MySQL数据库优化————COUNT优化
直接进入主题
索引对count语句的影响
在我们对departments表进行count查询时,使用了以下语句
select count(*) from employees;
当前employees表索引情况如图
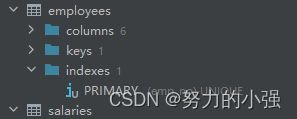
只有一个主键索引
执行
explain
select count(*) from employees;
![]()
从结果中可以看到,这时候用的是主键索引。
让我们修改一下employees表的索引
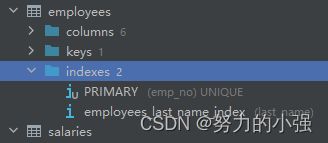
在last_name上创建了索引,我们再次执行explain得到结果
![]()
我们再一次修改employees表的索引
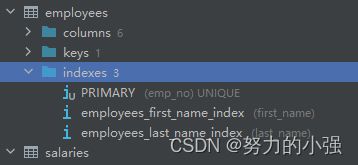
我们又在first_name上创建了索引,再一次执行explain语句
![]()
这一次我们用到了first_name上的索引,并且索引长度first_name上的要小于last_name上的。
得到结论:
- 当没有非主键索引时,count查询会使用主键索引
- 如果存在非主键索引时,count查询会使用非主键索引
- 如果存在多个非主键索引时,count查询会使用索引长度最小的非主键索引
原因分析
我们的表使用的InnoDB引擎,那么主键索引存储的是主键+表数据,而非主键索引存储的是索引+主键。InnoDB是以页为单位的,那么存储的一行数据越小,则存储的数据越多。主键的大小是固定的,而表数据的大小肯定比一个非主键索引大,所以非主键索引存储的数据要比主键索引存储的数据量大;同理,长度小的非主键索引存储的数据也比长度大的非主键索引存储的数据量大。
count(字段)和count(*)
当我们在执行count(字段)时
select count(last_name) from employees;
执行explain语句
explain
select count(last_name) from employees;
![]()
得到结论,count(字段)时,只会针对该字段统计,使用这个字段上面的索引(如果有的话)。
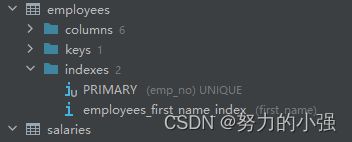
如果我们将last_name上的索引删除,再次执行explain语句
![]()
得到结论,count(字段)时,如果该字段上没有索引,则进行的时全表扫描。
我们分别执行以下语句
select count(*) from employees;
select count(last_name) from employees;
分别得到结果


为什么会不一样呢,因为我将其中的四条数据的last_name置为了null;
结论,count(字段)会排除掉该字段值为null的数据,而count(*)不会排除,所以要根据业务需求的需要进行选择,不能无脑的任意选择一种。
count(*)和count(1)
我们来执行一下count(1)的explai语句,得到结果
![]()
发现该语句同样使用的是表的最小长度的非主键索引。同时查阅官方文档,有这样一段话
![]()
所以,count(*)和count(1)是一样的,没有性能差异。
基于存储引擎
在官方文档中还提到了
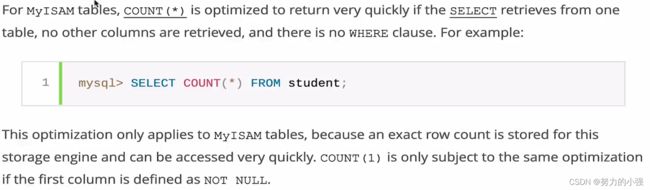
如果是用的MyISAM引擎,并且使用的是示例中的语句,查询速度会非常的快,因为该引擎将行数存储到了引擎。该功能是有限制的,必须是没有where条件语句的。
同时,还有这样一段话
![]()
从MySQL8.0.13,InnoDB引擎如果没有where条件,查询也会被优化,性能有所提升。该功能有条件的朋友可以在低版本的MySQL和8.0.13版本上的进行一下验证,这里不做演示。
汇总表
当count查询耗时过长,我们可以创建一张汇总表,统计各个表的行数。当数据发生变化时去修改对应表的行数,可以通过使用触发器自动维护实现。
这种方法的好处就是结果准确,但是需要额外的维护成本。
sql_calc_found_rows
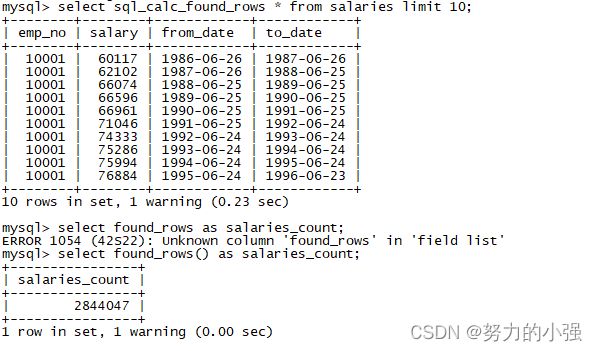
cpunt查询往往伴随着分页查询,在进行分页查询时我们可以使用以下语句
select sql_calc_found_rows * from table limit offset,size;
然后紧接着执行
select found_rows() as 别名;
这样就能很快的返回我们想要的数据了,因为第一条语句在执行完分页查询后,会自动执行count查询。在项目中我们可以这样运用
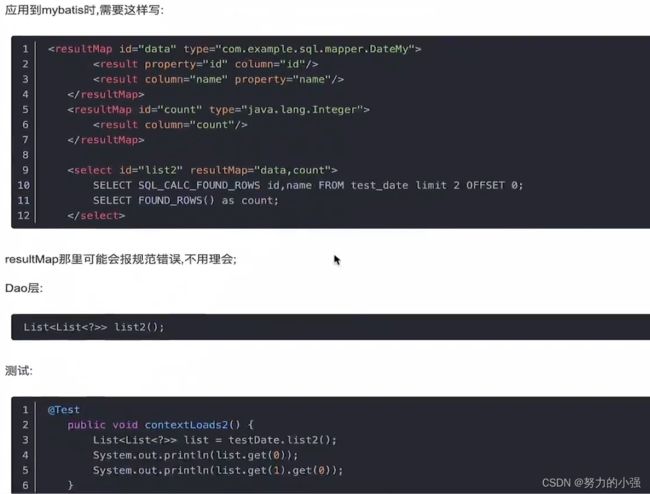
这种方式,从8.0.17已经被废弃了,在以后的版本会被删除。
使用额外的中间件解决
将count的结果定时存入缓存中,这种方式性能比较高,结果比较准确,有误差,但是可以接受,除非在缓存更新阶段有大量的新增和删除。但是缺点就是要引入额外的组件,增加了架构的复杂度及维护成本。