图卷积网络概述笔记
图卷积网络概述笔记
- 谱方法
-
- Spectral graph CNN
- Chebyshev Spectral CNN (ChebNet)
- Graph Convolutional Network (GCN)
- 空间方法
-
- GraphSAGE
- Graph Attention Network (GAT)
- Mixture Model Network (MoNet)
- tips
- graph pooling
-
- graph coarsening
- node selection
开一个博客把基础概念给记录下来,随笔瞎记呗
谱方法
谱方法在谱域定义卷积操作,把图变换到谱域进行卷积之后再变换到图域。
给定无向图G=(V,E,W),点集V(n=|V|),边集E,权带权邻接矩阵 W ∈ R n × n W \in R^{n \times n} W∈Rn×n,或者就是邻接矩阵 A ∈ R n × n A \in R^{n \times n} A∈Rn×n。每个节点如果有d维特征,所有节点的特征矩阵就是 X ∈ R n × d X \in R^{n \times d} X∈Rn×d
图的拉普拉斯矩阵:L=D-W或者L=D-A,D是度矩阵 D i i = ∑ j ( A i , j ) \mathbf{D}_{i i}=\sum_{j}\left(\mathbf{A}_{i, j}\right) Dii=∑j(Ai,j),拉普拉斯矩阵定义了图上的导数(信号的平滑程度),进一步地 normalized graph laplacian:
L = I − D − 1 2 A D − 1 2 \boldsymbol{L}=\boldsymbol{I}-\boldsymbol{D}^{-\frac{1}{2}} \boldsymbol{A} \boldsymbol{D}^{-\frac{1}{2}} L=I−D−21AD−21
I是单位阵,L矩阵是实对称半正定矩阵就可以进行矩阵分解: L = U Λ U T L=U \Lambda U^{T} L=UΛUT,其中 U = [ u 1 , u 2 , ⋯ , u n ] ∈ R n × n \mathbf{U}=\left[\mathbf{u}_{\mathbf{1}}, \mathbf{u}_{\mathbf{2}}, \cdots, \mathbf{u}_{\mathbf{n}}\right] \in \mathbf{R}^{n \times n} U=[u1,u2,⋯,un]∈Rn×n,就是特征向量矩阵;而 Λ \Lambda Λ是特征值的对角矩阵 Λ = diag ( [ λ 1 , ⋯ , λ n ] ) \Lambda=\operatorname{diag}\left(\left[\lambda_{1}, \cdots, \lambda_{n}\right]\right) Λ=diag([λ1,⋯,λn]),这一组特征向量相互正交( U T U = 1 U^{T}U=1 UTU=1),把这些特征向量作为一组正交基,对图信号 x ∈ R n x \in R^n x∈Rn进行傅里叶变换: x ^ = U T x \widehat{\boldsymbol{x}}=\boldsymbol{U}^{T} \boldsymbol{x} x =UTx,对应反变换: x = U x ^ \boldsymbol{x}=\boldsymbol{U}\widehat{\boldsymbol{x}} x=Ux 。
对于输入信号 x ∈ R n x \in R^{n} x∈Rn,滤波器 g ∈ R n g \in R^{n} g∈Rn的卷积操作就可以在谱域下定义为:
x ∗ G y = U ( ( U T x ) ⊙ ( U T g ) ) x *_{G} y=U\left(\left(\boldsymbol{U}^{T} \boldsymbol{x}\right) \odot\left(\boldsymbol{U}^{T} g\right)\right) x∗Gy=U((UTx)⊙(UTg))
⊙ \odot ⊙表示点乘,而 U T x ∈ R n × 1 \boldsymbol{U}^{T} \boldsymbol{x} \in R^{n\times1} UTx∈Rn×1,可以设 U T g = [ θ 1 , ⋯ , θ n ] T \boldsymbol{U}^{T} g=\left[\boldsymbol{\theta}_{1}, \cdots, \boldsymbol{\theta}_{n}\right]^{T} UTg=[θ1,⋯,θn]T,同时设 g θ = diag ( [ θ 1 , ⋯ , θ n ] ) g_{\theta}=\operatorname{diag}\left(\left[\theta_{1}, \cdots, \theta_{n}\right]\right) gθ=diag([θ1,⋯,θn]),就可以将上式的点积变成矩阵乘积:
x ∗ G y = U g θ U T x x *_{G} y=U g_{\theta} U^{T} x x∗Gy=UgθUTx
Spectral graph CNN
按照上面的卷积操作就可以按层设计谱域的卷积神经网络:
H : , j ( k ) = σ ( ∑ i = 1 f k − 1 U Θ i , j ( k ) U T H : , i ( k − 1 ) ) ( j = 1 , 2 , ⋯ , f k ) \mathbf{H}_{:, j}^{(k)}=\sigma\left(\sum_{i=1}^{f_{k-1}} \mathbf{U} \Theta_{i, j}^{(k)} \mathbf{U}^{T} \mathbf{H}_{:, i}^{(k-1)}\right) \quad\left(j=1,2, \cdots, f_{k}\right) H:,j(k)=σ(i=1∑fk−1UΘi,j(k)UTH:,i(k−1))(j=1,2,⋯,fk)
卷积核就是 g θ = Θ i , j ( k ) \mathbf{g}_{\theta}=\Theta_{i, j}^{(k)} gθ=Θi,j(k),这里的图信号就是多维度的,k是卷积层index, H : , i ( k − 1 ) ∈ R n × f k − 1 \mathbf{H}_{:, i}^{(k-1)} \in R^{n \times f_{k-1}} H:,i(k−1)∈Rn×fk−1是输入图信号( H ( 0 ) = X \mathbf{H}^{(0)}=\mathbf{X} H(0)=X), f k − 1 f_{k-1} fk−1和 f k f_{k} fk就是输入、输出通道数。但是矩阵的特征分解具有 O ( n 3 ) O(n^{3}) O(n3)的复杂度,同时得到的U是稠密的,计算代价太高。
Chebyshev Spectral CNN (ChebNet)
通过多项式函数近似,参数化谱域卷积核:
g θ = ∑ i = 0 K θ i T i ( Λ ~ ) \mathbf{g}_{\theta}=\sum_{i=0}^{K} \theta_{i} T_{i}(\tilde{\boldsymbol{\Lambda}}) gθ=i=0∑KθiTi(Λ~)
其中 Λ ~ = 2 Λ / λ max − I n \tilde{\Lambda}=2 \mathbf{\Lambda} / \lambda_{\max }-I_{n} Λ~=2Λ/λmax−In, Λ ∈ [ − 1 , 1 ] \mathbf{\Lambda} \in [-1,1] Λ∈[−1,1],这样的话参数的个数从n减少到了K, T i T_{i} Ti通过切比雪夫多项式的递推公式得到: T i ( x ) = 2 x T i − 1 ( x ) − T i − 2 ( x ) T_{i}(x)=2 x T_{i-1}(x)-T_{i-2}(x) Ti(x)=2xTi−1(x)−Ti−2(x), T 0 ( x ) = 1 T_{0}(x)=1 T0(x)=1, T 1 ( x ) = x T_{1}(x)=x T1(x)=x,那卷积公式变为
x ∗ G g θ = U ( ∑ i = 0 K θ i T i ( Λ ~ ) ) U T x \mathbf{x} *_{G} \mathbf{g}_{\theta}=\mathbf{U}\left(\sum_{i=0}^{K} \theta_{i} T_{i}(\tilde{\boldsymbol{\Lambda}})\right) \mathbf{U}^{T} \mathbf{x} x∗Ggθ=U(i=0∑KθiTi(Λ~))UTx
设 L ~ = 2 L / λ max − I n \tilde{\mathbf{L}}=2 \mathbf{L} / \lambda_{\max }-\mathbf{I}_{\mathbf{n}} L~=2L/λmax−In,有 T i ( L ~ ) = U T i ( Λ ~ ) U T T_{i}(\tilde{\mathbf{L}})=\mathbf{U} T_{i}(\tilde{\mathbf{\Lambda}}) \mathbf{U}^{T} Ti(L~)=UTi(Λ~)UT,ChebNet变成如下形式:
x ∗ G g θ = ∑ i = 0 K θ i T i ( L ~ ) x \mathbf{x} *_{G} \mathbf{g}_{\theta}=\sum_{i=0}^{K} \theta_{i} T_{i}(\tilde{\mathbf{L}}) \mathbf{x} x∗Ggθ=i=0∑KθiTi(L~)x
ChebNet定义的滤波器在空间上是局域化的,这意味着滤波器可以独立于图的大小来提取局部特征;同时也不需要显式地求解U了。
Graph Convolutional Network (GCN)
GCN是对ChebNet的一阶近似方法,假设上面的K=1且 λ max = 2 \lambda_{\max }=2 λmax=2,那么 x ∗ G g θ = ∑ i = 0 K θ i T i ( L ~ ) x \mathbf{x} *_{G} \mathbf{g}_{\theta}=\sum_{i=0}^{K} \theta_{i} T_{i}(\tilde{\mathbf{L}}) \mathbf{x} x∗Ggθ=∑i=0KθiTi(L~)x可以简化成
x ∗ G g θ = θ 0 x − θ 1 D − 1 2 A D − 1 2 x \mathbf{x} *_{G} \mathbf{g}_{\theta}=\theta_{0} \mathbf{x}-\theta_{1} \mathbf{D}^{-\frac{1}{2}} \mathbf{A} \mathbf{D}^{-\frac{1}{2}} \mathbf{x} x∗Ggθ=θ0x−θ1D−21AD−21x
再假设两个 θ \theta θ共享参数: θ 0 = − θ 1 = θ \theta_{0}=-\theta_{1}=\theta θ0=−θ1=θ:
x ∗ G g θ = θ ( I n + D − 1 2 A D − 1 2 ) x = θ A ‾ x \mathbf{x} *_{G} \mathbf{g}_{\theta}=\theta\left(\mathbf{I}_{\mathbf{n}}+\mathbf{D}^{-\frac{1}{2}} \mathbf{A} \mathbf{D}^{-\frac{1}{2}}\right) \mathbf{x}=\theta\overline{\mathbf{A}}\mathbf{x} x∗Ggθ=θ(In+D−21AD−21)x=θAx
再把单位阵和A合并起来得到 A ‾ = D ~ − 1 2 A ~ D ~ − 1 2 \overline{\mathbf{A}}=\tilde{\mathbf{D}}^{-\frac{1}{2}} \tilde{\mathbf{A}} \tilde{\mathbf{D}}^{-\frac{1}{2}} A=D~−21A~D~−21,其中 A ~ = A + I n \tilde{\mathbf{A}}=\mathbf{A}+\mathbf{I}_{\mathbf{n}} A~=A+In, D ~ i i = ∑ j A ~ i j \tilde{\mathbf{D}}_{i i}=\sum_{j} \tilde{\mathbf{A}}_{i j} D~ii=∑jA~ij。这样就得到了GCN的卷积方法:
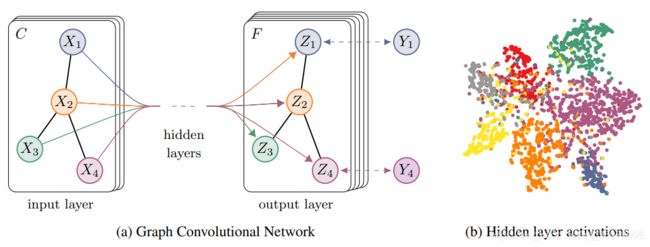
H l + 1 = f ( A ‾ H l W l ) H^{l+1}=f(\overline{\mathbf{A}}H^{l}W^{l}) Hl+1=f(AHlWl)
f f f是激活函数。同时GCN也可以看做是一种空间方法,从一阶领域节点特征进行变换和聚合(究竟完成的是特征变换还是卷积操作不清楚了)。
提出GCN的文章里设计了两层的GCN网络用于半监督节点分类任务,有两个权重矩阵W,计算最后的交叉熵。
Z = f ( X , A ) = softmax ( A ^ ReLU ( A ^ X W ( 0 ) ) W ( 1 ) ) Z=f(X, A)=\operatorname{softmax}\left(\hat{A} \operatorname{ReLU}\left(\hat{A} X W^{(0)}\right) W^{(1)}\right) Z=f(X,A)=softmax(A^ReLU(A^XW(0))W(1))
空间方法
可以类比CNN的操作过程,直接在节点域定义卷积:选择节点的邻域、邻域节点排序、参数共享。

不像图像中卷积核滑动计算的过程,图中感受野的生成节点序列和感受野的形状完全由超参数决定。首先对每一个节点而言,选择固定数量的节点作为neighborhood(定义一种邻近度量方式),然后定序计算。

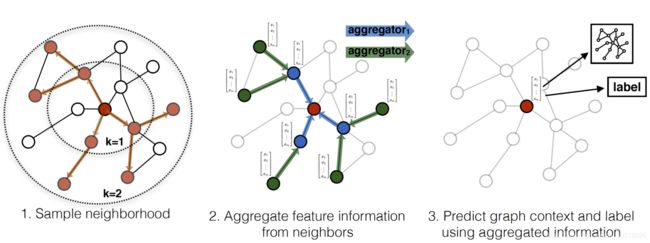
GraphSAGE
- 随机采样邻域节点
- AGGREGATE+CONCAT(combine)
Graph Attention Network (GAT)

GCN还是利用了laplacian矩阵作为信息传递或者是聚合的工具,GAT采用注意机制来学习两个连接节点之间的相对权重,把卷积操作定义为
h v ( k ) = σ ( ∑ u ∈ N ( v ) ∪ v α v u ( k ) W ( k ) h u ( k − 1 ) ) \mathbf{h}_{v}^{(k)}=\sigma\left(\sum_{u \in \mathcal{N}(v) \cup v} \alpha_{v u}^{(k)} \mathbf{W}^{(k)} \mathbf{h}_{u}^{(k-1)}\right) hv(k)=σ⎝⎛u∈N(v)∪v∑αvu(k)W(k)hu(k−1)⎠⎞
其中 h v ( 0 ) = x v \mathbf{h}_{v}^{(0)}=\mathbf{x}_{v} hv(0)=xv,注意权 α \alpha α度量两个相邻节点u之间的关联程度。
α i j = exp ( LeakyReLU ( a → T [ W h ⃗ i ∥ W h ⃗ j ] ) ) ∑ k ∈ N i exp ( LeakyReLU ( a → T [ W h ⃗ i ∥ W h ⃗ k ] ) ) \alpha_{i j}=\frac{\exp \left(\text { LeakyReLU }\left(\overrightarrow{\mathbf{a}}^{T}\left[\mathbf{W} \vec{h}_{i} \| \mathbf{W} \vec{h}_{j}\right]\right)\right)}{\sum_{k \in \mathcal{N}_{i}} \exp \left(\text { LeakyReLU }\left(\overrightarrow{\mathbf{a}}^{T}\left[\mathbf{W} \vec{h}_{i} \| \mathbf{W} \vec{h}_{k}\right]\right)\right)} αij=∑k∈Niexp( LeakyReLU (aT[Whi∥Whk]))exp( LeakyReLU (aT[Whi∥Whj]))
上式中除了特征变换参数W外还有一个参数a(权重向量),而在GCN中是由Laplacian矩阵硬性编码的。
Mixture Model Network (MoNet)
相比之下MoNet是更为一般的空间方法,定义图上的核函数,每一个核函数定义了一种度量任意两个节点相似度的方式,卷积就是对不同相似度定义的加权平均,卷积核的参数就是对应核函数的权重。在谱方法中,核函数就对应于谱变换的基,空间方法就是邻域节点的选择。
( f ⋆ g ) ( x ) = ∑ j = 1 J g j D j ( x ) f (f \star g)(x)=\sum_{j=1}^{J} g_{j} D_{j}(x) f (f⋆g)(x)=j=1∑JgjDj(x)f
g j g_{j} gj就是卷积核参数,上面包含了一个patch operator D j ( x ) f D_{j}(x) f Dj(x)f:
D j ( x ) f = ∑ y ∈ N ( x ) w j ( u ( x , y ) ) f ( y ) , j = 1 , … , J D_{j}(x) f=\sum_{y \in \mathcal{N}(x)} w_{j}(\mathbf{u}(x, y)) f(y), \quad j=1, \ldots, J Dj(x)f=y∈N(x)∑wj(u(x,y))f(y),j=1,…,J
u ( x , y ) u(x, y) u(x,y)表示关系度量(没看懂文章这部分的表述),还有加权函数(kernel): w Θ ( u ) = ( w 1 ( u ) , … , w J ( u ) ) \mathbf{w}_{\Theta}(\mathbf{u})=\left(w_{1}(\mathbf{u}), \ldots, w_{J}(\mathbf{u})\right) wΘ(u)=(w1(u),…,wJ(u)), Θ \Theta Θ是可学习参数。
tips
记一下有意思的结论:谱方法显式地定义了卷积核,而空间方法不需要;比如谱方法可以将特征投影到拉普拉斯矩阵特征向量定义的空间中,空间方法只需要kernel functions。
信号x关于graph的平滑程度可以刻画为(拉普拉斯矩阵L):
x T L x = ∑ ( u , v ) ∈ E A u v ( x u d u − x v d v ) 2 x^{T} L x=\sum_{(u, v) \in E} A_{u v}\left(\frac{x_{u}}{\sqrt{d_{u}}}-\frac{x_{v}}{\sqrt{d_{v}}}\right)^{2} xTLx=(u,v)∈E∑Auv(duxu−dvxv)2
λ i = u i T L u i \lambda_{i}=u_{i}^{T} L u_{i} λi=uiTLui可以视作 u i u_{i} ui的频率,特征值刻画了特征向量关于图的平滑程度。 u i u i T ( 1 ≤ i ≤ n ) u_{i} u_{i}^{T}(1 \leq i \leq n) uiuiT(1≤i≤n)构成了一组基本滤波器,允许频率为 λ i \lambda_{i} λi的信号通过,图上的谱卷积实际上是这组基本滤波器的线性组合:
θ 1 u 1 u 1 T + θ 2 u 2 u 2 T + ⋯ + θ n u n u n T \theta_{1} u_{1} u_{1}^{T}+\theta_{2} u_{2} u_{2}^{T}+\cdots+\theta_{n} u_{n} u_{n}^{T} θ1u1u1T+θ2u2u2T+⋯+θnununT
ChebNet实际上是带了一组系数,频率越高系数越大(加强了高频信号,不体现平滑性,高通滤波器),对应的GCN就是一个类低通滤波。空间方法的重点是邻域节点选择的问题。
可惜的是网络学习的是节点信息的特征,而没有图结构特征;结构特征作为了信息传递和聚合的工具,即上下文学习。
graph pooling
graph coarsening
其实是下采样过程,对节点进行聚类然后选取那些clusters作为新的节点(super node)。

node selection
首先学习一种对节点重要性的度量方法,然后根据这种度量选择一些重要的节点。