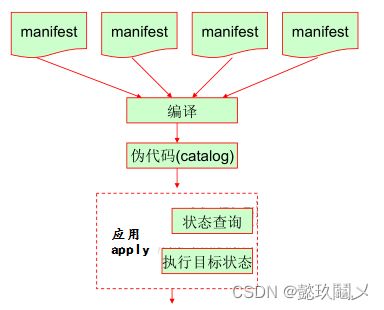
1、单机使用模型
实现定义多个 manifests --> complier --> catalog --> apply
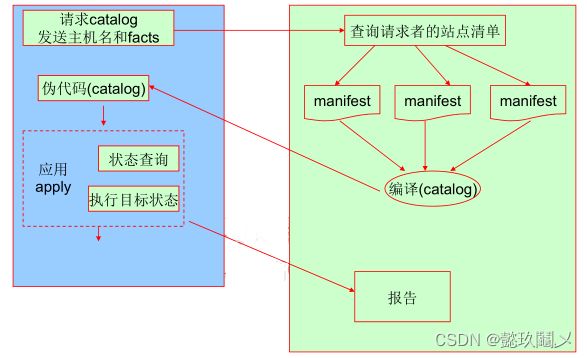
2、master/agent 模型
master/agent 模型实现的是集中式管理,即 agent 端周期性向 master 端发起请求,请求自己需要的数据。然后在自己的机器上运行,并将结果返回给 master 端。
架构和工作原理如下:

(四)名词解释
1、资源:是puppet的核心,通过资源申报,定义在资源清单中。相当于ansible中的模块,只是抽象的更加彻底。
2、类:一组资源清单。
3、模块:包含多个类。相当于ansible中的角色。
4、站点清单:以主机为核心,应用哪些模块。
五、puppet 资源详解
(一)程序安装及环境
首先,我们还是来安装一下 puppet,puppet 的安装可以使用源码安装,也可以使用 rpm(官方提供)、epel 源、官方提供的 yum 仓库来安装(通过下载官方提供的 rpm 包可以指定官方的 yum 仓库)。在这里,我们就是用 yum 安装的方式。
命令:yum -y install puppet
安装完成过后,我们可以通过rpm -ql puppet | less来查看一下包中都有一些什么文件。其中主配置文件为 /etc/puppet/puppet.conf,使用的主程序为 /usr/bin/puppet。
(二)puppet 资源简介
1、资源抽象
puppet 从以下三个维度来对资源完成抽象:
①相似的资源被抽象成同一种资源**“类型”** ,如程序包资源、用户资源及服务资源等;
②将资源属性或状态的描述与其实现方式剥离开来,如仅说明安装一个程序包而不用关心其具体是通过 yum、pkgadd、ports 或是其它方式实现;
③仅描述资源的目标状态,也即期望其实现的结果,而不是其具体过程,如“确定 nginx 运行起来” 而不是具体描述为“运行 nginx 命令将其启动起来”;
这三个也被称作 puppet 的资源抽象层(RAL),RAL 由 type( 类型) 和 provider( 提供者,即不同 OS 上的特定实现)组成。
2、资源定义
资源定义通过向资源类型的属性赋值来实现,可称为资源类型实例化;
定义了资源实例的文件即清单,manifest;
定义资源的语法如下:
type {'title':
attribute1 => value1,
atrribute2 => value2,
……
}
注意:type必须使用小写字符;title是一个字符串,在同一类型中必须惟一;每一个属性之间需要用“,”隔开,最后一个“,”可省略。例如,可以同时有名为nginx 的“service”资源和“package”资源,但在“package” 类型的资源中只能有一个名为“nginx”的资源。
3、资源属性
资源属性中的三个特殊属性:
①Namevar:可简称为name;
②ensure:资源的目标状态;
③Provider:指明资源的管理接口;
(三)常用资源
1、查看资源
我们可以使用puppet describe来打印有关Puppet资源类型,提供者和元参数的帮助。使用语法如下:
puppet describe [-h|--help] [-s|--short] [-p|--providers] [-l|--list] [-m|--meta] [type]
-l:列出所有资源类型;
-s:显示指定类型的简要帮助信息;
-m:显示指定类型的元参数,一般与-s一同使用;
2、group(管理系统上的用户组。)
①查看使用帮助信息:

②group 使用帮助
属性:
name:组名,可以省略,如果省略,将继承title的值;
gid:GID;
system:是否为系统组,true OR false;
ensure:目标状态,present/absent;
members:成员用户;
③简单举例如下:
vim group.pp
group{'mygrp':
name => 'mygrp',
ensure => present,
gid => 2000,
}
运行一下:

运行写好的group资源
3、user(管理系统上的用户)
①查看使用帮助信息:

②user使用帮助
属性:
name:用户名,可以省略,如果省略,将继承title的值;
uid: UID;
gid:基本组ID;
groups:附加组,不能包含基本组;
comment:注释;
expiry:过期时间 ;
home:用户的家目录;
shell:默认shell类型;
system:是否为系统用户 ;
ensure:present/absent;
password:加密后的密码串;
③简单举例如下:
vim user1.pp
user{'keerr':
ensure => present,
system => false,
comment => 'Test User',
shell => '/bin/tcsh',
home => '/data/keerr',
managehome => true,
groups => 'mygrp',
uid => 3000,
}
4、package(puppet的管理软件包)
①查看使用帮助信息:

②package 使用帮助
属性:
ensure:installed, present, latest, absent, any version string (implies present)
name:包名,可以省略,如果省略,将继承title的值;
source:程序包来源,仅对不会自动下载相关程序包的provider有用,例如rpm或dpkg;
provider:指明安装方式;
③简单举例如下:
vim package1.pp
package{'nginx':
ensure => installed,
procider => yum
}
5、service(定义服务的状态)
①查看使用帮助信息:

②service 使用帮助
属性:
ensure:服务的目标状态,值有true(running)和false(stopped)
enable:是否开机自动启动,值有true和false
name:服务名称,可以省略,如果省略,将继承title的值
path:服务脚本路径,默认为/etc/init.d/下
start:定制启动命令
stop:定制关闭命令
restart:定制重启命令
status:定制状态
③简单举例如下:
vim service1.pp
service{'nginx':
ensure => true,
enable => false
}
6、file(管理文件、目录、软链接)
①查看使用帮助信息:

②file使用帮助
属性:
ensure:目标状态,值有absent,present,file,directory和link
file:类型为普通文件,其内容由content属性生成或复制由source属性指向的文件路径来创建;
link:类型为符号链接文件,必须由target属性指明其链接的目标文件;
directory:类型为目录,可通过source指向的路径复制生成,recurse属性指明是否递归复制;
path:文件路径;
source:源文件;
content:文件内容;
target:符号链接的目标文件;
owner:定义文件的属主;
group:定义文件的属组;
mode:定义文件的权限;
atime/ctime/mtime:时间戳;
③简单举例如下:
vim file1.pp
file{'aaa':
path => '/data/aaa',
source => '/etc/aaa',
owner => 'keerr',
mode => '611',
}
7、exec(执行命令,慎用。通常用来执行外部命令)
①查看使用帮助信息:
puppet describe exec -s -m
②exec 使用帮助
属性:
command(namevar):要运行的命令;
cwd:指定运行该命令的目录;
creates:文件路径,仅此路径表示的文件不存在时,command方才执行;
user/group:运行命令的用户身份;
path:指定命令执行的搜索路径;
onlyif:此属性指定一个命令,此命令正常(退出码为0)运行时,当前command才会运行;
unless:此属性指定一个命令,此命令非正常(退出码为非0)运行时,当前command才会运行;
refresh:重新执行当前command的替代命令;
refreshonly:仅接收到订阅的资源的通知时方才运行;
③简单举例如下:
vim exec1.pp
exec{'cmd':
command => 'mkdir /data/testdir',
path => ['/bin','/sbin','/usr/bin','/usr/sbin'],
# path => '/bin:/sbin:/usr/bin:/usr/sbin',
}
8、cron(定义周期性任务)
①查看使用帮助信息:

②cron 使用帮助
属性:
command:要执行的任务(命令或脚本);
ensure:目标状态,present/absent;
hour:时;
minute:分;
monthday:日;
month:月;
weekday:周;
user:以哪个用户的身份运行命令(默认为root);
target:添加为哪个用户的任务;
name:cron job的名称;
③简单举例如下:
vim cron1.pp
cron{'timesync':
command => '/usr/sbin/ntpdata 172.16.0.1',
ensure => present,
minute => '*/3',
user => 'root',
}
我们可以运行一下,查看我们的 crontab,来看看该任务是否已经被添加:
[root@master manifests]# puppet apply -v --noop cron1.pp #试运行
[root@master manifests]# puppet apply -v cron1.pp #运行
[root@master manifests]# crontab -l #查看计划任务
# HEADER: This file was autogenerated at 2017-12-14 15:05:05 +0800 by puppet.
# HEADER: While it can still be managed manually, it is definitely not recommended.
# HEADER: Note particularly that the comments starting with 'Puppet Name' should
# HEADER: not be deleted, as doing so could cause duplicate cron jobs.
# Puppet Name: timesync
*/3 * * * * /usr/sbin/ntpdata 172.16.0.1
9、notify(调试输出)
①查看使用帮助信息:

②notify使用帮助
属性:
message:记录的信息
name:信息名称
该选项一般用于 master/agent 模式中,来记录一些操作的时间,比如重新安装了一个程序呀,或者重启了应用等等。会直接输出到代理机的运行日志中。以上,就是我们常见的8个资源。其余的资源我们可以使用 puppet describe -l 来列出。
(四)资源的特殊属性
1、puppet 中也提供了 before、require、notify 和 subscribe 四个参数来定义资源之间的依赖关系和通知关系。
before:表示需要依赖于某个资源
require:表示应该先执行本资源,在执行别的资源
notify:A notify B:B依赖于A,且A发生改变后会通知B;
subscribe:B subscribe A:B依赖于A,且B监控A资源的变化产生的事件;
2、同时,依赖关系还可以使用 -> 和 ~> 来表示:
-> 表示后资源需要依赖前资源
~> 表示前资源变动通知后资源调用
3、举例如下:
vim file.pp
file{'test.txt': #定义一个文件
path => '/data/test.txt',
ensure => file,
source => '/etc/fstab',
}
file{'test.symlink': #依赖文件建立超链接
path => '/data/test.symlink',
ensure => link,
target => '/data/test.txt',
require => File['test.txt'],
}
file{'test.dir': #定义一个目录
path => '/data/test.dir',
ensure => directory,
source => '/etc/yum.repo.d/',
recurse => true,
}
4、我们还可以使用在最下面统一写依赖关系的方式来定义:
vim redis.pp
package{'reids':
ensure => installed,
}
file{'/etc/redis.conf':
source => '/root/manifets/files/redis.conf',
ensure => file,
owner => redis,
group => root,
mode => '0640',
}
service{'redis':
ensure => running,
enable => true,
hasrestart => true,
}
Package['redis'] -> File['/etc/redis.conf'] -> Service['redis'] #定义依赖关系
5、tag 标签:
如同 anssible 一样,puppet 也可以定义“标签”——tag,打了标签以后,我们在运行资源的时候就可以只运行某个打过标签的部分,而非全部。这样就更方便于我们的操作。
一个资源中,可以有一个tag也可以有多个。具体使用语法如下:

调用时的语法如下:
puppet apply --tags TAG1,TAG2,... FILE.PP6、实例:
①首先,我们去修改一下redis.pp文件,添加一个标签进去
vim redis.pp
package{'redis':
ensure => installed,
}
file{'/etc/redis.conf':
source => '/root/manifets/file/redis.conf',
ensure => file,
owner => redis,
group => root,
mode => '0640',
tag => 'instconf' #定义标签
}
service{'redis':
ensure => running,
enable => true,
hasrestart => true,
}
Package['redis'] -> File['/etc/redis.conf'] -> Service['redis']
②然后,我们手动先开启 redis 服务:
systemctl start redis
③现在,我们去修改一下 file 目录下的配置文件:
vim file/redis.conf
requirepass keerya
④接着,我们就去运行 redis.pp,我们的配置文件已经修改过了,现在想要实现的就是重启该服务,实现,需要使用密码 keer 登录:
puppet apply -v --tags instconf redis.pp

⑤redis.pp 运行结果,现在,我们就去登录一下redis看看是否生效:
redis-cli -a keerya
(五)puppet 变量
puppet 变量以 “$” 开头,赋值操作符为 “=”,语法为 $variable_name=value。
1、数据类型:
字符型:引号可有可无;但单引号为强引用,双引号为弱引用;支持转义符;
数值型:默认均识别为字符串,仅在数值上下文才以数值对待;
数组:[]中以逗号分隔元素列表;
布尔型值:true, false;不能加引号;
hash:{}中以逗号分隔k/v数据列表; 键为字符型,值为任意puppet支持的类型;{ ‘mon’ => ‘Monday’, ‘tue’ => ‘Tuesday’, };
undef:从未被声明的变量的值类型;
2、正则表达式:
(?
: )
(?-: )
OPTIONS:
i:忽略字符大小写;
m:把.当换行符;
x:忽略中的空白字符;
(?i-mx:PATTERN)注意:不能赋值给变量,仅能用在接受
=~或!~操作符的位置;
3、puppet的变量种类
puppet 种类有三种,为facts,内建变量和用户自定义变量。
facts:
由facter提供;top scope;
内建变量:
master端变量
$servername, $serverip, $serverversion
agent端变量
$clientcert, $clientversion, $environment
parser变量
$module_name
用户自定义变量
4、变量的作用域
不同的变量也有其不同的作用域。我们称之为
Scope。
作用域有三种,top scope,node scope,class scope。
其生效范围排序为:top scope > node scope > class scope

变量生效范围,其优先级排序为:top scope < node scope < class scope
(六)puppet 流程控制语句
puppet 支持 if 语句,case 语句和 selector 语句。
1、if 语句
①if 语句支持单分支,双分支和多分支。
②具体语法如下:
单分支:
if CONDITION {
statement
……
}
双分支:
if CONDITION {
statement
……
}
else{
statement
……
}
多分支:
if CONDITION {
statement
……
}
elsif CONDITION{
statement
……
}
else{
statement
……
}
③其中,CONDITION 的给定方式有如下三种:
- 变量
- 比较表达式
- 有返回值的函数
④举例:
vim if.pp
if $operatingsystemmajrelease == '7' {
$db_pkg='mariadb-server'
}else{
$db_pkg='mysql-server'
}
package{"$db_pkg":
ensure => installed,
}
2、case 语句
①类似 if 语句,case 语句会从多个代码块中选择一个分支执行,这跟其它编程语言中的 case 语句功能一致。
②case 语句会接受一个控制表达式和一组 case 代码块,并执行第一个匹配到控制表达式的块。
③使用语法如下:
case CONTROL_EXPRESSION {
case1: { ... }
case2: { ... }
case3: { ... }
……
default: { ... }
}
④其中,CONTROL_EXPRESSION 的给定方式有如下三种:
- 变量
- 表达式
- 有返回值的函数
⑤各case的给定方式有如下五种:
- 直接字串;
- 变量
- 有返回值的函数
- 正则表达式模式;
- default
⑥举例:
vim case.pp
case $osfamily {
"RedHat": { $webserver='httpd' }
/(?i-mx:debian)/: { $webserver='apache2' }
default: { $webserver='httpd' }
}
package{"$webserver":
ensure => installed, before => [ File['httpd.conf'], Service['httpd'] ],
}
file{'httpd.conf':
path => '/etc/httpd/conf/httpd.conf',
source => '/root/manifests/httpd.conf',
ensure => file,
}
service{'httpd':
ensure => running,
enable => true, restart => 'systemctl restart httpd.service',
subscribe => File['httpd.conf'],
}
3、selector 语句
①Selector 只能用于期望出现直接值(plain value) 的地方,这包括变量赋值、资源属性、函数参数、资源标题、其它 selector。selector 不能用于一个已经嵌套于于 selector 的 case 中,也不能用于一个已经嵌套于 case 的 case 语句中。
②具体语法如下:
CONTROL_VARIABLE ? {
case1 => value1,
case2 => value2,
...
default => valueN,
}
③其中,CONTROL_EXPRESSION 的给定方式有如下三种:
- 变量
- 表达式
- 有返回值的函数
④各 case 的给定方式有如下五种:
- 直接子串;
- 变量;
- 有返回值的函数;
- 正则表达式模式;
- default
⑤selectors 使用要点:
1、整个 selector 语句会被当作一个单独的值,puppet 会将控制变量按列出的次序与每个 case 进行比较,并在遇到一个匹配的 case 后,将其值作为整个语句的值进行返回,并忽略后面的其它 case。
2、控制变量与各 case 比较的方式与 case 语句相同,但如果没有任何一个 case 与控制变量匹配时,puppet 在编译时将会返回一个错误,因此,实践中,其必须提供 default case。
3、selector 的控制变量只能是变量或有返回值的函数,切记不能使用表达式。
4、其各 case 可以是直接值(需要加引号) 、变量、能调用返回值的函数、正则表达式模式或 default。
5、但与 case 语句所不同的是,selector 的各 case 不能使用列表。
6、selector 的各 case 的值可以是一个除了 hash 以外的直接值、变量、能调用返回值的函数或其它的 selector。
⑥举例
vim selector.pp
$pkgname = $operatingsystem ? {
/(?i-mx:(ubuntu|debian))/ => 'apache2',
/(?i-mx:(redhat|fedora|centos))/ => 'httpd',
default => 'httpd',
}
package{"$pkgname":
ensure => installed,
}
六、class类
(一)什么是类?
1、类是 puppet 中命名的代码模块,常用于定义一组通用目标的资源,可在 puppet 全局调用;类可以被继承,也可以包含子类;
2、具体定义的语法如下:
class NAME{
... puppet code ...
}
3、我们来看一个简单的例子:
vim class1.pp
class redis { #定义一个类
package{'redis':
ensure => installed,
} ->
file{'/etc/redis.conf':
ensure => file,
source => '/root/manifests/file/redis.conf',
owner => 'redis',
group => 'root',
mode => '0640',
tag => 'redisconf'
} ~>
service{'redis':
ensure => running,
enable => true,
hasrestart => true,
hasstatus => true
}
}
include redis #调用类
注意:类只有被调用才会执行。include 后可以跟多个类,直接用","隔开即可。
(二)带有参数的类
1、我们定义的类也可以进行参数设置,可以进行参数的传递。
2、具体语法如下所示:
class NAME(parameter1, parameter2) { #注意,大括号前有一个空格
...puppet code...
}
3、举例:
vim class2.pp
class instpkg($pkg) {
package{"$pkg":
ensure => installed,
}
}
class{"instpkg": #给参数传入值
pkg => 'memcached',
}
注意:单个主机上不能被直接声明两次。如果对应的参数未传值的话,执行会报错。
但是我们可以在定义形参的时候,设定一个默认值,这样的话,我们不传入值的话,就会自动调用默认值:
vim class3.pp
class instpkg($pkg='wget') {
package{"$pkg":
ensure => installed,
}
}
include instpkg
这样的话,我们直接使用include调用即可,就不需要给参数传入值了。
4、由上,我们可以总结出,调用类的方式有两种:
1. include CLASS_NAME1, CLASS_NAME2, ...
2. class{'CLASS_NAME':
attribute => value,
}
5、一个比较全面的例子
①首先,判断我们系统的版本,是6还是7,由此来确定,是安装mysql还是mariadb,同时,使用调用参数的方式来实现如上需求。具体实现的代码如下:
vim dbserver.pp
class dbserver($dbpkg='mariadb-server',$svc='mariadb') { #定义类并给参数赋值
package{"$dbpkg":
ensure => installed,
}
service{"$svc":
ensure => running,
enable => true,
hasrestart => true,
hasstatus => true,
}
}
if $operatingsystem == 'CentOS' {
if $operatingsystemmajrelease == '7' {
include dbserver #直接调用类
} else {
class{"dbserver": #调用类并对参数重新赋值
dbpkg => 'mysql-server',
svc => 'mysqld'
}
}
}
(三)类的继承
1、类似于其它编程语言中的类的功能,puppet 的Class 可以被继承,也可以包含子类。
2、其定义的语法如下:
class SUB_CLASS_NAME inherits PARENT_CLASS_NAME {
...puppet code...
}
3、举例:
vim class4.pp
class redis { #定义class类
package{'redis':
ensure => installed,
}
service{'redis':
ensure => running,
enable => true,
}
}
class redis::master inherits redis { #调用父类
file {'/etc/redis.conf':
ensure => file,
source => '/root/manifests/file/redis-master.conf',
owner => 'redis',
group => 'root',
}
Service['redis'] { #定义依赖关系
subscribe => File['/etc/redis.conf']
}
}
class redis::slave inherits redis { #调用父类
file {'/etc/redis.conf':
ensure => file,
source => '/root/manifests/file/redis-slave.conf',
owner => 'redis',
group => 'root',
}
Service['redis'] { #定义依赖关系
subscribe => File['/etc/redis.conf']
}
}
一样的,我们的类在调用的时候,可以实现修改原有值和额外新增属性的功能。
①新增属性
我们的继承父类的时候,可以定义一些父类原本没有的属性:

②新增原有值
在继承的类中,我们可以在属性原有值的基础上,使用 +> 进行新增修改:

③修改原有值
在继承的类中,我们可以直接把原有的值进行覆盖修改,使用 =>进行覆盖即可:

④整体调用父类,并重写部分值
在继承的类中,我们还可以在整体调用的基础上,根据不同的需求,把父类中的部分值进行重写修改:

整体调用父类,并重写部分值
七、模板
(一)模板通常以 erb 结尾。
(二)模板均使用 erb 语法。
(三)关于 puppet 兼容的 erb 语法,我们可以去官方文档查看,下面附上官方文档地址:https://docs.puppet.com/puppet/latest/reference/lang_template_erb.html。以下,附上部分重要内容:
<%= EXPRESSION %> — 插入表达式的值,进行变量替换
<% CODE %> — 执行代码,但不插入值
<%# COMMENT %> — 插入注释
<%% or %%> — 插入%
(四)实例:puppet 模板实现修改 redis 端口地址
1、我们使用 puppet 模板来实现,将 redis 监听端口修改为本机的 ip 地址。首先,我们先来定义一个 file.pp 文件,在该文件中调用我们的模板:
vim file.pp
file{'/tmp/redis.conf': #仅用于测试模板是否生效,所以放在tmp目录下
ensure => file,
content => template('/root/manifests/file/redis.conf.erb'), #调用模板文件
owner => 'redis',
group => 'root',
mode => '0640',
}
2、接着,我们去修改配置文件的源,也就是我们的模板文件:
vim file/redis.conf.erb
bind 127.0.0.1 <%= @ipaddress_eth0 %> #修改监听端口
3、修改完成以后,我们就可以执行查看结果了:
puppet apply -v file.pp
4、然后,我们去查看一下 /tmp/redis.conf文件:
vim /tmp/redis.conf

监听端口,可以看出,我们的变量替换已经成功。
八、模块
(一)什么是模块?
实践中,一般需要把 manifest 文件分解成易于理解的结构,例如将类文件、配置文件甚至包括后面将提到的模块文件等分类存放,并且通过某种机制在必要时将它们整合起来。这种机制即模块,它有助于以结构化、层次化的方式使用 puppet,而 puppet 则基于“模块自动装载器”。从另一个角度来说,模块实际上就是一个按约定的、预定义的结构存放了多个文件或子目录的目录,目录里的这些文件或子目录必须遵循其命名规范。
(二)模块的命名规范
模块的目录格式如下:

目录格式,其中,每个文件夹中存放的内容及其要求如下:
•MODULE NAME:模块名称,模块名只能以小写字母开头,可以包含小写字母、数字和下划线;但不能使用"main"和"settings";
•manifests/:必须要有•init.pp:必须一个类定义,类名称必须与模块名称相同;
•files/:静态文件;
•其中,每个文件的访问路径遵循:puppet:///modules/MODULE_NAME/FILE_NAME;
•templates/:
•其中,每个文件的访问路径遵循:tempate('MOD_NAME/TEMPLATE_FILE_NAME');
•lib/:插件目录,常用于存储自定义的facts以及自定义类型;
•spec/:类似于tests目录,存储lib/目录下插件的使用帮助和范例;
•tests/:当前模块的使用帮助或使用范例文件;
(三)实例:定义一个redis主从模块
下面我们就来看一个实例来具体的了解应该如何定义一个模块:
1、我们先来创建对应的目录格式:
[root@master ~]# mkdir modules
[root@master ~]# cd modoules/
[root@master modules]# ls
[root@master modules]# mkdir -pv redis/{manifests,files,templates,tests,lib,spec}
mkdir: created directory ‘redis’
mkdir: created directory ‘redis/manifests’
mkdir: created directory ‘redis/files’
mkdir: created directory ‘redis/templates’
mkdir: created directory ‘redis/tests’
mkdir: created directory ‘redis/lib’
mkdir: created directory ‘redis/spec’
2、目录格式创建完成之后,我们就可以来创建对应的父类子类文件了。首先,我们来创建父类文件:
[root@master modules]# cd redis/
[root@master redis]# vim manifests/init.pp
class redis {
package{'redis':
ensure => installed,
} ->
service{'redis':
ensure => running,
enable => true,
hasrestart => true,
hasstatus => true,
require => Package['redis'],
}
}
3、创建完成后,我们再来创建对应的子类文件:
[root@master redis]# vim manifests/master.pp
class redis::master inherits redis {
file {'/etc/redis.conf':
ensure => file,
source => 'puppet:///modules/redis/redis-master.conf',
owner => 'redis',
group => 'root',
mode => '0640',
}
Package['redis'] -> File['/etc/redis.conf'] ~> Service['redis']
}
[root@master redis]# vim manifests/slave.pp
class redis::slave($master_ip,$master_port='6379') inherits redis {
file {'/etc/redis.conf':
ensure => file,
content => template('redis/redis-slave.conf.erb'),
owner => 'redis',
group => 'root',
mode => '0640',
}
Package['redis'] -> File['/etc/redis.conf'] ~> Service['redis']
}
4、准备文件:
现在我们需要把模板文件准备好,放入我们的 templates 目录下:
scp redis.conf.erb /root/modules/redis/templates/redis-slave.conf.erb
还有我们的静态文件,也要放入我们的 files 目录下:
scp redis.conf /root/modules/redis/files/redis-master.conf
5、查看目录结构
查看目录,确定我们是否都已准备完成:
[root@master modules]# tree
.
└── redis
├── files
│ └── redis-master.conf
├── lib
├── manifests
│ ├── init.pp
│ ├── master.pp
│ └── slave.pp
├── spec
├── templates
│ └── redis-slave.conf.erb
└── tests
7 directories, 5 files
6、模块放入系统模块
现在就可以把我们的准备好的模块放入系统的模块目录下:
[root@master mdoules]# cp -rp redis/ /etc/puppet/modules/
注意,模块是不能直接被调用的,只有放在 /etc/puppet/modules下,或/usr/share/puppet/modules目录下,使其生效才可以被调用。
我们可以来查看一下我们的模块到底有哪些:
[root@master mdoules]# puppet module list
/etc/puppet/modules
└── redis (???)
/usr/share/puppet/modules (no modules installed)
7、调用模块
我们可以直接命令行传入参数来调用我们准备好的模块:
[root@master modules]# puppet apply -v --noop -e "class{'redis::slave': master_ip => '192.168.37.100'}" #如果有多个参数,直接以逗号隔开即可
也可以把我们的调用的类赋值在 .pp 文件中,然后运行该文件。
[root@master ~]# cd manifests/
[root@master manifests]# vim redis2.pp
class{'redis::slave':
master_ip => '192.168.37.100',
}
[root@master manifests]# puppet apply -e --noop redis2.pp
以上步骤实验完成。注意,以上实验是我们在单机模式下进行的,如果是要在master/agent 模式下进行,步骤还会略有不同。
九、master/agent 模型
master/agent 模型时通过主机名进行通信的,下面,就来看看 master-agent 模式的 puppet 运维自动化如何实现?
实验步骤
(一)实验前准备
1、下载包
master 端:
puppet.noarch,puppet-server.noarch
agent 端:puppet.noarch

2、解析主机名
为了方便我们后期的操作,我们可以通过定义 /etc/hosts 文件实现主机名的解析。如果机器很多的话,可以使用 DNS 进行解析。
[root@master ~]# vim /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.37.111 master.keer.com
192.168.37.122 server1.keer.com
注意,该操作需要在每一台主机上进行。修改完成以后,我们可以来测试一下是否已经成功:
[root@master ~]# ping server1.keer.com
连通性测试
3、时间同步
[root@master ~]# systemctl start chronyd.service
所有机器上都开启 chronyd.service 服务来进行时间同步。开启过后可以查看一下状态:
[root@master ~]# systemctl status chronyd.service

时间同步状态,我们可以使用chronyc sources命令来查看时间源:

(二)开启 master 端的 puppet 服务
1、手动前台开启,观察服务开启过程:
puppet master -v --no-daemonize #前台运行
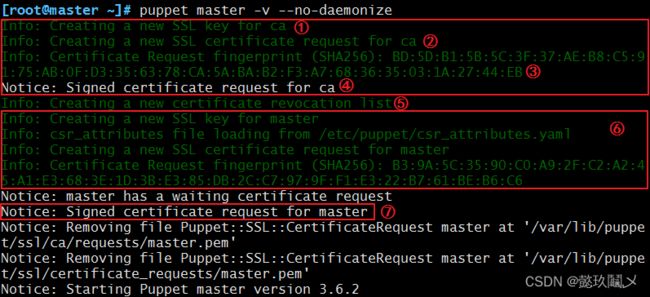
整个过程都是自动完成的,其中,每一步的意思如下:
① 创建key 给CA
② 创建一个请求给CA
③ 自签名证书
④ CA 创建完成
⑤ 创建证书吊销列表
⑥ 为当前的master 主机签署证书
⑦ master 的证书签署完成
2、直接 systemctl 开启服务,监听在 8140 端口

开启服务
(三)在 agent 端开启服务
1、在配置文件中指明server端的主机名:
[root@server1 ~]# vim /etc/puppet/puppet.conf
server = master.keer.com

agent 端配置文件。接着,我们可以通过 puppet config print 命令来打印输出我们配置的参数:
[root@server1 ~]# puppet config print 显示配置文件中的配置参数
[root@server1 ~]# puppet config print --section=main 显示main 段的配置参数
[root@server1 ~]# puppet config print --section=agent 显示agent 段的配置参数
[root@server1 ~]# puppet config print server 显示server 的配置参数

打印输出参数
2、开启 agent 服务
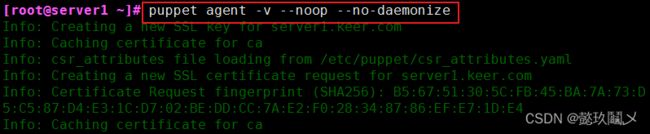
开启agent服务。我们可以发现,他会一直卡在这里等待CA颁发证书。
3、在 master 端签署证书
[root@master ~]# puppet cert list
"server1.keer.com" (SHA256) B5:67:51:30:5C:FB:45:BA:7A:73:D5:C5:87:D4:E3:1C:D7:02:BE:DD:CC:7A:E2:F0:28:34:87:86:EF:E7:1D:E4
[root@master ~]# puppet cert sign server1.keer.com #颁发证书
Notice: Signed certificate request for server1.keer.com
Notice: Removing file Puppet::SSL::CertificateRequest server1.keer.com at '/var/lib/puppet/ssl/ca/requests/server1.keer.com.pem'
master 端管理证书部署的命令语法如下:
puppet cert[–all|-a] [ ]
action:
list 列出证书请求
sign 签署证书
revoke 吊销证书
clean 吊销指定的客户端的证书,并删除与其相关的所有文件;
注意:某 agent 证书手工吊销后重新生成一次:
On master host:
puppet cert revoke NODE_NAME
puppet cert clean NODE_NAME
On agent host:
重新生成的主机系统,直接启动agent;
变换私钥,建议先清理/var/lib/puppet/ssl/目录下的文件
4、终止服务开启,再次开启
[root@server1 ~]# puppet agent -v --noop --no-daemonize

开启agent端服务。可以看出我们的服务开启成功,但是由于master 端没有配置站点清单,所以没有什么动作。
(四)配置站点清单,且测试agent 端是否实现
1、设置站点清单
①查询站点清单应存放的目录,(可以修改,去配置文件修改)
[root@master ~]# puppet config print |grep manifest

②查询配置文件的参数
[root@master ~]# cd /etc/puppet/manifests/
[root@master manifests]# vim site.pp
node 'server1.along.com' {
include redis::master
}
分析:就是简单的调用模块,只有模块提前定义好就可以直接调用;我调用的是上边的 redis 模块
2、给puppet 用户授权
因为agent 端要来master 端读取配置,身份是 puppet
[root@master manifests]# chown -R puppet /etc/puppet/modules/redis/*
3、手动前台开启 agent 端服务
[root@server1 ~]# puppet agent -v --noop --no-daemonize

enter description here
4、直接开启服务,agent 会自动去master 端获取配置
[root@server1 ~]# systemctl start puppetagent 包已下载,服务也开启了

enter description here
十、实战
使用 master-agent 模型完成完整的 redis 主从架构
(一)准备环境

(二)实验前准备
1、下载包
master 端:
puppet.noarch,puppet-server.noarch
agent 端:puppet.noarch

2、主机名解析
为了方便我们后期的操作,我们可以通过定义 /etc/hosts 文件实现主机名的解析。如果机器很多的话,可以使用 DNS 进行解析。
[root@master ~]# vim /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.37.111 master.keer.com
192.168.37.122 server1.keer.com
192.168.37.133 server2.keer.com
注意,该操作需要在每一台主机上进行。修改完成以后,我们可以来测试一下是否已经成功:
[root@master ~]# ping server1.keer.com

连通性测试
3、时间同步
[root@master ~]# systemctl start chronyd.service
三台机器上都开启 chronyd.service 服务来进行时间同步,开启过后可以查看一下状态:
[root@master ~]# systemctl status chronyd.service

时间同步状态。我们可以使用chronyc sources命令来查看时间源:

查看时间源
(三)开启puppet 的master、agent 服务
1、开启服务
[root@master ~]# systemctl start puppetmaster
[root@server1 ~]# systemctl start puppetagent
[root@server2 ~]# systemctl start puppetagent
2、master 签署颁发证书
[root@master manifests]# puppet cert list
[root@master ~]# puppet cert sign server2.keer.com

master 颁发证书
(四)配置站点清单
[root@master manifests]# cd /etc/puppet/manifests
[root@master manifests]# vim site.pp 直接调上边完成的模块
node 'server1.keer.com' {
include redis::master
}
node 'server2.keer.com' {
class{'redis::slave':
master_ip => 'server1.keer.com'
}
}
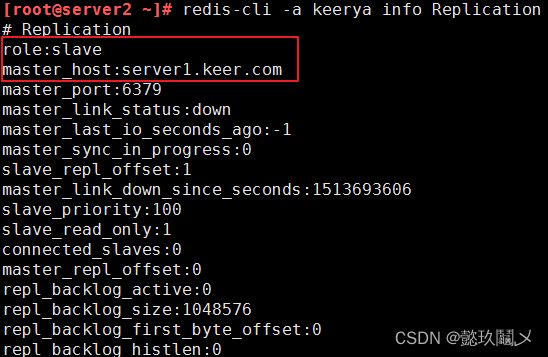
(五)检测主从架构
[root@server2 ~]# vim /etc/redis.conf

检测主从架构
[root@server2 ~]# redis-cli -a keerya info Replication
(六)再添加个模块准备配置进站点清单
1、创建一个 chrony 模块,前准备
[root@master ~]# cd modules/ 进入模块工作目录
[root@master modules]# mkdir chrony 创建chrony 的模块
[root@master modules]# mkdir chrony/{manifests,files} -pv 创建模块结构
2、配置chrony 模块
[root@master modules]# cd chrony/
[root@master chrony]# cp /etc/chrony.conf files/
[root@master puppet]# vim files/chrony.conf
# test #用于测试实验结果

添加一行
[root@master chrony]# vim manifests/init.pp
class chrony {
package{'chrony':
ensure => installed
} ->
file{'/etc/chrony.conf':
ensure => file,
source => 'puppet:///modules/chrony.conf',
owner => 'root',
group => 'root',
mode => '0644'
} ~>
service{'chronyd':
ensure => running,
enable => true,
hasrestart => true,
hasstatus => true
}
}
3、puppet 添加这个模块,并生效
[root@master modules]# cp -rp chrony/ /etc/puppet/modules/
[root@master modules]# puppet module list

查看 puppet 模块列表
(七)再配置站点清单
[root@master ~]# cd /etc/puppet/manifests/
[root@master manifests]# vim site.pp
node 'base' {
include chrony
}
node 'server1.keer.com' inherits 'base' {
include redis::master
}
node 'server2.keer.com' inherits 'base' {
class{'redis::slave':
master_ip => 'server1.keer.com'
}
}
#node /cache[1-7]+\.keer\.com/ { #可以用正则匹配多个服务器使用模块
# include varnish
#}
(八)测试
我们现在直接去 server2 机器上,查看我们的配置文件是否已经生效,是否是我们添加过一行的内容:
[root@server2 ~]# vim /etc/chrony.conf

server2 上的内容,发现我们的实验成功。