pandas解决数据缺失、重复的方法与实践

1. 数据缺失
常见的数据缺失是指一条数据记录中,某个数据项没有值,延申到实际应用中,还有一种时间序列的缺失,例如按整点采集数据,缺少某一时刻的数据(缺少一整行数据)。
解决方法,如果不删除数据,一般进行插值处理,常见的补0,或者某个经验值,更科学的方法是线性插值,或者更复杂的算法。
1.1. 时间序列补充
例如,给定某个时间序列(逐时),中间缺少3点数据,插值补充,并扩充数据到间隔半个小时。
代码 1.
import pandas as pd
key = ['getTime','temp','text','humidity']
data = [['2023-04-30T00:00',7,'晴',57],
['2023-04-30T01:00',6,'晴',58],
['2023-04-30T02:00',6,'阴',55],
['2023-04-30T04:00',4,'晴',50]]
df = pd.DataFrame(data,columns=key)
df.index = df['getTime'].astype('datetime64')
补充时间序列,同时对数值列进行线性插值。
代码 2.
df1 = df.resample('30min').interpolate(method='linear')
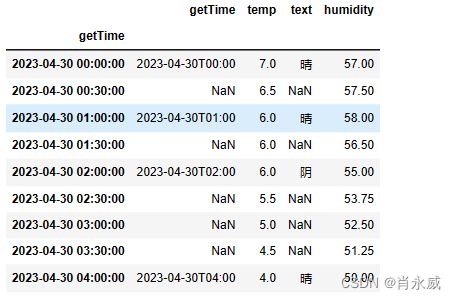
注意:补充时间序列,需要DataFrame中的index是时间序列。
或者,新建时间序列表,再通过pd.merge关联补足缺失时序。
代码 3.
times = pd.date_range('2023-04-30 00:00', '2023-04-30 04:59', freq='1h') # 与上文采用标准国际时间 UTC
# times = pd.date_range('2023-04-30 00:00', '2023-04-30 04:59', freq='1h', tz='Asia/Shanghai')
df0 = pd.DataFrame(index=times)
df0 = pd.merge(left=df0,right=df,left_index=True,right_index=True,how='left')

1.2. 数据项缺失
1.2.1. 线性插值
代码 4.
df0[['temp','humidity']] = df0[['temp','humidity']].interpolate(method='linear')

或者,直接在时间序列补充时,线性插值,详见代码 2。
1.2.2. 复制上一条数据
如果是非数值型数据,可以采用复制上一条数据内容,同理,数值型也满足。
代码 5.
df0[['text','getTime']] = df0[['text','getTime']].fillna(method='ffill')

1.2.3. 空值填充
例如,针对代码 3的结果进行填充空值“6”。
代码 6.
df0.fillna(6, inplace=True)

2. 删除重复数据行
首先,构建重复数据,合并同一张表。
代码 7.
# 合并同表前两条记录
df2 = pd.concat([df,df.head(2)])
其中,head(2)是取表中前两条记录。

2.1. 删除完全重复的行
删除重复记录。
代码 8.
df2 = df2.drop_duplicates()
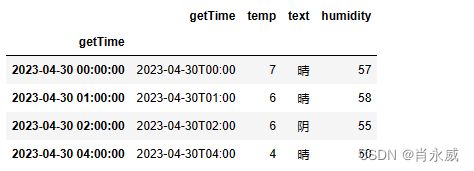
注意:这个是删除完全相同的数据。
2.2. 删除重复数据项
按某列(可以多个)进行去重,对于重复项,保留第一次出现的值。
代码 9.
df2 = df2.drop_duplicates('text',keep='first')
df.drop_duplicates(subset=[‘A’,‘B’,‘C’],keep=‘first’,inplace=True)
参数说明如下:
- subset:表示要进去重的列名,默认为 None。
- keep:有三个可选参数,分别是 first、last、False,默认为 first,表示只保留第一次出现的重复项,删除其余重复项,last 表示只保留最后一次出现的重复项,False 则表示删除所有重复项。
- inplace:布尔值参数,默认为 False 表示删除重复项后返回一个副本,若为 Ture 则表示直接在原数据上删除重复项。
3. 按条件修改数据
按条件修改部分数据值,常用方法是apply()调用函数处理,也可以直接使用loc定位索引进行修改数据,引用代码 1产生的结果。
本文采用loc方式,按条件修改数据。
代码 10.
df.loc[df.loc[(df.index>=pd.to_datetime('2023-04-30 01:00')) ].index,
['temp','humidity']] = df[['temp','humidity']].loc[(df.index>=pd.to_datetime('2023-04-30 01:00')) ]+10
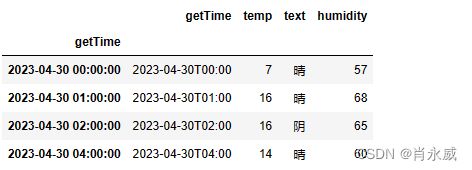
按索引,具体列为查询条件都可以。
4. 发现空值及处理
4.1. 空值查询
查询出空值,并替换同行数据中的另一项数据,例如:查询代码 2的结果集,查询“text”为空时的“temp”值,由“humidity”的值替换。
代码 11.
df1.loc[df1[df1['text'].isnull()].index,'temp'] = df1['humidity'].loc[df1['text'].isnull()]
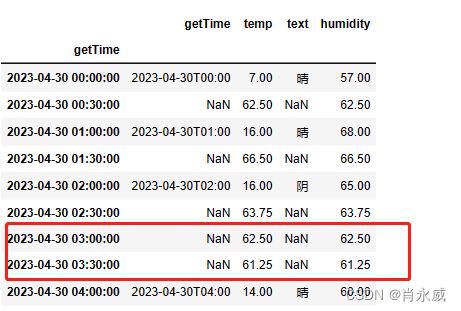
依据查询代码 2的结果集,查询非空数据。
代码 12.
df1 = df1.loc[~df1['text'].isnull()]

其中,~ 表示取反符号,.isnull() 方法用于判断是否为空。
4.2. 删除空值
依据查询代码 2的结果集,删除空值的数据行。
代码 13.
df1 = df1.dropna()
