深度学习实战项目(二)-基于yolov5和svm的摔倒检测系统设计
深度学习实战项目(二)-基于yolov5和svm的摔倒检测系统设计
基于yolov5深度学习方法的摔倒检测
基于yolov5的算法设计网上有很多,yolov5是一个成熟的好框架,只要有数据集,就可以进行训练,训练步骤跟我之前发的博客类似:
工业缺陷检测项目实战(二)——基于深度学习框架yolov5的钢铁表面缺陷检测
所使用的数据集包含了图片和对应的摔倒人物的位置标签。

该数据集的配置来自coco128.yaml。
基于SVM等机器学习方法的摔倒检测
机器学习进行分类需要收集分类数据,一般是从csv里面提取数据,那么,这里借助Mediapipe进行人体特征点的提取,如下图:
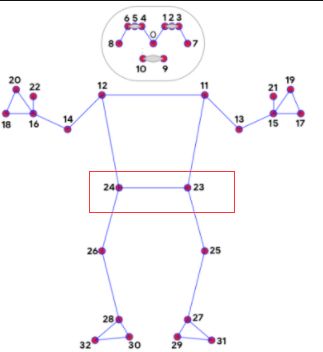
很明显,站立和摔倒时,这几十个特征点数据是不一样的,通过代码把这些数据记录下来,保存为csv,


分为两个类,0代表摔倒的数据,1代表站立和还没真正摔倒的数据。
使用SVM读取数据并分类的代码:
import joblib
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.svm import SVC
from sklearn.metrics import roc_auc_score,accuracy_score,precision_score,recall_score,f1_score
from sklearn.metrics import confusion_matrix, roc_curve, auc
import matplotlib.pyplot as plt
import seaborn as sns
train_x = []
normal = pd.read_csv("csv_data/normal_point.csv")
fall = pd.read_csv("csv_data/fall_point.csv")
print(normal.values.shape)
print(fall.values.shape)
res = pd.concat([normal, fall])
print(res)
data = res.iloc[:, 1:]
target = res.iloc[:, 0]
print(data.values)
print(target.values)
X_train, X_test, y_train, y_test = train_test_split(data.values, target.values, test_size=0.3, random_state=0)
print(X_train.shape)
print(y_train.shape)
model = SVC(kernel='rbf')#调参
model.fit(X_train, y_train)
joblib.dump(model, "Model/SVMPoseKeypoint.joblib")
pred = model.predict(X_test)
# Model accuracy
acc = accuracy_score(y_test, pred) * 100
print('test accuracy', acc)
print('precision_score', precision_score(y_test, pred) * 100)
print('recall_score', recall_score(y_test, pred) * 100)
print('f1_score', f1_score(y_test, pred) * 100)
cm_svm = confusion_matrix(y_test, pred)
plt.figure(figsize=(17, 17))
plt.title("Confusion Matrixes", fontsize=48)
plt.title("SVM Confusion Matrix")
sns.heatmap(cm_svm, annot=True, cmap="YlOrBr", fmt="d", cbar=False, annot_kws={"size": 48})
plt.show()
就可以出结果了,说实话,测试集分类准确率百分之百,是有点不严谨,可以多采集写数据,或者删除一些特征点的数据,使得系统更具鲁棒性。
界面设计
先看看界面效果:


这里的设计涉及到了如何在pyqt界面调用yolov5进行视频显示检测,这里我的方案是,先将视频的图片保存到图片,然后Yolov5读取保存的图片进行检测,最后返回检测完图片的变量进行显示,关键代码如下:
# 显示视频图像
def show_pic(self):
ret, img = self.cap.read()
if ret:
# svm检测
if self.mode == 0:
image, self.res = self.detect_svm.Defect_svm(img)
if self.res == "0":
self.pushButton_3.setStyleSheet('''QPushButton{background:#22DD48;border-radius:5px;}''')
self.pushButton_3.setText("正常")
elif self.res == "1":
self.pushButton_3.setStyleSheet('''QPushButton{background:#F70909;border-radius:5px;}''')
self.pushButton_3.setText("摔倒")
height, width = image.shape[:2]
pixmap1 = QImage(image, width, height, QImage.Format_BGR888)
pixmap1 = QPixmap.fromImage(pixmap1)
# 获取是视频流和label窗口的长宽比值的最大值,适应label窗口播放,不然显示不全
ratio1 = max(width / self.label_2.width(), height / self.label_2.height())
pixmap1.setDevicePixelRatio(ratio1)
# 视频流置于label中间部分播放
self.label_2.setAlignment(Qt.AlignCenter)
self.label_2.setPixmap(pixmap1)
# yolov5检测
elif self.mode == 1:
cv2.imwrite("res_image/res.jpg", img)
image, self.res = self.detect_yolov5.detect("res_image/res.jpg")
if self.res == "0":
self.pushButton_3.setStyleSheet('''QPushButton{background:#22DD48;border-radius:5px;}''')
self.pushButton_3.setText("正常")
elif self.res == "1":
self.pushButton_3.setStyleSheet('''QPushButton{background:#F70909;border-radius:5px;}''')
self.pushButton_3.setText("摔倒")
height, width = image.shape[:2]
pixmap1 = QImage(image, width, height, QImage.Format_BGR888)
pixmap1 = QPixmap.fromImage(pixmap1)
# 获取是视频流和label窗口的长宽比值的最大值,适应label窗口播放,不然显示不全
ratio1 = max(width / self.label_2.width(), height / self.label_2.height())
pixmap1.setDevicePixelRatio(ratio1)
# 视频流置于label中间部分播放
self.label_2.setAlignment(Qt.AlignCenter)
self.label_2.setPixmap(pixmap1)
需要源码可以私信我,需要定制界面或者其他功能也可以私信。