SQL中常用的窗口函数(排序函数)-row_number/rank/dense_rank/ntile
总结四个函数的特点:
row_number():连续不重复;1234567
rank() :重复不连续;1222567
dense_rank():重复且连续;1222345
ntile():平均分组;1122334
一、函数介绍
SQL Server中的排序函数有四个:row_number(),rank(),dense_rank()及ntile()函数;
1.row_number()函数
特点: row_number()函数可以为每条记录添加递增的顺序数值序号,即使值完全相同也依次递增序号,不会重复。
语法:
ROW_NUMBER() OVER (
[PARTITION BY partition_expression, ... ]
ORDER BY sort_expression [ASC | DESC], ...
)
PARTITION BY子句将结果集划分为分区。 ROW_NUMBER()函数分别应用于每个分区,并重新初始化每个分区的行号。PARTITION BY子句是可选的。如果未指定,ROW_NUMBER()函数会将整个结果集视为单个分区。
ORDER BY子句定义结果集的每个分区中的行的逻辑顺序。 ORDER BY子句是必需的,因为ROW_NUMBER()函数对顺序敏感。
2.rank()函数
特点: rank()函数也是返回每条记录的排名序号,但当值相同时,序号也将相同,同时跳跃排序(比如两个第一名后面是第三名)。
语法:
RANK() OVER (
[PARTITION BY partition_expression, ... ]
ORDER BY sort_expression [ASC | DESC], ...
)
PARTITION BY子句划分应用该函数的结果集分区的行。
ORDER BY子句指定应用该函数每个分区中行的逻辑排序顺序。
3.dense_rank()函数
特点: dense_rank()函数进行排序时,也会将值相同的数据赋予同一个序号,但与rank()函数不同的是,dense_rank()函数为连续排序(比如两个第一名后面是第二名)。
语法:
DENSE_RANK() OVER (
[PARTITION BY partition_expression, ... ]
ORDER BY sort_expression [ASC | DESC], ...
)
dense_rank()函数以ORDER BY子句定义的指定顺序应用于PARTITION BY子句定义的每个分区的行。它会在划分分区边界时重置等级。
PARITION BY子句是可选的。如果省略它,该函数会将整个结果集视为单个分区。
4.ntile(n)函数
特点: ntile(n)函数会将数据分为n组,自动进行分组 (每组数量大致相等,若无法均分为n组,则每组的记录数不能大于它上一组的记录数),每组将会分配同一个序号(组号为1-n)。
语法:
NTILE(integer_expression) OVER (
[PARTITION BY partition_expression, ... ]
ORDER BY sort_expression [ASC | DESC], ...
)
integer_expression 为数据行划分的组数。
PARTITION BY子句将结果集的行分配到应用了NTILE()函数的分区中。
ORDER BY子句指定应用NTILE()的每个分区中行的逻辑顺序。
二、 应用实例
- row_number()函数
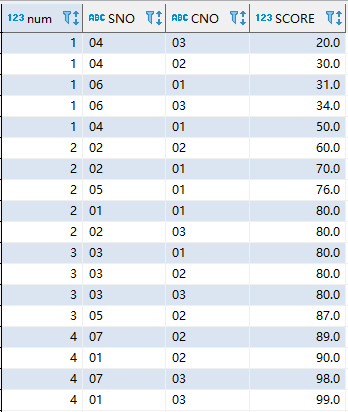
将所有数据按照score排名
select row_number()over(order by SCORE) as num,sc.* from sc
结果:
可以看到,score相同的数据行,排序依旧递增。
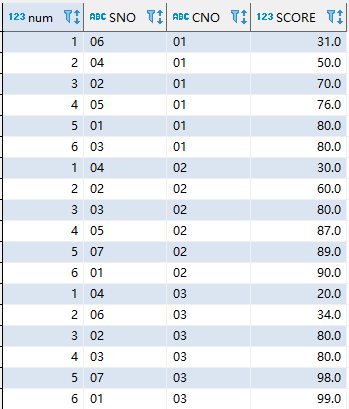
另外,可以使用partition by为数据进行分组排序
例如,按照CNO分组,将score排序
select row_number()over(partition by CNO order by SCORE) as num,sc.* from sc
- rank()函数
将所有数据按照score排名
select rank()over(order by SCORE) as num,sc.* from sc
结果
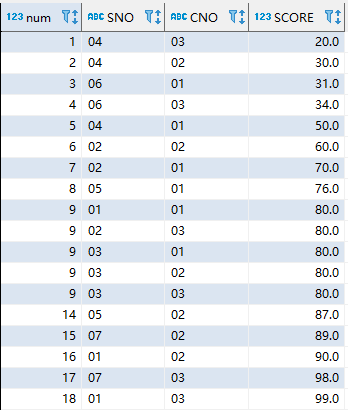
可以看到,score相同的数据行,排序相同。并且为跳跃排序(五个9后面是14)。
partition by使用方法相同,不再模拟。
- dense_rank()函数
将所有数据按照score排名
select dense_rank()over(order by SCORE) as num,sc.* from sc
结果
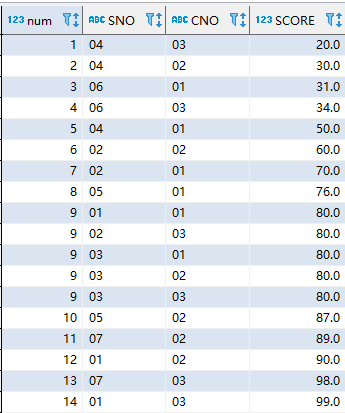
可以看到,score相同的数据行,排序相同。但为顺序排序(五个9后面仍是10)。
PS:
dense_rank()函数还有个用处,就是将一组内的数据分为同一个序号,并按组递增排序。这样可以获得groupby的num值,对于只有值,没有ID的数据,比较有用。
例如:按照CNO分组排序
select dense_rank()over(order by CNO ) as num,sc.* from sc
结果:

- ntile()函数
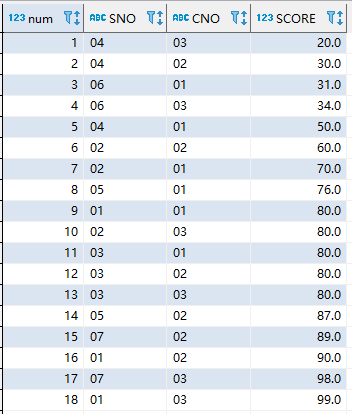
将所有数据按照score排序,并分为4组
select ntile(4)over(order by SCORE ) as num,sc.* from sc
结果