全国大数据与计算智能挑战赛:面向低资源的命名实体识别基线方案,排名13/64
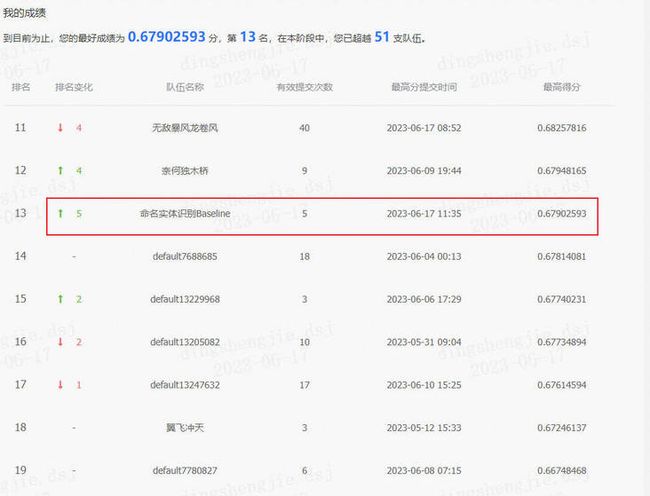
全国大数据与计算智能挑战赛:面向低资源的命名实体识别baseline,排名13/64。第一名:0.68962791,基线:0.67902593 ,感兴趣小伙伴可以刷刷榜。 国防科技大学系统工程学院(大数据与决策实验室)

项目链接以及本地码源见文末
1.赛题介绍
- 大赛背景
全国大数据与计算智能挑战赛是由国防科技大学系统工程学院大数据与决策实验室组织的年度赛事活动,旨在深入挖掘大数据应用实践中亟需的能力生成难题,选拔汇聚数据领域优势团队,促进大数据领域的技术创新和面向需求的成果生成,推动形成 “集智众筹、联合攻关、共享共用” 的研建用一体迭代演进创新模式。
本届大赛以 “发榜挑战、集智攻关” 为主题,面向全国大数据与计算智能领域的相关单位,将围绕自然语言处理、图像检测识别、时空数据分析、知识建模分析等前沿技术难点开设赛道,以 “揭榜打擂” 的形式组织创研竞赛,通过线上打榜与现场评审相结合的方式决出优势团队,进一步创新大数据管理与应用模式,推动大数据与计算智能领域技术发展与生态构建。
热烈欢迎全国各工业部门、科研院所、各高校及民营企业的业内优势团队踊跃参赛揭榜!
了解更多赛事信息 2023 全国大数据与计算智能挑战赛
- 赛题介绍
• 赛题名称
面向低资源和增量类型的命名实体识别
• 赛题背景
命名实体识别是自然语言处理领域中的重要上游任务,其目标是从文本中识别出具有特定意义的实体,包括人物、地点、组织机构等。近年来,基于深度学习模型的命名实体识别技术取得了突出的成果,但仍然存在依赖大规模标注数据、无法增量地学习新类型等问题,使得大部分现有模型和方法难以满足实际需求。
本赛题面向装备领域的信息抽取业务场景,针对现有命名实体识别技术的不足,设置低资源实体识别和持续实体识别两类赛题任务:低资源实体识别任务仅提供少量训练样本,不允许参赛者使用外部数据,重点考察参赛系统的小样本泛化能力;持续实体识别任务提供一个相互之间实体类型不重叠的实体识别任务序列,参赛系统需要连续地学习每个任务中的实体类型并保持在学过类型上的性能,主要考察参赛系统的持续学习能力。
• 初赛任务:低资源命名实体识别
参赛系统需要学习一个低资源训练集,每种实体类型仅涉及 50 个左右的样本案例,并在规模更大的测试集上取得较好的性能。各类型训练样本数非常少,并且由于同属于武器装备概念,不同类型上下文相似,具有一定的迷惑性。
示例:
输入:{
“sample_id”:23,
“text”:“据 BAE 系统公司消息,英国领导的暴风战斗机项目在概念和评估阶段取得了良好进展,英国国防部将在未来几周内授予一份合同,开展项目的下一阶段工作。”
}
输出:{
sample_id": 23,
“text”: “暴风战斗机”,
“type”: “战斗机”,
“start”: 14,
“end”: 19
}
• 复赛任务:持续命名实体识别
参赛系统需要连续地学习一个实体识别任务序列,每个任务拥有独立的数据集,每个任务仅涉及一个实体类型。参赛系统每学完一个任务,就在当前任务以及所有学习过的历史任务的测试集上进行测试。参赛系统既要在当前任务取得良好性能,也要保证在历史任务上的性能退化尽可能少。
输入输出示例:详见 “数据与评测” 页面
1.1 效果展示
2.数据简介
本赛题采用的数据聚焦装备领域,主要从以下三个方面的来源收集整理得到,具有一定的权威性和领域价值:
开源资讯:对国内外主流新闻网站、百度百科、维基百科、武器大全等开源资讯网站进行数据收集,优先收集中文,并将外文数据进行翻译后获得情报数据;
智库报告:从智库网站中获取含有装备情报信息的论文以及报告;
内部成果:通过国内军工企业、研究院所、国内综合图书馆、数字图书馆、军工院所图书馆等内部网站获取成果相关的文件进行分析和整理。
本赛题从上述来源收集到充足原始无标注数据后,先结合人工排查和关键字匹配等自动化方法过滤偏离主题、不真实和有偏见的数据;随后清洗无效和非法字符并过滤篇幅较长以及不含领域实体的文本;其次采用参考权威装备标准与论著制定的标签体系对文本进行标注,并采用相关领域以往研究成果中的模型对数据进行预打标;最终统计筛选出类型分布符合任务需求的样本作为原始数据集。
2.1 数据说明
• 初赛数据说明
该赛题数据集共计约 6000 条样本,包含以下 9 种实体类型:飞行器, 单兵武器, 炸弹, 装甲车辆, 火炮, 导弹, 舰船舰艇, 太空装备, 其他武器装备。参考低资源学习领域的任务设置,为每种类型从原始数据集中采样 50 个左右样本案例,形成共 97 条标注样本的训练集(每一条样本可能包含多个实体和实体类型),其余样本均用于测试集。所有数据文件编码均为 UTF-8。
| 文件类型 | 文件名 | 文件说明 |
|---|---|---|
训练集 |
ner_train.json | 97 条已标注样本,每个样本对应内容为:样本 id(sample_id),原始文本(text)和标注实体列表(annotations),列表中每个元素对应一个实体,包括类型(type)、文本(text)、跨度起始位置(start)和结束位置(end) |
| 测试集 | ner_test.json | 5920 条未标注样本,每个样本对应内容为:样本 id(sample_id)和原始文本(text) |
| 文件类型 | 文件名 | 文件说明 |
|---|---|---|
训练集 |
#task_id#_ner_train.json | 平均每个任务有自己的数据集,每个文件的命名以任务 id 开头,格式为 #task_id#_ner_train.json,下同。平均每个任务约 400 条样本,每条样本内容为:样本 id(sample_id),原始文本(text)和标注实体列表(entities),列表中每个元素对应一个实体,包括类型(type)、文本(text)、跨度起始位置(start)和结束位置(end) |
| 验证集 | #task_id#_ner_dev.json | 平均每个任务约 70 条样本,样式同训练集 |
| 测试集 | #task_id#_ner_test.json | 平均每个任务约 200 条样本,每条样本内容为:样本 id(sample_id)和原始文本(text) |
` [… { "sample_id": 317, "text": "歼-20", "type": "飞行器" "start": 20, "end": 24, } { "sample_id": 318, "text": "F-100级护卫舰", "type": "舰船舰艇", "start": 8, "end": 17 } …] ` 复赛提交示例 参赛者以多个 json 文件格式提交测试结果,每个文件对应一个对象数组,数组的每一个对象内容包括:目前刚学完任务的 id(current_task_id)、测试样本所属任务的 id(test_task_id)、测试样本 id(sample_id),预测结果列表(每个元素包括:对应文本 text,跨度起始位置 start,跨度结束位置 end,类型 type)。每个文件对应模型在一个任务顺序上的结果,命名为 “#seq_id#_ner_results.json”,#seq_id# 表示任务顺序的 id,所有测试结果文件保存在“results” 目录下。文件编码为 UTF-8。 示例: ` [… { "current_task_id": 5, "test_task_id": 4, "sample_id": 27, "text": "辽宁号", "start": 20, "end": 23, "type": "舰船舰艇" } …] ` ## 2.3 评测标准 初赛评测标准 本赛题采用精确匹配的 macro-F1 分数作为评测和排名指标,即预测出的类型和实体跨度都与 ground-truth 精确匹配才算正确,并同时考虑模型在所有类型上的综合表现能力,满分 100,分值越大排名越高。macro-F1 的计算公式如下: macro −F1=91i=1∑9 F1i 每一种类型对应的 F1 值的计算方式为: F1=2∗P+RP∗R 其中: P = 预测正确实体数量 / 预测出的实体数量 ×100% R = 预测正确实体数量 / 样本中的实体数量 ×100% 注意:评测标准中判断模型预测的正误是以实体为单位,而不是以样本为单位的。 复赛评测标准 本赛题的评测指标及其计算步骤如下: • 对于长度为 N 的任务序列,模型每次学完一个任务 Ti(i 即提交示例中的 “current_task_id”)后,在 T1 ~ Ti的测试集上进行测试得到一系列 F1 分数 F1i,j(1≤j≤i)(j 即提交示例中的 “test_task_id”),对其求均值得到 F1(i)=i1∑j=1iF1i,j; • 学完所有任务后得到每个阶段的性能 F1(1)∼F1(N),求其均值 F1N=N1∑i=1NF1(i),用于总结模型的整个学习曲线; • 为了排除任务顺序对性能的影响,每个序列前面的序号即为前述 seq_id,序列元素表示任务 id: > 1. 1-2-3-4-5-6 > 2. 2-4-6-1-3-5 > 3. 3-1-5-2-6-4 > 4. 4-6-2-5-1-3 > 5. 5-3-1-6-4-2 > 6. 6-5-4-3-2-1 复赛指标计算示例: 给定一个共有 3 个任务(N=3)的任务序列,对于顺序 “T1 - T2 - T3”, 指标计算的过程如下表所示,每个表项中的数值为模型学完任务 Ti(i 即提交示例中的 “current_task_id”)后在 Tj(1≤j≤i)(j 即提交示例中的 “test_task_id”)上的 F1 分数 F1i,j:  最终该任务顺序的 F1N=3F1(1)+F1(2)+F1(3)=380+72+64=72; 假设在另外两个顺序 “T3 - T1 - T2” 和 “T2 - T3 - T1” 上的结果为 68 和 70,则最终结果为 372+68+70=70
最终该任务顺序的 F1N=3F1(1)+F1(2)+F1(3)=380+72+64=72; 假设在另外两个顺序 “T3 - T1 - T2” 和 “T2 - T3 - T1” 上的结果为 68 和 70,则最终结果为 372+68+70=70 `python #使用最新版本paddlenlp !pip install -U paddlenlp ` # 3. 数据转换 经过转换的数据已放在data_all 目录下,直接使用即可。 `python #移动数据到指定目录 !cp /home/aistudio/data_all/* /home/aistudio/data ` # 4.面向低资源和增量类型的命名实体识别 ## 4.1 数据切分/构造负样本 信息抽取是从非结构化或半结构化文本数据中提取结构化的信息,可以使用以下几种方法进行负样本构建: * 随机选取方法:随机选择文本数据中不包含目标信息的部分作为负样本。 * 反例生成法:根据真实数据中不属于目标信息的特征构建虚拟的负样本。例如,在提取人名时,将所有非人名部分作为虚拟负样本。 * 噪声扰动法:向正样本中添加噪声或错误信息,使得模型能够区分出正确的信息和错误的信息。 * 无关语料库采样法:从与正样本不同的领域或主题的语料库中随机选取一些数据作为负样本。 需要注意的是,在进行负样本构建时应尽量保证构建出来的负样本与正样本在数据分布上的差异不会过大,以确保模型有足够的泛化能力。同时,也要考虑到负样本数量的影响,一般情况下需要与正样本数量保持相对平衡。 部分结果展示: ` {"content": "美国陆军与通用动力公司的武器与技术生产部门签订了两份合约,包括一份价值2.104亿美元的70毫米海德拉航空火箭弹生产合约和一份价值1350万美元的用于70毫米海德拉火箭弹保障项目的技术维护合约。这两份合约由位于阿拉巴马州红石兵工厂的美国陆军合约司令部授予。该合约的最终交货期限预计为2015年早期。自1996年开始,通用动力公司就是海德拉火箭弹的系统集成商。通用动力公司的发言人称:通用动力公司为美国军队及其亲密盟友提供海德拉火箭弹已经超过15年了。对该项目的长期管理经验使得我们能够更紧密的与美国陆军合作以提供这种廉价而可靠地武器。海德拉火箭弹由两个主要部件组成:MK66火箭发动机和战斗部。该火箭弹的战斗部有多种类型以满足不同任务的需要。该70毫米火箭弹可用于大部分直升机和部分飞机上。", "result_list": [{"text": "70毫米海德拉航空火箭弹", "start": 44, "end": 56}, {"text": "70毫米海德拉火箭弹", "start": 75, "end": 85}, {"text": "海德拉火箭弹", "start": 166, "end": 172}, {"text": "海德拉火箭弹", "start": 210, "end": 216}, {"text": "海德拉火箭弹", "start": 267, "end": 273}], "prompt": "炸弹"} {"content": "据联合早报莫斯科9月5日报道:俄罗斯一名海军上将为库尔斯克号核潜艇上个月沉没提出新的解释。他说,该潜艇可能首先被另一艘战舰发射的导弹击中。俄罗斯波罗的海舰队司令叶戈罗夫说,这样的攻击行动是调查人员研究的好几个看法之一。他说,如果该潜艇被击中,那肯定是我们的一艘战舰发射的鱼雷。", "result_list": [], "prompt": "装甲车辆"} ` ## 2.2 模型微调 推荐使用 Trainer API 对模型进行微调。只需输入模型、数据集等就可以使用 Trainer API 高效快速地进行预训练、微调和模型压缩等任务,可以一键启动多卡训练、混合精度训练、梯度累积、断点重启、日志显示等功能,Trainer API 还针对训练过程的通用训练配置做了封装,比如:优化器、学习率调度等。 使用下面的命令,使用 uie-base 作为预训练模型进行模型微调,将微调后的模型保存至$finetuned_model: ### 2.2.1 微调小技巧 * Warmup:学习率更新策略 Warmup原理指的是在训练神经网络模型时,通过逐渐增大学习率来提高模型的训练效果。在模型训练开始的阶段,逐步增加学习率的大小,直到达到预设最大值,然后再保持不变。这个过程可以让模型逐渐从初始状态进入到稳定状态,避免在训练初期出现较大的震荡或梯度爆炸等情况,同时也能加速模型训练过程。在实际应用中通常会采用一些特定的warmup策略,如线性递增、多项式递增等,在一定程度上可以提升模型的性能表现。此外,还可以结合其他技巧,如批归一化、dropout等,来进一步改善模型的训练效果。 * 线性调整策略(linear):在每个训练步骤中将学习率按线性递减的方式进行衰减,直到达到最小值。该策略通常适用于训练过程稳定的场景。 * 余弦退火策略(cosine):根据余弦函数的曲线进行学习率的动态调整,先从较大的学习率开始逐步下降,然后在训练周期的后半部分加快调整速度,使得学习率更快地衰减,并且在训练完成前接近于0。该策略可以帮助提高模型的精度和稳定性。 * 固定学习率策略(constant):在整个训练过程中保持不变的学习率,适用于数据集较小,训练较快的场景。 * 温暖启动固定学习率策略(constant_with_warmup):该策略先使用较小的学习率进行预热,在一定步数内逐渐增加学习率,然后在剩余训练步数内使用较大的学习率进行训练。预热可以帮助模型在刚开始训练时更好地适应数据集,加快学习速度和提高模型精度。 Warmup ratio的大小主要取决于训练数据的规模,模型的复杂度和任务的难度等因素。通常来说,warmup_ratio设置为0.1左右比较合适。这意味着,在整个训练过程中,模型的前10%的迭代次数将会采用相对较小的学习率进行warmup。 >需要注意的是,如果warmup_ratio设置过大,可能会导致模型在warmup阶段花费过多时间,从而影响整个训练过程的进展。反之,如果warmup_ratio设置过小,则可能无法充分调整模型参数,导致模型训练不稳定,或者出现梯度爆炸等问题。因此,需要根据具体情况,合理地设置warmup_ratio的大小,以达到最佳的训练效果。 * 正则化(Regularization) 权重衰减/权重衰退:Weight Decay是一个正则化技术,作用是抑制模型的过拟合,以此来提高模型的泛化性。它是通过给损失函数增加模型权重L2范数的惩罚(penalty)来让模型权重不要太大,以此来减小模型的复杂度,从而抑制模型的过拟合。除了所有bias和 LayerNorm 权重之外,应用于所有层的权重衰减数值,在训练期间对模型的权重施加额外惩罚(通常是 L2 正则化)来防止过度拟合。 * weight decay 的最佳值通常取决于数据集和模型本身。不同的模型和数据集可能对 weight decay 有不同的敏感度。如果 weight decay 设置太低,则模型可能会过度拟合;如果设置太高,则可能会导致模型对训练数据的拟合能力较差。 * 建议使用网格搜索或交叉验证等技术来选择最佳的 weight decay 值通常建议尝试一组设置,例如 [1e-6,1e-5, 1e-4, 1e-3, 1e-2],并根据交叉验证性能选择最佳结果。 * `python #单卡训练 !python finetune.py \ --device gpu \ --logging_steps 100 \ --save_steps 100 \ --eval_steps 100 \ --seed 1000 \ --model_name_or_path uie-base\ --output_dir ./checkpoint/model_best \ --train_path data/train.txt \ --dev_path data/dev.txt \ --max_seq_len 512 \ --per_device_train_batch_size 32 \ --per_device_eval_batch_size 32 \ --num_train_epochs 20 \ --learning_rate 1e-5 \ --label_names "start_positions" "end_positions" \ --do_train \ --do_eval \ --do_export \ --export_model_dir ./checkpoint/model_best \ --overwrite_output_dir \ --disable_tqdm True \ --metric_for_best_model eval_f1 \ --load_best_model_at_end True \ --lr_scheduler_type "cosine" \ --warmup_ratio 0.15 \ --weight_decay 1e-6 \ --save_total_limit 1 ` 部分结果展示: * eval_f1 = 0.9674 ` [2023-06-17 11:12:16,916] [ INFO] - eval metrics [2023-06-17 11:12:16,916] [ INFO] - epoch = 20.0 [2023-06-17 11:12:16,916] [ INFO] - eval_f1 = 0.9674 [2023-06-17 11:12:16,916] [ INFO] - eval_loss = 0.0002 [2023-06-17 11:12:16,916] [ INFO] - eval_precision = 0.9653 [2023-06-17 11:12:16,916] [ INFO] - eval_recall = 0.9695 [2023-06-17 11:12:16,916] [ INFO] - eval_runtime = 0:00:10.49 [2023-06-17 11:12:16,916] [ INFO] - eval_samples_per_second = 64.624 [2023-06-17 11:12:16,916] [ INFO] - eval_steps_per_second = 2.097 [2023-06-17 11:12:16,918] [ INFO] - Exporting inference model to ./checkpoint/model_best/model [2023-06-17 11:12:22,862] [ INFO] - Inference model exported. [2023-06-17 11:12:22,863] [ INFO] - tokenizer config file saved in ./checkpoint/model_best/tokenizer_config.json [2023-06-17 11:12:22,863] [ INFO] - Special tokens file saved in ./checkpoint/model_best/special_tokens_map.json ` 注意:如果模型是跨语言模型 UIE-M,还需设置 --multilingual。 该示例代码中由于设置了参数 --do_eval,因此在训练完会自动进行评估。 可配置参数说明: * model_name_or_path:必须,进行 few shot 训练使用的预训练模型。可选择的有 "uie-base"、 "uie-medium", "uie-mini", "uie-micro", "uie-nano", "uie-m-base"。 * device: 训练设备,可选择 'cpu'、'gpu'、'npu' 其中的一种;默认为 GPU 训练。 * logging_steps: 训练过程中日志打印的间隔 steps 数,默认10。 * save_steps: 训练过程中保存模型 checkpoint 的间隔 steps 数,默认100。 * eval_steps: 训练过程中保存模型 checkpoint 的间隔 steps 数,默认100。 * seed:全局随机种子,默认为 42。 * output_dir:必须,模型训练或压缩后保存的模型目录;默认为 None 。 * train_path:训练集路径;默认为 None 。 * dev_path:开发集路径;默认为 None 。 * max_seq_len:文本最大切分长度,输入超过最大长度时会对输入文本进行自动切分,默认为512。 * per_device_train_batch_size:用于训练的每个 GPU 核心/CPU 的batch大小,默认为8。 * per_device_eval_batch_size:用于评估的每个 GPU 核心/CPU 的batch大小,默认为8。 * num_train_epochs: 训练轮次,使用早停法时可以选择 100;默认为10。 * learning_rate:训练最大学习率,UIE-X 推荐设置为 1e-5;默认值为3e-5。 * weight_decay:除了所有 bias 和 LayerNorm 权重之外,应用于所有层的权重衰减数值。可选;默认为 0.0; * label_names:训练数据标签label的名称,UIE-X 设置为'start_positions' 'end_positions';默认值为None。 * do_train:是否进行微调训练,设置该参数表示进行微调训练,默认不设置。 * do_eval:是否进行评估,设置该参数表示进行评估,默认不设置。 * do_export:是否进行导出,设置该参数表示进行静态图导出,默认不设置。 * export_model_dir:静态图导出地址,默认为None。 * overwrite_output_dir: 如果 True,覆盖输出目录的内容。如果 output_dir 指向检查点目录,则使用它继续训练。 * disable_tqdm: 是否使用tqdm进度条。 * metric_for_best_model:最优模型指标,UIE-X 推荐设置为 eval_f1,默认为None。 * load_best_model_at_end:训练结束后是否加载最优模型,通常与metric_for_best_model配合使用,默认为False。 * save_total_limit:如果设置次参数,将限制checkpoint的总数。删除旧的checkpoints 输出目录,默认为None。 ## 2.3 模型评估 评估方式说明:采用单阶段评价的方式,即关系抽取、事件抽取等需要分阶段预测的任务对每一阶段的预测结果进行分别评价。验证/测试集默认会利用同一层级的所有标签来构造出全部负例。 可开启debug模式对每个正例类别分别进行评估,该模式仅用于模型调试: `python !python evaluate.py \ --model_path ./checkpoint/model_best \ --test_path ./data/dev.txt \ --batch_size 8 \ --device gpu \ --max_seq_len 512 ` [2023-06-17 11:12:59,278] [ INFO] - We are using `python #debug !python evaluate.py \ --model_path ./checkpoint/model_best \ --test_path ./data/dev.txt \ --debug ` [2023-06-17 11:13:18,817] [ INFO] - We are using device: 评估设备,可选择 'cpu'、'gpu'、'npu' 其中的一种;默认为 GPU 评估。 - model_path: 进行评估的模型文件夹路径,路径下需包含模型权重文件model_state.pdparams及配置文件model_config.json。 - test_path: 进行评估的测试集文件。 - batch_size: 批处理大小,请结合机器情况进行调整,默认为16。 - max_seq_len: 文本最大切分长度,输入超过最大长度时会对输入文本进行自动切分,默认为512。 - debug: 是否开启debug模式对每个正例类别分别进行评估,该模式仅用于模型调试,默认关闭。 - multilingual: 是否是跨语言模型,默认关闭。 - schema_lang: 选择schema的语言,可选有ch和en。默认为ch,英文数据集请选择en。 部分结果展示: ` [2023-06-16 19:50:40,632] [ INFO] - [2023-06-16 19:50:40,632] [ INFO] - Class Name: all_classes [2023-06-16 19:50:40,632] [ INFO] - Evaluation Precision: 0.74713 | Recall: 0.73864 | F1: 0.74286 ` * 总共9种实体类型:飞行器, 单兵武器, 炸弹, 装甲车辆, 火炮, 导弹, 舰船舰艇, 太空装备, 其他武器装备 ` [2023-06-17 11:13:23,749] [ INFO] - Class Name: 舰船舰艇 [2023-06-17 11:13:23,749] [ INFO] - Evaluation Precision: 0.98077 | Recall: 1.00000 | F1: 0.99029 [2023-06-17 11:13:24,017] [ INFO] - ----------------------------- [2023-06-17 11:13:24,017] [ INFO] - Class Name: 其他武器装备 [2023-06-17 11:13:24,017] [ INFO] - Evaluation Precision: 0.92157 | Recall: 0.92157 | F1: 0.92157 [2023-06-17 11:13:24,263] [ INFO] - ----------------------------- [2023-06-17 11:13:24,263] [ INFO] - Class Name: 单兵武器 [2023-06-17 11:13:24,263] [ INFO] - Evaluation Precision: 0.98000 | Recall: 0.96078 | F1: 0.97030 [2023-06-17 11:13:24,591] [ INFO] - ----------------------------- [2023-06-17 11:13:24,592] [ INFO] - Class Name: 装甲车辆 [2023-06-17 11:13:24,592] [ INFO] - Evaluation Precision: 0.96078 | Recall: 0.96078 | F1: 0.96078 [2023-06-17 11:13:24,789] [ INFO] - ----------------------------- [2023-06-17 11:13:24,789] [ INFO] - Class Name: 飞行器 [2023-06-17 11:13:24,789] [ INFO] - Evaluation Precision: 1.00000 | Recall: 1.00000 | F1: 1.00000 [2023-06-17 11:13:24,993] [ INFO] - ----------------------------- [2023-06-17 11:13:24,993] [ INFO] - Class Name: 太空装备 [2023-06-17 11:13:24,993] [ INFO] - Evaluation Precision: 0.96226 | Recall: 1.00000 | F1: 0.98077 [2023-06-17 11:13:25,280] [ INFO] - ----------------------------- [2023-06-17 11:13:25,280] [ INFO] - Class Name: 导弹 [2023-06-17 11:13:25,280] [ INFO] - Evaluation Precision: 0.98000 | Recall: 0.96078 | F1: 0.97030 [2023-06-17 11:13:25,611] [ INFO] - ----------------------------- [2023-06-17 11:13:25,612] [ INFO] - Class Name: 火炮 [2023-06-17 11:13:25,612] [ INFO] - Evaluation Precision: 0.94118 | Recall: 0.94118 | F1: 0.94118 [2023-06-17 11:13:25,901] [ INFO] - ----------------------------- [2023-06-17 11:13:25,901] [ INFO] - Class Name: 炸弹 [2023-06-17 11:13:25,902] [ INFO] - Evaluation Precision: 0.96154 | Recall: 0.98039 | F1: 0.97087 ` ## 2.4 模型预测 paddlenlp.Taskflow装载定制模型,通过task_path指定模型权重文件的路径,路径下需要包含训练好的模型权重文件model_state.pdparams。 相关bug:KeyError: 'sentencepiece_model_file' 同一个脚本先加载uie-x,再加载uie,报错KeyError: 'sentencepiece_model_file':https://github.com/PaddlePaddle/PaddleNLP/issues/5795 #加载过uiem之后不能加载uie模型:https://github.com/PaddlePaddle/PaddleNLP/issues/5615 1. 修复加载最新版本paddlenlp重启内核即可 2. 重启项目,先加载uie,再加在uie-x则不出错 `python # !pip install --pre --upgrade paddlenlp -f https://www.paddlepaddle.org.cn/whl/paddlenlp.html ` `python !pip install fast-tokenizer-python ` Looking in indexes: https://pypi.tuna.tsinghua.edu.cn/simple Requirement already satisfied: fast-tokenizer-python in /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages (1.0.2) [notice] A new release of pip available: 22.1.2 -> 23.1.2 [notice] To update, run: pip install --upgrade pip position_prob是指模型对于span的起始位置和终止位置的结果得分。由于这是一个得分,所以它的取值范围在0~1之间,0表示完全不可能成为起始位置或终止位置,1表示完全符合条件。默认情况下,我们将得分高于0.5的结果视为有效结果,否则视为无效结果。 最终,我们需要通过起始位置和终止位置的得分,计算出整个span的得分。这个得分可以看作是起始位置概率和终止位置概率的乘积,因为只有当两个概率都高时,才能说明这个span的得分比较高。如果有一个位置的得分很低,那么整个span的得分也会相应降低。 `python from pprint import pprint from paddlenlp import Taskflow schema = {"飞行器","单兵武器", "炸弹", "装甲车辆","其他武器装备","太空装备","舰船舰艇","导弹","火炮"} my_ie = Taskflow("information_extraction", schema=schema,batch_size=16,task_path='./checkpoint/model_best',model="uie-base",precision='fp32',position_prob=0.55) # my_ie = Taskflow("information_extraction", schema=schema,schema_lang="zh",batch_size=32,task_path='./checkpointx/model_best',model="uie-m-large") pprint(my_ie("第五艘西班牙海军F-100级护卫舰即将装备集成通信控制系统。该系统由葡萄牙EID公司生产。该系统已经用于巴西海军的圣保罗航母,荷兰海军的四艘荷兰级海上巡逻舰和四艘西班牙海军BAM近海巡逻舰。F-105护卫舰于2009年初铺设龙骨。该舰预计2010年建造完成,2012年夏交付。")) pprint(my_ie("美国空军部长希瑟・威尔逊本周二宣布,Space-X公司将于8月份发射空军X-37B无人轨道机动飞行器。而在前4次轨道试验任务中,X-37B由联合发射联盟的宇宙神-5火箭发射。威尔逊在网络直播的参议院军事委员会听证会上表示,Space-X公司将于8月份发射空军有效载荷进入轨道,该载荷为空军两架X-37B飞行器之一。空军在X-37B发射前2个月公布发射合同,而通常是在发射前2年公布,并且拒绝披露合同授予日期及其他细节。SpaceX总裁GwynneShotwell拒绝置评。")) ` [2023-06-17 11:17:46,069] [ INFO] - loading configuration file ./checkpoint/model_best/config.json [2023-06-17 11:17:46,072] [ INFO] - Model config ErnieConfig { "architectures": [ "UIE" ], "attention_probs_dropout_prob": 0.1, "dtype": "float32", "enable_recompute": false, "fuse": false, "hidden_act": "gelu", "hidden_dropout_prob": 0.1, "hidden_size": 768, "initializer_range": 0.02, "intermediate_size": 3072, "layer_norm_eps": 1e-12, "max_position_embeddings": 2048, "model_type": "ernie", "num_attention_heads": 12, "num_hidden_layers": 12, "pad_token_id": 0, "paddlenlp_version": null, "pool_act": "tanh", "task_id": 0, "task_type_vocab_size": 3, "type_vocab_size": 4, "use_task_id": true, "vocab_size": 40000 } [2023-06-17 11:17:47,827] [ INFO] - All model checkpoint weights were used when initializing UIE. [2023-06-17 11:17:47,830] [ INFO] - All the weights of UIE were initialized from the model checkpoint at ./checkpoint/model_best. If your task is similar to the task the model of the checkpoint was trained on, you can already use UIE for predictions without further training. [2023-06-17 11:17:47,833] [ INFO] - Converting to the inference model cost a little time. [2023-06-17 11:17:54,964] [ INFO] - The inference model save in the path:./checkpoint/model_best/static/inference [2023-06-17 11:17:56,936] [ INFO] - We are using ` [{'舰船舰艇': [{'end': 103, 'probability': 0.9993847362591879, 'start': 95, 'text': 'F-105护卫舰'}, {'end': 17, 'probability': 0.9561809895684519, 'start': 8, 'text': 'F-100级护卫舰'}, {'end': 94, 'probability': 0.6309098078362751, 'start': 86, 'text': 'BAM近海巡逻舰'}, {'end': 78, 'probability': 0.9929937742996913, 'start': 70, 'text': '荷兰级海上巡逻舰'}, {'end': 62, 'probability': 0.9938209366804145, 'start': 57, 'text': '圣保罗航母'}]}] [{'太空装备': [{'end': 84, 'probability': 0.5503150068932996, 'start': 77, 'text': '宇宙神-5火箭'}], '飞行器': [{'end': 69, 'probability': 0.9939817925809464, 'start': 64, 'text': 'X-37B'}, {'end': 154, 'probability': 0.884662710696297, 'start': 146, 'text': 'X-37B飞行器'}, {'end': 165, 'probability': 0.9965047226514798, 'start': 160, 'text': 'X-37B'}, {'end': 50, 'probability': 0.9932846224923821, 'start': 34, 'text': '空军X-37B无人轨道机动飞行器'}]}] ` * schema:定义任务抽取目标,可参考开箱即用中不同任务的调用示例进行配置。 * schema_lang:设置schema的语言,默认为zh, 可选有zh和en。因为中英schema的构造有所不同,因此需要指定schema的语言。该参数只对uie-m-base和uie-m-large模型有效。 * batch_size:批处理大小,请结合机器情况进行调整,默认为1。 * model:选择任务使用的模型,默认为uie-base,可选有uie-base, uie-medium, uie-mini, uie-micro, uie-nano和uie-medical-base, uie-base-en。 * position_prob:模型对于span的起始位置/终止位置的结果概率在0~1之间,返回结果去掉小于这个阈值的结果,默认为0.5,span的最终概率输出为起始位置概率和终止位置概率的乘积。 * precision:选择模型精度,默认为fp32,可选有fp16和fp32。fp16推理速度更快,支持GPU和NPU硬件环境。如果选择fp16,在GPU硬件环境下,请先确保机器正确安装NVIDIA相关驱动和基础软件,确保CUDA>=11.2,cuDNN>=8.1.1,初次使用需按照提示安装相关依赖。其次,需要确保GPU设备的CUDA计算能力(CUDA Compute Capability)大于7.0,典型的设备包括V100、T4、A10、A100、GTX 20系列和30系列显卡等。 * use_fast: 使用C++实现的高性能分词算子FastTokenizer进行文本预处理加速。需要通过pip install fast-tokenizer-python安装FastTokenizer库后方可使用。默认为False。 `python import json from paddlenlp import Taskflow import pandas as pd #修改需要预测数据 path='/home/aistudio/input/test-5.json' # path='/home/aistudio/input/ner_test.json' with open(path, 'r', encoding='utf-8') as f: data = json.load(f) texts = [d['text'] for d in data] text_list = [' '.join(text.split()) for text in texts] text_list = [[text] for text in text_list] # 模型处理函数 schema = {"飞行器","单兵武器", "炸弹", "装甲车辆","其他武器装备","太空装备","舰船舰艇","导弹","火炮"} my_ie = Taskflow("information_extraction", schema=schema,batch_size=8,task_path='/home/aistudio/checkpoint/model_best') results=my_ie(texts) print(results) with open("output.txt", "w+",encoding='UTF-8') as f: #a : 写入文件,若文件不存在则会先创建再写入,但不会覆盖原文件,而是追加在文件末尾 for result in results: line = json.dumps(result, ensure_ascii=False) #对中文默认使用的ascii编码.想输出真正的中文需要指定ensure_ascii=False f.write(line + "\n") output = [] for i, d in enumerate(data): sample_id = d['sample_id'] text = d['text'] for key, value in results[i].items(): for v in value: output.append({ 'sample_id': sample_id, 'text': v['text'], 'type': key, 'start': v.get('start', 0), 'end': v.get('end', 0) }) # 将结果写入文件中 with open('submit.json', 'w', encoding='utf-8') as f: json.dump(output, f, ensure_ascii=False, indent=4) print("在A100下,完整结果导出时间需要12.5min+-,") ` [2023-06-18 10:37:23,636] [ INFO] - loading configuration file /home/aistudio/checkpoint/model_best/config.json [2023-06-18 10:37:23,641] [ INFO] - Model config ErnieConfig { "architectures": [ "UIE" ], "attention_probs_dropout_prob": 0.1, "dtype": "float32", "enable_recompute": false, "fuse": false, "hidden_act": "gelu", "hidden_dropout_prob": 0.1, "hidden_size": 768, "initializer_range": 0.02, "intermediate_size": 3072, "layer_norm_eps": 1e-12, "max_position_embeddings": 2048, "model_type": "ernie", "num_attention_heads": 12, "num_hidden_layers": 12, "pad_token_id": 0, "paddlenlp_version": null, "pool_act": "tanh", "task_id": 0, "task_type_vocab_size": 3, "type_vocab_size": 4, "use_task_id": true, "vocab_size": 40000 } [2023-06-18 10:37:36,648] [ INFO] - All model checkpoint weights were used when initializing UIE. [2023-06-18 10:37:36,651] [ INFO] - All the weights of UIE were initialized from the model checkpoint at /home/aistudio/checkpoint/model_best. If your task is similar to the task the model of the checkpoint was trained on, you can already use UIE for predictions without further training. [2023-06-18 10:37:36,655] [ INFO] - Converting to the inference model cost a little time. [2023-06-18 10:37:49,285] [ INFO] - The inference model save in the path:/home/aistudio/checkpoint/model_best/static/inference [2023-06-18 10:37:50,217] [ INFO] - We are using 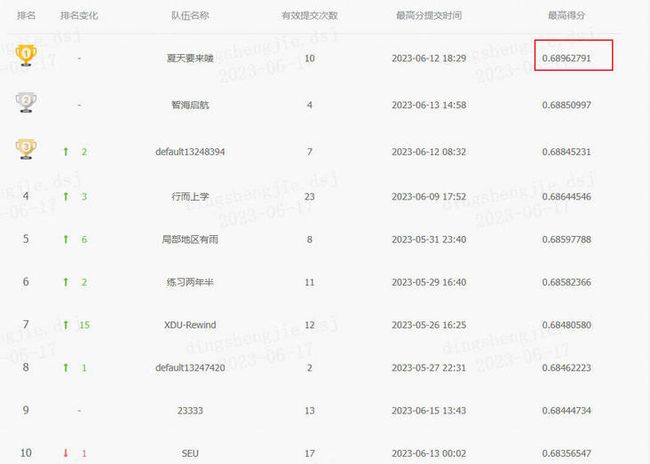 更多优质内容请关注公重号:汀丶人工智能
更多优质内容请关注公重号:汀丶人工智能
 # 项目链接以及本地码源见文末 云端项目复现链接:https://www.heywhale.com/mw/project/648e811202479f749d15842b 本地码源链接见:https://blog.csdn.net/sinat_39620217/article/details/131270249
# 项目链接以及本地码源见文末 云端项目复现链接:https://www.heywhale.com/mw/project/648e811202479f749d15842b 本地码源链接见:https://blog.csdn.net/sinat_39620217/article/details/131270249