2023/6/18周报
目录
摘要
论文阅读
1、题目和现有问题
2、工作流程
3、图神经网络模块
4、注意力网络
5、实验结果和分析
深度学习
1、GNN和GRU的融合
2、相关公式推导
总结
摘要
本周在论文阅读上,对基于图神经网络和改进自注意网络的会话推荐的论文进行了学习,文章提出的新模型,通过 GNN与注意力机制来提取当前会话节点的局部偏好,通过改进自注意网络来捕获会话节点的全局偏好;同时在会话节点中加入可学习的位置嵌入,来更好地把握用户兴趣变化的过程。在深度学习上,学习了GNN和GRU的相关融合知识。
This week,in terms of thesis reading,studying the paper of conversation recommendation based on graph neural network and improved self-attention network.The new model proposed in this paper extracts the local preferences of the current session node through GNN and attention mechanism.Capturing the global preferences of session nodes by improving the self-attention network.At the same time, learnable location embedding is added in the session node to better grasp the process of user interest change.In deep learning, studying the relevant fusion knowledge of GNN and GRU.
论文阅读
1、题目和现有问题
题目:基于图神经网络和改进自注意网络的会话推荐
现有问题:现有的会话推荐系统大多数基于当前会话建立局部偏好来预测用户行为,而低估了会话全局序列蕴含的信息。 同时多数推荐系统忽略了会话交互序列的相对位置关系。
文章所提出的解决办法:通过GNN和传统注意力网络捕获当前会话S中交互历史中的局部信息,再结合全局偏好学习模块捕获的会话全局信息,来预测用户当前会话下一次点击的项目 V(n+1) , 最终对于会话 S,GNN-SAP模型会输出所有可能访问候选项目的概率y, 其中向量y的元素值是相应项的推荐分数,由于推荐者通常会为用户提出多个建议,因此一般将从y^中选择前K个项目作为推荐。
2、工作流程
(1)、用户每次点击序列会构成一次会话,将会话构建成会话图,随后通过图神经网络(GNN)来提取会话图中当前会话节点所蕴含的丰富的信息。
(2)、将GNN提取后的会话节点加入可学习位置信息,来保存其原有位置信息,并通过注意力网络来提取用户短期动态偏好。
(3)、对于会话全局偏好学习,将会话序列通过位置嵌入模块加入位置信息,并送入基于改进的自注意力网络来提取会话的全局静态偏好,并且通过前馈神经网络(FNN)和残差网络来提取其非线性特征。
(4)、最终将局部偏好与全局偏好非线性特征经过线性融合,再送入预测层,得到项目集合V中每个项目的得分,得分越高表示被用户点击的可能性越大。
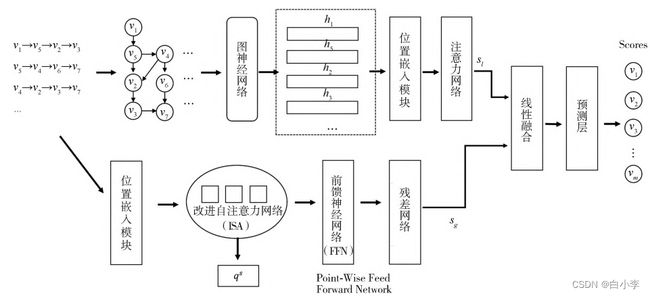
3、图神经网络模块
首先将每个会话构建成一个会话图。 给定会话S = {V1 ,V2 ,…,Vn }, 将每个项目vi视为一个节点,将 (Vi-1,Vi) 视为一条边,表示用户在会话S中的Vi-1之后点击项目Vi, 因此,每个用户会话序列都可以建模为一个有向图 Gs= (γs,εs)。 对于会话图中的节点 Vt, 不同节点之间的信息传播可以形式化为:

然后将它们和之前的状态Vt-1一起输入到图神经网络中。 因此,GNN层最终输出ht计算如下:

用户会话交互序列的位置信息同样重要,会话历史交互顺序表明了用户兴趣随着时间的变化过程。 为了保存会话交互位置信息,在GNN捕获的节点和会话全局序列之后加入可学习的位置嵌入模块, 不仅能更好保存会话序列中的信息,而且还能过滤会话中的噪声。
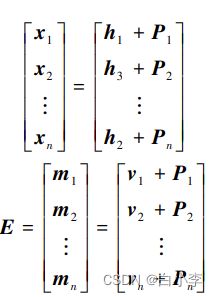
4、注意力网络
为了使推荐系统更专注于找到会话序列中与用户偏好相关的信息,本文采用软注意机制来更好捕获会话的局部偏好。

Transformer在NLP领域中首次提出了自注意力机制,将嵌入层的输入通过线性投影分别转换为Query、Key 和Value三个不同矩阵,并将它们输入到使用放缩点积的注意力层中。 由于序列化所隐含的顺序性,在预测 (t+1)项时应该只考虑前 t项,而自注意力层的输出包含后续所有项目的嵌入,为了不依赖t时刻之后的输出,自注意力机制通过禁止Qi和Kj(j > i) 之间的点积来进行因果约束。 自注意力机制的表示如下

尽管通过GNN和注意力机制可以很好地提取会话的局部动态偏好,但局部表示仍然忽略来自其他会话的有用的项目信息和会话的长期静态偏好。本文从会话的全局序列上考虑,不再对用户行为序列进行因果约束,使未来的更多可用信息可用于对训练期间序列的预测,以便更好地提取会话的全局偏好,下图展示了自注意力机制与改进自注意力机制的流程对比。

5、实验结果和分析
数据集来源:Diginetica、Tmall、Nowplaying。
过滤掉数据集中长度为1的会话和出现次数少于5次的项目。 将最新数据设置为测试数据,剩余的历史数据用于训练。处理后的数据:

本文使用P@K和MRR@K评估指标来评估推荐模型的性能。
对比算法:POP、Item-KNN、FPMC、GRU4Rec、NARM、STAMP、CSRM、FGNN、SR-GNN。
GNN-SAP和9个基线模型在3个真实数据集上的实验结果如下表所示。 其中每一列的最佳结果以粗体突出显示, 与基线模型相比GNN-SAP在Diginetica上的表现比SR-GNN 平均高出 3.6%,在Tmall上平均高出8.7%,在 Nowplaying上平均高出5.6%。 可以观察到,GNN-SAP在所有3个数据集上以两个指标(K=10和K=20一致地实现了最佳性能,从而验证了本文提出的方法的有效性。

进行消融研究,比较仅采用局部偏好学习模块(GNN-Local)、全局偏好学习模块(GNN⁃Global)和两者相结合(GNN-SAP) 的效果,如下表所示。

在3个数据集上,对于基于GNN的短期偏好学习比基于自注意力的长期偏好学习取得了更好的预测效果。 这证明了图神经网络比注意力机制更适合用来提取当前会话节点的局部的复杂信息和动态偏好,同时全局偏好学习模块在捕获静态偏好上也具有一定的有效性。
通过消融研究来分析它们产生的不同影响,下表显示了默认方法及其变体在3个数据集上取得的效果。

从GNN-SAP中移除可学习的位置嵌入模块,可以看出GNN-SAP在3个数据集上相比移除位置嵌入模块的方法取得了更好的效果。 这表明在当前会话节点和全局会话序列中加入位置信息,可以更好地保存会话中原有访问顺序,以便更好捕获会话序列中的复杂信息,来进行更为准确的推荐。
从GNN-SAP中移除FFN和残差网络。可以看出GNN-SAP在3个数据集上均表现比较好。 这表明了通过加入FFN和残差网络来提取用户非线性特征和底层用户信息的有效性,能更好地提取用户会话的全局偏好信息。
深度学习
1、GNN和GRU的融合
GNN和GRU是两种常见的神经网络模型,用于处理不同类型的数据。GNN主要用于处理图结构数据,而GRU则用于处理序列数据。将它们融合起来可以在一些场景下提供更好的建模能力。
融合GNN和GRU的可能方法
-
数据预处理:首先,将图结构数据转换为序列数据。这可以通过选择适当的遍历策略或图结构的表示方式来实现。一种常见的方法是使用图遍历算法(如广度优先搜索或深度优先搜索)来获取节点的顺序序列。
-
序列表示学习:使用GRU模型对序列数据进行建模。GRU是一种递归神经网络模型,具有门控机制,可以有效地捕捉序列中的长期依赖关系。通过学习序列的表示,可以将图结构数据转换为连续向量表示。
-
图结构建模:使用GNN模型对转换后的向量表示进行图结构建模。GNN模型可以在图中传递信息并对节点进行聚合。通过将GRU的输出作为初始节点特征,并在GNN中进行多轮的信息传递和聚合,可以捕捉节点之间的复杂关系和全局图结构信息。
-
预测或分类:最后,使用融合了GNN和GRU的模型进行所需的任务,如节点分类、链接预测或图分类等。可以根据具体的应用场景和任务进行相应的调整和优化。
应用领域:
-
图节点分类:在图中对节点进行分类是一个常见的任务。通过将GRU的输出作为初始节点特征输入GNN,可以融合节点的序列信息和图结构信息,提升节点分类的准确性。
-
图链接预测:预测图中尚未存在的边或链接是图数据分析的重要任务之一。通过融合GNN和GRU,可以捕捉节点之间的序列依赖关系和图结构信息,从而提高链接预测的性能。
-
图生成模型:利用GNN和GRU的融合,可以生成具有一定拓扑结构的图数据。通过学习图的节点序列表示和图结构特征,可以生成新的图示例,具有与训练数据类似的特征。
-
图推荐系统:在图数据中进行推荐是一种有挑战性的任务。通过结合GNN和GRU,可以融合节点的序列信息和图结构信息,对用户和物品之间的关系进行建模,从而提供个性化的图推荐。
-
图语义分析:将自然语言处理(NLP)任务与图数据结合,可以进行图中节点的语义分析。通过使用GRU进行序列建模,并将其融合到GNN中,可以利用节点之间的语义信息进行更准确的图分析和理解。
2、相关公式推导
-
GRU模型推导: GRU是一种递归神经网络模型,用于处理序列数据。对于每个节点i,GRU模型的更新公式如下:
更新门(Update Gate):
![]()
重置门(Reset Gate):
![]()
候选隐藏状态(Candidate Hidden State):
![]()
当前隐藏状态(Current Hidden State):
![]()
其中,x_i是节点i的输入特征,h_i是节点i的隐藏状态,h{i-1}是节点i的前一个时间步的隐藏状态,z_i是更新门,r_i是重置门,tilde{h}i是候选隐藏状态。W_z, U_z, b_z, W_r, U_r, b_r, W_h, U_h, b_h是GRU模型的参数。
2、GNN模型推导:GNN是一种用于图数据的神经网络模型,它通过迭代信息传递和聚合来学习节点的表示。我们使用图G的邻接矩阵A表示节点之间的连接关系,节点i的邻居节点集合为N(i),节点i的初始特征表示为h_i。
GNN模型的更新公式可以表示为:
![]()
其中,l表示GNN的层数,f是信息传递和聚合函数。
3、GNN和GRU融合: 为了融合GNN和GRU模型,我们将GRU的输出作为初始节点特征输入到GNN模型中,并在GNN中进行多轮的信息传递和聚合。
具体地,我们将GRU的输出h_i作为GNN的初始特征表示:
![]()
然后,在每一轮的信息传递中,我们使用GNN的更新公式进行节点特征的更新:

总结
本周继续对图神经网络进行学习,以及在GNN和GRU的融合中进行了一定的学习,接下来将展开进一步的深入学习。