有监督学习和无监督学习
(一)什么是机器学习?
概念:
从广义上来说,机器学习是一种能够赋予机器学习的能力以此让它完成直接编程无法完成的功能的方法。但从实践的意义上来说, 机器学习是一种通过利用数据,训练出模型,然后使用模型预测的一种方法。
机器学习的应用范围:
机器学习与模式识别、统计学习、数据挖掘、计算机视觉、语音识别、自然语言处理等领域有着非常深的联系。
- 模式识别 = 机器学习
两者的主要差别在于前者是从工业界发展起来的概念,后者则主要源自计算机学科。它们中的活动能够被视为同一个领域的两个方面。 - 数据挖掘 = 机器学习 + 数据库
数据挖掘是一种思考方式,告诉我们应该尝试从数据中挖掘出知识,但不是每一个数据都能挖掘出金子的。一个系统绝对不会由于上了一个数据挖掘模块就变得无所不能。大部分数据挖掘中的算法是机器学习的算法在数据库中的优化。 - 统计学习近似等于机器学习
统计学习是个与机器学习高度重叠的学科,由于机器学习中的大多数方法来自统计学,甚至能够觉得,统计学的发展促进机器学习的发展。 - 计算机视觉 = 图像处理 + 机器学习
图像处理技术用于将图像处理为适合进入机器学习模型中的输入,机器学习则负责 从图像中识别出相关的模式。计算机视觉相关的应用非常的多,比如百度识图、手写字符识别、车牌识别等等应用。 - 语音识别 = 语音处理 + 机器学习
语音识别就是音频处理技术与机器学习的结合。语音识别技术一般不会单独使用,通常会结合自然语言处理的相关技术,有关的应用有苹果的语音助手siri等。 - 自然语言处理 = 文本处理 + 机器学习
自然语言处理技术主要是让机器理解人类的语言的一门领域。
通俗来讲,机器学习就是:
三个基本的要素,任务T、经验E和性能P。机器学习=通过经验E的改进后,机器在任务T上的性能p所度量的性能有所改进=T–>(从E中学习)–>P(提高)
(二)有监督学习
概念:
通过已有的训练样本去训练得到一个最优模型,再利用这个模型将所有的输入映射为相应的输出,对输出进行简单的判断从而实现预测和分类的目的,也就具有了对未知数据进行预测和分类的能力。简单来说,就像有标准答案的练习题,然后再去考试,相比没有答案的练习题然后去考试准确率更高。监督学习中的数据中是提前做好了分类信息的, 它的训练样本中是同时包含有特征和标签信息的,因此根据这些来得到相应的输出。
有监督算法常见的有:线性回归算法、BP神经网络算法、决策树、支持向量机、KNN等。
数学说明:
监督学习从训练数据集合中训练模型,再对测试据进行预测,训练数据由输入和输出对组成,通常表示为:T = { ( x 1 , y 1 ) , ( x 2 , y 2 ) , ⋯ , ( x i , y i ) } T=\left \{ \left ( x_{1},y_{1} \right ),\left ( x_{2},y_{2} \right ) ,\cdots ,\left ( x_{i},y_{i} \right )\right \}T={(x1,y1),(x2,y2),⋯,(xi,yi)}
测试数据也由相应的输入输出对组成。
有监督学习中,比较典型的问题可以分为:输入变量与输出变量均为连续的变量的预测问题称为回归问题(Regression),输出变量为有限个离散变量的预测问题称为分类问题(Classfication),输入变量与输出变量均为变量序列的预测问题称为标注问题。
应用:
垃圾邮件分类等已知结果的分类问题。
(三)无监督学习
概念:
训练样本的标记信息未知, 目标是通过对无标记训练样本的学习来揭示数据的内在性质及规律,为进一步的数据分析提供基础,此类学习任务中研究最多、应用最广的是"聚类" (clustering),聚类目的在于把相似的东西聚在一起,主要通过计算样本间和群体间距离得到。深度学习和PCA都属于无监督学习的范畴。
无监督算法常见的有:密度估计(densityestimation)、异常检测(anomaly detection)、层次聚类、EM算法、K-Means算法(K均值算法)、DBSCAN算法 等。
应用:
比较典型的是一些聚合新闻网站(比如说百度新闻、新浪新闻等),利用爬虫爬取新闻后对新闻进行分类的问题,将同样内容或者关键字的新闻聚集在一起。所有有关这个关键字的新闻都会出现,它们被作为一个集合,在这里我们称它为聚合(Clustering)问题。
(四)二者的区别
-
有 vs. 无训练样本: 有监督学习方法必须要有训练集与测试样本。在训练集中找规律,而对测试样本使用这种规律。而无监督学习没有训练集,只有一组数据,在该组数据集内寻找规律。
-
分类同时定性 vs. 先聚类后定性:有监督学习的方法就是识别事物,识别的结果表现在给待识别数据加上了标签。因此训练样本集必须由带标签的样本组成。而无监督学习方法只有要分析的数据集的本身,预先没有什么标签。如果发现数据集呈现某种聚集性,则可按自然的聚集性分类,但不予以某种预先分类标签对上号为目的。
-
有 vs. 无 规律性: 无监督学习方法在寻找数据集中的规律性,这种规律性并不一定要达到划分数据集的目的,也就是说不一定要“分类”。这一点是比有监督学习方法的用途要广。譬如分析一堆数据的主分量(PCA),或分析数据集有什么特点都可以归于无监督学习方法的范畴。
-
分类 vs.聚类:有监督的核心是分类,无监督的核心是聚类(将数据集合分成由类似的对象组成的多个类)。有监督的工作是选择分类器和确定权值,无监督的工作是密度估计(寻找描述数据统计值),也就是无监督算法只要知道如何计算相似度就可以开始工作了。
-
同维vs.降维:有监督的输入如果是n维,特征即被认定为n维,也即y = f ( x i ) y=f(x_{i})y=f(xi)或p ( y ∣ x i ) , i = n p(y|x_{i}), i =np(y∣xi),i=n,通常不具有降维的能力。而无监督经常要参与深度学习,做特征提取,或者采用层聚类或者项聚类,以减少数据特征的维度,使i < n i
-
. 不透明 vs.可解释性: 有监督学习只是告诉你如何去分类,但不会告诉你为什么这样去分类,因此具有不透明性和不可解释性。而无监督学习是根据数据集来聚类分析,再分出类别,因此具有可解释性和透明性,会告诉你如何去分类的,根据什么情况或者什么关键点来分类。
-
DataVisor无监督独有的扩展性: 根据原有的数据把分类特征已经定好,若增加一组数据,变成了n+1维。那么,如果这是一个非常强的特征,足以将原来的分类或者聚类打散,一切可能需要从头再来,尤其是有监督学习,权重值几乎会全部改变。而DataVisor开发的无监督算法,具有极强的扩展性,无论多加的这一维数据的权重有多高,都不影响原来的结果输出,原来的成果仍然可以保留,只需要对多增加的这一维数据做一次处理即可。
(五)如何在两者中选择合适的方法
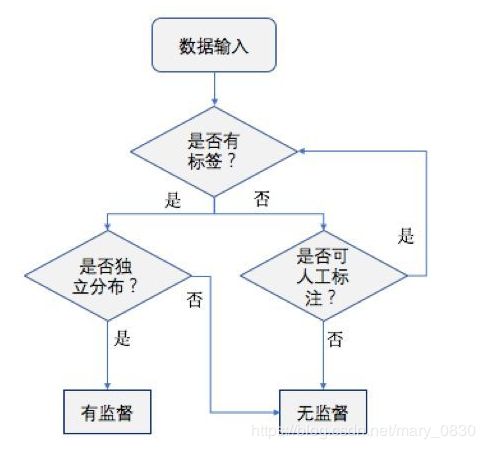
根据上面的图也可以进行分类:
简单的方法就是从定义入手,有训练样本则考虑采用有监督学习方法;无训练样本,则一定不能用有监督学习方法。但是,现实问题中,即使没有训练样本,我们也能够凭借自己的双眼,从待分类的数据中,人工标注一些样本, 并把它们作为训练样本,这样的话,可以把条件改善,用监督学习方法来做。
关于这部分的内容可以观看b站上的链接:
https://www.bilibili.com/video/av9912938/?p=4