214. 最短回文串20200831
文章目录
- 题目描述
- 解法1 遍历填充字符(太慢)
-
- 代码
- 复杂度分析
- 结果
- 解法2 字符串哈希
-
- 代码
- 复杂度分析
- 结果
- 解法3 KMP字符串匹配
-
- KMP算法
-
- 代码
- 复杂度分析
- 思路
- 代码
- 复杂度分析
- 结果
题目描述
214. 最短回文串
给定一个字符串 s,你可以通过在字符串前面添加字符将其转换为回文串。找到并返回可以用这种方式转换的最短回文串。
示例 1:
输入: “aacecaaa”
输出: “aaacecaaa”
示例 2:
输入: “abcd”
输出: “dcbabcd”
解法1 遍历填充字符(太慢)
将字符串末尾的值依次添加到字符串开头,每次添加后判断是否为回文,如果是则结束,不是则继续添加。
例如:
- 输入为:’" aacecaaa \text{aacecaaa} aacecaaa“时,取倒数第一个字母a添加到开头,得到“ a \color{#FF3030}{\text{a}} a aacecaaa \text{aacecaaa} aacecaaa”,该字符串为回文,结束并返回该字符串“ a \color{#FF3030}{\text{a}} a aacecaaa \text{aacecaaa} aacecaaa"。
- 输入为 “ abcd \text{abcd} abcd”,操作依次为:
“ d \color{#FF3030}{\text{d}} d abcd \text{abcd} abcd",不是回文,继续;
“ dc \color{#FF3030}{\text{dc}} dc abcd \text{abcd} abcd",不是回文,继续;
“ dcb \color{#FF3030}{\text{dcb}} dcb abcd \text{abcd} abcd",是回文,结束。
代码
class Solution:
def shortestPalindrome(self, s: str) -> str:
if s[::-1] == s:
return s
for i in range(-2, -len(s)-1, -1):
tmp = s[-1:i:-1] + s
if tmp == tmp[::-1]:
return tmp
复杂度分析
- 时间复杂度: O ( N 2 ) O(N^2) O(N2), N N N为字符串的长度,最坏情况下需要添加 N − 1 N-1 N−1次,每次添加后判断是否为回文需要比较 O ( N ) O(N) O(N)次。
- 空间复杂度: O ( N ) O(N) O(N),存储 t m p tmp tmp 字符串。
结果
120 / 120 个通过测试用例
状态:通过
执行用时: 920 ms
内存消耗: 13.8 MB
解法2 字符串哈希
参考自力扣解答
思路
我们需要在给定的字符串 s s s 的前面添加字符串 s ′ \color{#FF3030}{s'} s′ s s s ,得到最短的回文串。这里我们用 s ′ + s s'+s s′+s表示得到的回文串。显然,这等价于找到最短的字符串 s ′ s' s′,使得 s ′ + s s'+s s′+s 是一个回文串。
由于我们一定可以将 s s s 去除第一个字符后得到的字符串反序地添加在 s s s 的前面得到一个回文串,因此一定有 ∣ s ′ ∣ < ∣ s ∣ |s'| < |s| ∣s′∣<∣s∣,其中 ∣ s ∣ |s| ∣s∣表示字符串 s s s 的长度。
例如当 s = abccda s=\text{abccda} s=abccda 时,我们可以将 bccda \text{bccda} bccda 的反序 adccb \text{adccb} adccb添加在前面得到回文串 adccbabccda \text{adccbabccda} adccbabccda。
这样一来,我们可以将 s s s 分成两部分:长度为 ∣ s ∣ − ∣ s ′ ∣ |s| - |s'| ∣s∣−∣s′∣ 的前缀 s 1 s_1 s1;长度为 ∣ s ′ ∣ |s'| ∣s′∣ 的后缀 s 2 s_2 s2 。由于 s ′ + s s'+s s′+s 是一个回文串,那么 s ′ s' s′ 的反序就必然与 s 2 s_2 s2 相同,并且 s 1 s_1 s1 本身就是一个回文串。因此,要找到最短的 s ′ s' s′,等价于找到最长的 s 1 s_1 s1。也就是说,我们需要在字符串 s s s 中找出一个最长的前缀 s 1 s_1 s1,它是一个回文串。当我们找到 s 1 s_1 s1 后,剩余的部分即为 s 2 s_2 s2,其反序即为 s ′ s' s′。
我们可以用 Rabin-Karp 字符串哈希算法来找出最长的回文串。
在该方法中,我们将字符串看成一个 b a s e base base 进制的数,它对应的十进制值就是哈希值。显然,两个字符串的哈希值相等,当且仅当这两个字符串本身相同。然而如果字符串本身很长,其对应的十进制值在大多数语言中无法使用内置的整数类型进行存储。因此,我们会将十进制值对一个大质数 m o d mod mod 进行取模。此时:如果两个字符串的哈希值在取模后不相等,那么这两个字符串本身一定不相同;如果两个字符串的哈希值在取模后相等,并不能代表这两个字符串本身一定相同。
一般来说,我们选取一个大于字符集大小(即字符串中可能出现的字符种类的数目)的质数作为 b a s e base base,再选取一个在字符串长度平方级别左右的质数作为 m o d mod mod,产生哈希碰撞的概率就会很低。
算法
一个字符串是回文串,当且仅当该字符串与它的反序相同。因此,我们仍然暴力地枚举 s 1 s_1 s1 的结束位置,并计算 s 1 s_1 s1 与 s 1 s_1 s1 反序的哈希值。如果这两个哈希值相等,说明我们找到了一个 s s s 的前缀回文串。
在枚举 s 1 s_1 s1 的结束位置时,我们可以从小到大地进行枚举,这样就可以很容易地维护 s 1 s_1 s1 与 s 1 s_1 s1 反序的哈希值:
设当前枚举到的结束位置为 i i i,对应的 s 1 s_1 s1 记为 s 1 i s_1^i s1i,其反序记为 s ^ 1 i \hat{s}_1^i s^1i。我们可以通过递推的方式,在 O ( 1 ) O(1) O(1) 的时间通过 s 1 i − 1 s_1^{i-1} s1i−1 和 s ^ 1 i − 1 \hat{s}_1^{i-1} s^1i−1 的哈希值得到 s 1 i s_1^i s1i 和 s ^ 1 i \hat{s}_1^i s^1i 的哈希值:
hash ( s 1 i ) = hash ( s 1 i − 1 ) × base + ASCII ( s [ i ] ) \text{hash}(s_1^i) = \text{hash}(s_1^{i-1}) \times \textit{base} + \text{ASCII}(s[i]) hash(s1i)=hash(s1i−1)×base+ASCII(s[i])
hash ( s ^ 1 i ) = hash ( s ^ 1 i − 1 ) + ASCII ( s [ i ] ) × base i \text{hash}(\hat{s}_1^i) = \text{hash}(\hat{s}_1^{i-1}) + \text{ASCII}(s[i]) \times \text{base}^i hash(s^1i)=hash(s^1i−1)+ASCII(s[i])×basei
其中 ASCII ( x ) \text{ASCII}(x) ASCII(x) 表示字符 x x x 的 ASCII \text{ASCII} ASCII 码。注意需要将结果对 mod \textit{mod} mod 取模。
如果 hash ( s 1 i ) = hash ( s ^ 1 i ) \text{hash}(s_1^i) = \text{hash}(\hat{s}_1^i) hash(s1i)=hash(s^1i),那么 s 1 i s_1^i s1i 就是一个回文串。我们将最长的回文串作为最终的 s 1 s_1 s1。
作者:LeetCode-Solution
链接:https://leetcode-cn.com/problems/shortest-palindrome/solution/zui-duan-hui-wen-chuan-by-leetcode-solution/
来源:力扣(LeetCode)
代码
class Solution:
def shortestPalindrome(self, s: str) -> str:
if s == s[::-1]:
return s
left = ord(s[0])
right = left
best = 0
BASE = 131
MOD = 10**9 + 7
MUL = BASE
for i in range(1, len(s)):
left = (left * BASE % MOD + ord(s[i])) % MOD
right = (right + ord(s[i]) * MUL % MOD) % MOD
if left == right:
best = i
MUL = MUL * BASE % MOD
inv_prefix = '' if best == len(s)-1 else s[best+1:]
return inv_prefix[::-1] + s
复杂度分析
-
时间复杂度: O ( ∣ s ∣ ) O(|s|) O(∣s∣)。
-
空间复杂度: O ( 1 ) O(1) O(1)。
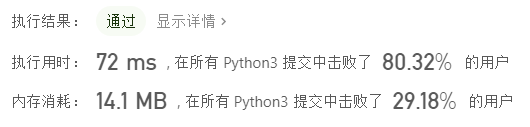
结果
120 / 120 个通过测试用例
状态:通过
执行用时: 68 ms
内存消耗: 13.8 MB
解法3 KMP字符串匹配
KMP算法
KMP算法用于从给定字符串 s s s 中查找指定的字符串 p a t t e r n pattern pattern,如果存在返回 p a t t e r n pattern pattern 在 s s s 中的第一个起始位置,否则返回 -1。
可以简单的理解为, f a i l fail fail 或 n e x t next next 数组中存储的是 p a t t e r n pattern pattern 中当前考虑的字符前面的某个字符的下标,该字符为 如果 p a t t e r n pattern pattern 中当前考虑的字符与 s s s 中当前考虑的字符 不相同时, p a t t e r e n patteren patteren 中当前考虑的字符要变为的那个字符。
详细的关于KMP算法的介绍可以参看这两篇文章:
从头到尾彻底理解KMP
如何更好地理解和掌握 KMP 算法?
代码
def kmp(s, pattern):
n, m = len(s), len(pattern)
fail = [0] * len(pattern)
fail[0] = -1
# get fail
k = -1
j = 1
while j < m - 1:
if k == -1 or pattern[k] == pattern[j]:
k += 1
j += 1
if pattern[k] == pattern[j]:
fail[j] = fail[k]
else:
fail[j] = k
else:
k = fail[k]
# for j in range(1, m-1):
# while k != -1 and pattern[k] != pattern[j]:
# k = fail[k]
#
# k += 1
# fail[j+1] = k
# search
j = 0 # 模式串的位置
for i in range(n):
while j != -1 and s[i] != pattern[j]:
j = fail[j]
i += 1
j += 1
if j == m:
return i - m
return -1
复杂度分析
- 时间复杂度: O ( ∣ s ∣ + ∣ p a t t e r n ∣ ) O(|s|+|pattern|) O(∣s∣+∣pattern∣), 一次遍历 p a t t e r n pattern pattern 构建 f a i l fail fail 或 n e x t next next数组, O ( ∣ p a t t e r n ∣ ) O(|pattern|) O(∣pattern∣);一次遍历 s s s,匹配 p a t t e r n pattern pattern, O ( ∣ s ∣ ) O(|s|) O(∣s∣)。
- 空间复杂度: O ( ∣ p a a t t e r n ∣ ) O(|paattern|) O(∣paattern∣),存储 f a i l fail fail 或 n e x t next next 数组。
思路
我们也可以不「投机取巧」,而是使用 KMP 字符串匹配算法来找出这个最长的前缀回文串。
具体地,记 s ^ \hat{s} s^ 为 s s s 的反序,由于 s 1 s_1 s1 是 s s s 的前缀,那么 s ^ 1 \hat{s}_1 s^1 就是 s ^ \hat{s} s^ 的后缀。
考虑到 s 1 s_1 s1 是一个回文串,因此 s 1 = s ^ 1 s_1 = \hat{s}_1 s1=s^1, s 1 s_1 s1 同样是 s ^ \hat{s} s^ 的后缀。
这样一来,我们将 s s s 作为模式串, s ^ \hat{s} s^ 作为查询串进行匹配。当遍历到 s ^ \hat{s} s^ 的末尾时,如果匹配到 s s s 中的第 i i i 个字符,那么说明 s 的前 i i i 个字符与 s ^ \hat{s} s^ 的后 i i i 个字符相匹配(即相同), s s s 的前 i i i个字符对应 s 1 s_1 s1, s ^ \hat{s} s^的后 i i i 个字符对应 s ^ 1 \hat{s}_1 s^1,由于 s 1 = s ^ 1 s_1 = \hat{s}_1 s1=s^1,因此 s 1 s_1 s1 就是一个回文串。
如果存在更长的回文串,那么 KMP 算法的匹配结果也会大于 i i i,因此 s 1 s_1 s1 就是最长的前缀回文串。
作者:LeetCode-Solution
链接:https://leetcode-cn.com/problems/shortest-palindrome/solution/zui-duan-hui-wen-chuan-by-leetcode-solution/
来源:力扣(LeetCode)
代码
class Solution:
def shortestPalindrome(self, s: str) -> str:
if s[::-1] == s:
return s
def kmp(s, pattern):
n, m = len(s), len(pattern)
fail = [0] * m
fail[0] = -1
k = -1
j = 0
while j < m-1:
if k == -1 or pattern[k] == pattern[j]:
k += 1
j += 1
if pattern[k] == pattern[j]:
fail[j] = fail[k]
else:
fail[j] = k
else:
k = fail[k]
j = 0
i = 0
while i < n:
while j != -1 and pattern[j] != s[i]:
j = fail[j]
i += 1
j += 1
return j
j = kmp(s[::-1], s)
return s[j:][::-1] + s
复杂度分析
- 时间复杂度: O ( ∣ s ∣ ) O(|s|) O(∣s∣), O ( ∣ s ∣ + ∣ s ^ ∣ ) = O ( 2 × ∣ s ∣ ) = O ( ∣ s ∣ ) O(|s| + |\hat{s}|) = O(2\times|s|)=O(|s|) O(∣s∣+∣s^∣)=O(2×∣s∣)=O(∣s∣)
- 空间复杂度: O ( ∣ s ∣ ) O(|s|) O(∣s∣)
结果