用Python处理EXCEL表格(Openpyxl)
最近参加的数模比赛中需要处理有几百万行数据的EXCEL表格,刚刚接到这个任务时头是有点发昏的,大一的时候虽然学过Python,但还没有真正实现过用Python处理大数据。以题目中的附件一为例:附件一有60多万条数据附件二也有60多万条,加起来总共差不多有120多万条(有一题就是要我们筛选其中的某些数据。由于本人对EXCEL的不熟悉以及对编程的喜爱,因此在网上
![]()
搜索了不少关于如何用Python去处理大数据的方法:有很多方法,比如xlrd,pandas,openpyxl等等,本人在这里使用的是openpyxl。
①首先来看其中一个问题 ,在下面这样一个表中,需要我们根据create_dt这个属性计算出每天的日营业额及成本,也就是将日期相同的商品的售价及成本相加即可,代码如下:并将生成的表格记为“日营业额及成本(附件2).xlsx”
import openpyxl
from openpyxl import load_workbook
# 新建一个xlsx文件
wb = openpyxl.Workbook()
ws = wb.active
ws.cell(1, 1, '日期')
ws.cell(1, 2, '日营业额')
ws.cell(1, 3, '日成本')
# ws.cell(1, 4, '日利润')
workbook = load_workbook('补全并筛选后的表格(附件2).xlsx')
sheet = workbook['Sheet1']
num = sheet.max_row
k = 2
sums: int = sheet.cell(2, 6).value * sheet.cell(2, 8).value
sumt: int = sheet.cell(2, 6).value * sheet.cell(2, 9).value
judge = sheet.cell(2, 1).value
ws.cell(2, 1, sheet.cell(2, 1).value)
for i in range(3, num+1):
if sheet.cell(i, 5).value == 1 and sheet.cell(i, 6).value > 0:
if sheet.cell(i, 1).value == judge:
sums += (sheet.cell(i, 6).value * sheet.cell(i, 8).value)
sumt += (sheet.cell(i, 6).value * sheet.cell(i, 9).value)
if i == num:
ws.cell(k, 2, sums)
ws.cell(k, 3, sumt)
else:
ws.cell(k+1, 1, sheet.cell(i, 1).value)
ws.cell(k, 2, sums)
ws.cell(k, 3, sumt)
print(sheet.cell(i, 1).value)
k += 1
sums = sheet.cell(i, 6).value * sheet.cell(i, 8).value
sumt = sheet.cell(i, 6).value * sheet.cell(i, 9).value
judge = sheet.cell(i, 1).value
wb.save('日营业额及成本(附件2).xlsx')
workbook.close
注意:在我们用Pycharm运行这段Python代码时,你的项目文件夹里面一定得要有“补全并筛选后的表格(附件2).xlsx”这个文件:
②第二个问题是将附件1、附件2所求得的EXCEL表格合并为一(因为附件1、附件2均有同一日期的售卖额,但我通过比对发现,两附件的日期也不一定一致,比如附件2有2019/1/2号的售卖额,附件1就没有,因此这为之间通过EXECL合并造成了麻烦,这时我们的Python代码就派上了用处):
import openpyxl
from openpyxl import load_workbook
# 新建一个xlsx文件
wb = openpyxl.Workbook()
ws = wb.active
ws.cell(1, 1, '日期')
ws.cell(1, 2, '日营业额')
ws.cell(1, 3, '日成本')
# ws.cell(1, 4, '日利润')
workbook1 = load_workbook('日营业额及成本(附件1).xlsx')
workbook2 = load_workbook('日营业额及成本(附件2).xlsx')
sheet1 = workbook1['Sheet']
sheet2 = workbook2['Sheet']
num1 = sheet1.max_row
num2 = sheet2.max_row
k = 2
for i in range(2, num2+1):
if i <= num1:
a = sheet1.cell(i, 2).value+sheet2.cell(i, 2).value
b = sheet1.cell(i, 3).value+sheet2.cell(i, 3).value
ws.cell(i, 1, sheet2.cell(i, 1).value)
ws.cell(i, 2, a)
ws.cell(i, 3, b)
else:
a = sheet2.cell(i, 2).value
b = sheet2.cell(i, 3).value
ws.cell(i, 1, sheet2.cell(i, 1).value)
ws.cell(i, 2, a)
ws.cell(i, 3, b)
wb.save('日营业额及成本(合并后的总的结果).xlsx')
workbook1.close
workbook2.close
③第三个问题是根据商品的分类(附件4)计算出每一个类别商品的销售额、成本、原价和、折扣、利润,附件4的部分数据如下图所示:(first_category_id和first_category_name表示第一级分类的编号以及名字,其它第二级和第三级的信息只是干扰用的)由于每个商品的销售额、原价、成本等只在附件一和附件二中出现了,因此我们还应回到附件1和附件2进行处理:以处理附件1为例,代码如下:

import openpyxl
from openpyxl import load_workbook
# 新建一个xlsx文件
wb = openpyxl.Workbook()
ws = wb.active
ws.cell(1, 1, 'sku_id')
ws.cell(1, 2, 'sku_name')
ws.cell(1, 3, '销售额')
ws.cell(1, 4, '原价和')
ws.cell(1, 5, '成本和')
workbook1 = load_workbook('补全并筛选后的表格(附件1).xlsx', keep_vba=True, data_only=True)
sheet1 = workbook1['Sheet1']
num1 = sheet1.max_row
k = 2
sumx = sheet1.cell(2, 11).value
sumy = sheet1.cell(2, 12).value
sumz = sheet1.cell(2, 13).value
judge = sheet1.cell(2, 3).value
ws.cell(2, 1, sheet1.cell(2, 3).value)
ws.cell(2, 2, sheet1.cell(2, 4).value)
for i in range(3, num1+1):
if sheet1.cell(i, 3).value == judge:
sumx += sheet1.cell(i, 11).value
sumy += sheet1.cell(i, 12).value
sumz += sheet1.cell(i, 13).value
if i == num1:
ws.cell(k, 3, sumx)
ws.cell(k, 4, sumy)
ws.cell(k, 5, sumz)
else:
ws.cell(k + 1, 1, sheet1.cell(i, 3).value)
ws.cell(k + 1, 2, sheet1.cell(i, 4).value)
ws.cell(k, 3, sumx)
ws.cell(k, 4, sumy)
ws.cell(k, 5, sumz)
print(sumx)
print(sumy)
print(sumz)
k += 1
sumx = sheet1.cell(i, 11).value
sumy = sheet1.cell(i, 12).value
sumz = sheet1.cell(i, 13).value
judge = sheet1.cell(i, 3).value
wb.save('各商品的销售额、原价、成本和(附件1).xlsx')
workbook1.close
处理完附件1后,我们要接着处理附件2,最终我们要将两者的处理结果合并,代码如下:
import openpyxl
from openpyxl import load_workbook
# 新建一个xlsx文件
wb = openpyxl.Workbook()
ws = wb.active
ws.cell(1, 1, 'sku_id')
ws.cell(1, 2, 'sku_name')
ws.cell(1, 3, '销售额')
ws.cell(1, 4, '原价和')
ws.cell(1, 5, '成本和')
workbook1 = load_workbook('各商品的销售额、原价、成本和(附件1).xlsx', keep_vba=True, data_only=True)
workbook2 = load_workbook('各商品的销售额、原价、成本和(附件2).xlsx', keep_vba=True, data_only=True)
sheet1 = workbook1['Sheet']
sheet2 = workbook2['Sheet']
num1 = sheet1.max_row
num2 = sheet2.max_row
for i in range(2, num2+1):
for j in range(2, num1+1):
if sheet2.cell(i, 1).value == sheet1.cell(j, 1).value:
ws.cell(i, 1, sheet2.cell(i, 1).value)
ws.cell(i, 2, sheet2.cell(i, 2).value)
ws.cell(i, 3, sheet1.cell(j, 3).value + sheet2.cell(i, 3).value)
ws.cell(i, 4, sheet1.cell(j, 4).value + sheet2.cell(i, 4).value)
ws.cell(i, 5, sheet1.cell(j, 5).value + sheet2.cell(i, 5).value)
break
else:
ws.cell(i, 1, sheet2.cell(i, 1).value)
ws.cell(i, 2, sheet2.cell(i, 2).value)
ws.cell(i, 3, sheet2.cell(i, 3).value)
ws.cell(i, 4, sheet2.cell(i, 4).value)
ws.cell(i, 5, sheet2.cell(i, 5).value)
wb.save('各商品的销售额、原价、成本和.xlsx')
workbook1.close
处理结果见下图:(篇幅有限,只展示部分):然后我们要计算利润率、折扣率,这个只需

简单地使用EXCEL表格的函数就行了。
④第四个问题是要计算各类别的销售额、利润率和折扣率,因此我们要利用刚刚求得的各商品的销售情况表格进行分类再求和(也就是SQL中聚集函数的概念):代码如下:
import openpyxl
from openpyxl import load_workbook
# 新建一个xlsx文件
wb = openpyxl.Workbook()
ws = wb.active
ws.cell(1, 1, 'first_category_id')
ws.cell(1, 2, 'first_category_name')
ws.cell(1, 3, '销售额')
ws.cell(1, 4, '原价和')
ws.cell(1, 5, '成本和')
workbook1 = load_workbook('附件4中各商品的销售额、原价、成本和、类型.xlsx', keep_vba=True, data_only=True)
sheet1 = workbook1['Sheet']
num1 = sheet1.max_row
k = 2
sumx = sheet1.cell(2, 3).value
sumy = sheet1.cell(2, 4).value
sumz = sheet1.cell(2, 5).value
judge = sheet1.cell(2, 6).value
ws.cell(2, 1, sheet1.cell(2, 6).value)
ws.cell(2, 2, sheet1.cell(2, 7).value)
for i in range(3, num1+1):
if sheet1.cell(i, 6).value == judge:
sumx += sheet1.cell(i, 3).value
sumy += sheet1.cell(i, 4).value
sumz += sheet1.cell(i, 5).value
if i == num1:
ws.cell(k, 3, sumx)
ws.cell(k, 4, sumy)
ws.cell(k, 5, sumz)
else:
ws.cell(k + 1, 1, sheet1.cell(i, 6).value)
ws.cell(k + 1, 2, sheet1.cell(i, 7).value)
ws.cell(k, 3, sumx)
ws.cell(k, 4, sumy)
ws.cell(k, 5, sumz)
print(sumx)
print(sumy)
print(sumz)
k += 1
sumx = sheet1.cell(i, 3).value
sumy = sheet1.cell(i, 4).value
sumz = sheet1.cell(i, 5).value
judge = sheet1.cell(i, 6).value
wb.save('各类别的销售额、利润率、折扣率.xlsx')
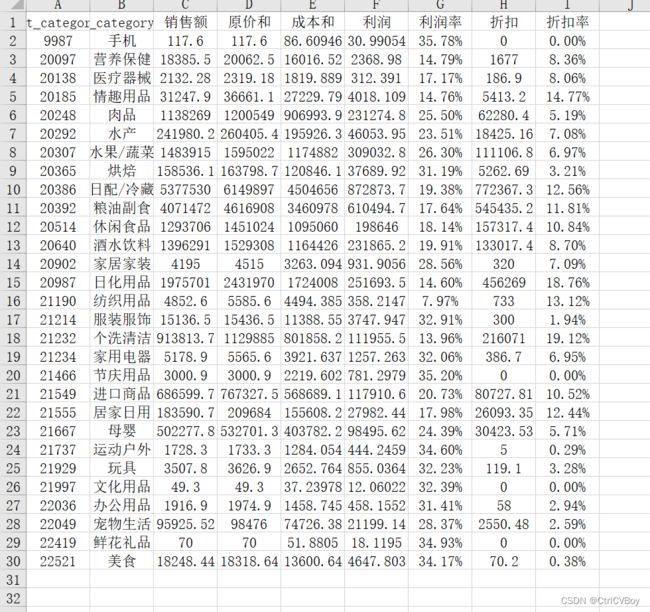
workbook1.close求得的结果如图所示:此时也发现总共有29种商品:
总结:Python可帮助我们轻松地处理EXCEL数据,但当EXCEL表格数据量比较大时(像我这里的数据这样)运行代码可能需要几分钟,但对于程序员开启懒人模式是很快乐的,大量的处理交给了程序自己去完成,也降低了错误出现的概率。