【Mysql】上号(连接数据库)操作一把——增删改查
目录
SQL语句
DDL——数据定义语言
#1. 操作数据库
1)创建数据库
2)查看所有数据库
3)删除数据库(危险!!)
4)使用数据库
5)查看数据库中的表
#2. 操作数据表(表结构)
1)创建表
2)数据库表的字段注释
3)查看表结构
4)修改表名(不常用,表名一般是确定的)
5)删除字段(危险!!)
6)添加字段
7)修改字段(modify、change)
8)删除表
DML——数据操作语言
#1. 新增——insert
1)全字段插入
2)不完全字段插入
3)一次性添加多条数据
4)不推荐使用(边查询边插入,IO太大,易锁死)
#2. 修改——update
1)整张表的修改
2)带条件的修改
3)多条件修改
4)范围性的多条件修改
#3. 删除——delete
1)整表删除(不加条件)
2)带条件的删除
3)清空表
delete、truncate、drop的区别
DQL——数据查询语言(select)
#1. 单表查询
书写顺序
1)最简单的查询
2)全字段查询
3)部分字段查询
4)基本表查询与简单查询的结合
5)给字段起别名
6)去重
7)带条件的查询
8)模糊查询
9)IN
10)查询Null值
11)聚合函数
12)分组
13)分组后的数据筛选——Having
where和having的区别
14)排序
15)分页
16)Offset——Mysql8的新关键词
#2. 多表联查
1)非等值联查
2)等值联查(内联查询)——查询两个表的共有数据
3)外联查询
4)查询两个表中某个表的独有数据
SQL语句
| 名词 | 简写 | 解释 | 关键词 |
|---|---|---|---|
| 数据定义语言 | DDL | 定义、管理数据库、数据表 | CREATE/DROP/ALTER |
| 数据操作语言 | DML | 操作数据库对象中的数据 | INSERT/UPDATE/DELETE |
| 数据查询语言 | DQL | 查询数据库中的数据 | SELECT |
| 数据控制语言 | DCL | 管理数据库,管理权限与数据更改 | GRANT/COMMIT/ROLLBACK |
本文重点就前三类语言进行简要说明。
DDL——数据定义语言
#1. 操作数据库
1)创建数据库
create database 库名;
- 在Sql语言中不区分大小写,因此不适用驼峰命名法,而是用下划线进行分割。
- 一般规定关键字大写,其他单词小写
- ; 表示语句结束
2)查看所有数据库
show databases;3)删除数据库(危险!!)
drop database 库名;注意:这是危险操作,在使用数据库的原则上有一点是,宁可数据冗余,也不删除
4)使用数据库
use database 库名;当我们创建一个数据库后,并没有直接使用此数据库。
5)查看数据库中的表
show tables;也可以利用此操作查看到现在使用的是什么数据库。
#2. 操作数据表(表结构)
此操作不包括修改表内的数据。
1)创建表
create table 表名(
字段名 数据类型 属性,
字段名 数据类型 属性,
字段名 数据类型 属性)
- 与其他编译语言不同的就是,Sql语言是先声明字段名再声明类型的。
- 字段名就是表格上的列名。
数据类型
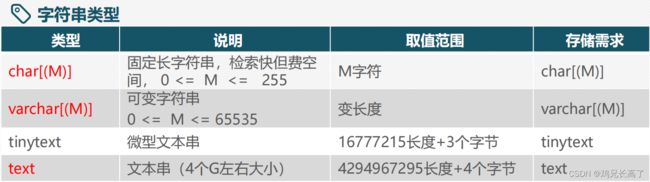
| 类型 | 长度 | 优缺点 |
|---|---|---|
| char(设置最大长度) | 固定长度(长度=最大长度) | 浪费存储空间,速度较快 |
| varchar(设置最大长度) | 可变长度(长度<=最大长度) | 节约存储空间,速度较慢 |
varchar速度较慢的原因是,存储时长度是可变的,但取值时需要计算长度,此计算过程较费时间。身份证号、手机号存成可变长度不仅没有意义,还影响速度——使用char存储,固定其存储长度;住址用固定长度浪费空间——使用varchar存储,节约存储空间。
 之所以不使用浮点型来存储钱等一类需要十分精确的数值的原因是,在不同的计算机中,浮点型的精度是不同的,Decimal类型的第一个属性值为总长度,第二个为小数位数。例如成绩可以将类型设置为Decimal(4,1)。
之所以不使用浮点型来存储钱等一类需要十分精确的数值的原因是,在不同的计算机中,浮点型的精度是不同的,Decimal类型的第一个属性值为总长度,第二个为小数位数。例如成绩可以将类型设置为Decimal(4,1)。
公司中一般使用tinyint表示性别(0,1),这样可以节省空间,只需要在查询的时候使用一些方法对此值进行转换。

Null类型
- 表示没有值、未知值
- Null的运算结果也是Null
- 数据库中没有Boolean类型
- 在Mysql中0/Null都为假,只有1为真
2)数据库表的字段注释
create table 表名(
字段名 数据类型 属性 comment '注释',
字段名 数据类型 属性 comment '注释',
字段名 数据类型 属性 comment '注释')数据库中使用' ' 或者 " "包裹文字表示字符串,可任意使用,但要保证前后对应以及代码风格统一。
3)查看表结构
desc(或者describe) 表名; 查询学生表可得到以下结果。 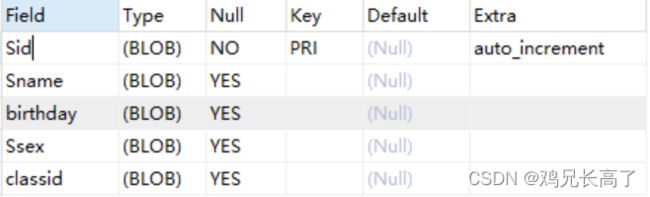
show create table 表名; 复制返回的结果可以得到这样详细的信息,类似于我们新建一个表的格式。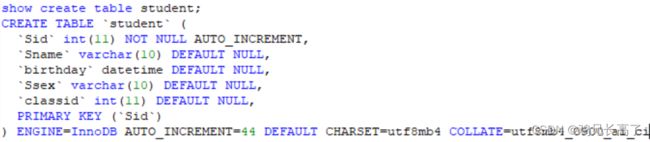
我们可以看到,在字段名上,系统给自动加了``反引号,目的是取消关键性,如table是Mysql中的关键词,我们不能创建一个叫table的表,但如果我们给table加了反引号就可以创建了。
4)修改表名(不常用,表名一般是确定的)
alter table 旧表名 rename as 新表名;5)删除字段(危险!!)
alter table 表名 drop 字段名;依旧请出我们不成文的规定:宁滥勿缺!
删除字段时,字段中的数据也会被删除——相当于删除表格的一整列。
6)添加字段
alter table 表名 add 字段名 数据类型 属性;add后面的格式与建表的语法相同。
7)修改字段(modify、change)
alter table 表名 modify 要修改的字段名 要修改的内容(数据类型、属性);
- 此类修改是根据字段名修改其属性,不能修改字段名
- 是一种完全修改,如果修改的内容只写了数据类型,其注释、其他限制属性就没有了
- 当字段中有数据时,修改要考虑是否兼容,如果为空表则可以直接修改
- 兼容可类比java中数据类型转换来思考,大范围数据类型装在小范围数据类型中会出现问题
取舍问题:
改表结构——删掉内容再进行修改
改数据——添加一列再来修改
alter table 表名 change 旧字段名 新字段名 数据类型 属性;也是完全替代的修改——写了的修改,没写的就没有此属性了。可以修改字段名,也要注意数据兼容性!
8)删除表
drop table 表名;删除表,表中数据也会被删除。
DML——数据操作语言
#1. 新增——insert
1)全字段插入
insert into 表名(字段名...,字段名) values/value (值...,值);注意:
- 需要书写所有的字段名,顺序可以不一致,但后面值得顺序必须与字段书写顺序一致
- 使用"" 或者''表示字符串本质是没有差别的,但是'我"和"你' "心'连'心"中间的引号就不再表示字符串了
- 日期使用字符串的类型、日期的格式来书写('2000-1-1' 月、日是否使用0占位都可以),但是不能直接写2000-1-1,系统认为这是数学运算
2)不完全字段插入
刚刚说到全字段插入的时候要写全所有的字段名或值,有一些特定的情况不需要进行全字段插入。
- 主键设置了主键自增 。
- 字段设置了默认值。
3)一次性添加多条数据
insert into 表名(字段名...,字段名) values (值...,值),(值...,值);4)不推荐使用(边查询边插入,IO太大,易锁死)
insert into 表名(字段名...,字段名) select 字段...,字段名 from 表名前提:查询表和插入表都要存在,列数与类型要相同
create table 表名 select 字段...,字段名 from 表名前提:查询表要存在,插入表不能存在
#2. 修改——update
1)整张表的修改
update 表名 set 字段名 = 值,字段名 = 值,字段名 = 值;会将整个字段修改成一样的值。
2)带条件的修改
update 表名 set 字段名 = 值,字段名 = 值,字段名 = 值 where 子句[条件];3)多条件修改
where子句中在条件中加连接符号(AND——表并且/OR——表或者)。
注意:没有符号表示的形式!
4)范围性的多条件修改
- 使用AND/OR
- 使用between...and...
between A and B 表示>=A , <=B。between后的数据只能向右查找,and后的数据只能向左查找,因此一般between后写较小数据,and后写较大数据。

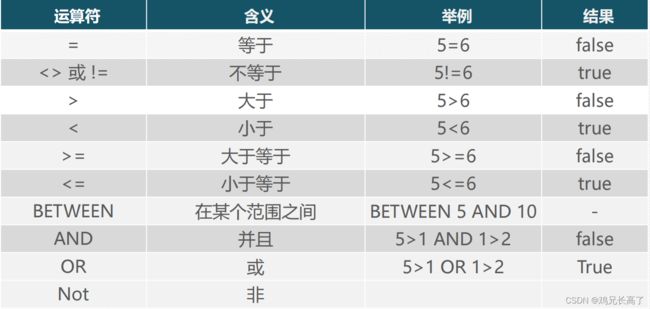
=在where前表示赋值,在where后表示判断。
#3. 删除——delete
1)整表删除(不加条件)
delete from 表名;2)带条件的删除
delete from 表名 where 条件;删除数据不能清空主键自增的序号。
3)清空表
truncate 表名;将整张表的数据、索引、主键自增的序号全部清空,保留表结构(约束还在)。
delete、truncate、drop的区别
| delete | 只删除数据 | DML |
| truncate | 删除数据、清空索引 | |
| drop | 删除数据、清空索引、删除表结构 | DDL |
DQL——数据查询语言(select)
#1. 单表查询
书写顺序

1)最简单的查询
没有什么意义,如select 'a' select 123+456
2)全字段查询
select 字段名...,字段名(全部字段) from 表名;select * from 表名;*是通配符,比上面那种写法查询速度慢:
- 先“翻译”字段名称,代替*
- 再查询
二者查询到的结果相同。
sql优化的第一步就是不使用*而使用字段名来查询。
3)部分字段查询
select 字段名...,字段名(部分字段) from 表名;在sql查询中,一切皆虚表。查询完得到的结构——>虚拟表(不在磁盘上)。
4)基本表查询与简单查询的结合
当想给表的每一列都加上相同的一个属性值,可以在查询字段名后加,'属性的值' ,会获得一列全为此值的新列。
5)给字段起别名
select 字段名 as '别名' from 表名;一般将as与' '省略。
6)去重
select distinct 字段名...,字段名 from 表名;每个相同的只显示一个,前提是除了这些字段以外,其他字段也完全一致。
此去重的特点是:要求每个字段完全一致。
7)带条件的查询
select 字段名 from 表名 where 条件;8)模糊查询
select 字段名 from 表名 where 字段名 like 条件(字符串);| 模糊符号 | 含义 |
|---|---|
| % | 任意多个任意字符(包括0个) |
| _ | 一个任意字符(固定模糊个数) |
| 前模糊 | %key |
| 后模糊 | key% |
| 前后都模糊 | %key% |
9)IN
select 字段名 from 表名 where 字段名 in (值...,值);表示在某个特定的范围内。是另一种写法的简单写法(与or的作用一致)。
select 字段名 from 表名 where 字段名 = 值1 or 字段名 = 值2...;10)查询Null值
使用 is null(查没有值得)或者 is not null(查有值得)。
因为null是一种数据类型,但它不参与运算,所以不能使用=。
11)聚合函数
聚合函数是将很多个值变成一个值。
select 字段名,聚合函数 from 表名 where 条件;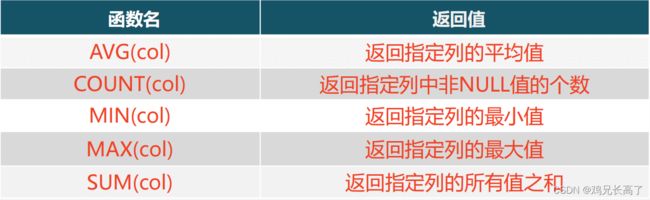
count()特点:
- 不统计null值
- 数据是否重复不影响结果
- 如果想统计数据总条数:
- 传 *
- 字段(有唯一性约束的、主键)
- 任意常量
12)分组
类似于Excel中合并单元格。
select 字段名 from 表名 where 条件 group by 字段名;如查询这个班男女分别多少人?有两种查询方法:
select ssex,count(*) from student where ssex = '男';
select ssex,count(*) from student where ssex = '女';这种方法需要查询两次。
select ssex,count(*) from student group by ssex;这种方法只需要查询一次。
13)分组后的数据筛选——Having
sql的查询语法是有顺序要求的,where必须写在group by前面,如果分组后想再次筛选数据需要使用having。
select 字段名 from 表名 group by 字段名 having 条件;注意:having不能单独出现,必须有group by。
where和having的区别
| where | 针对的是表中的每一行数据进行筛选 |
| having | 针对的是分组后每一行数据进行筛选 |
14)排序
查询出的结果默认按主键升序排序。
select 字段名 from 表名 order by 字段名 排序规则;| desc | 降序 |
| asc | 升序 |
也可以进行多字段排序,先写的先排,如果值相等再按照下一个规则排序,中间使用 ,隔开。不写的按照默认排序规则(字符串也有默认的排序规则,但是较为复杂)。
15)分页
select 字段名 from 表名 limit 位置,步长;
- 位置、步长(显示个数)都是数字
- 如果只写一个数字表示只显示x条数据(省略了0,)
- Mysql有下标,从0开始,limit 1,3表示跳过1个条数据,显示3条数据
- 分页公式: (页码-1)* 步长,步长
- 查看第几页数据是由用户决定的,应在应用层传值
16)Offset——Mysql8的新关键词
select 字段名 from 表名 limit 显示条数 offset 跳过页数;#2. 多表联查
1)非等值联查
select * from student,class;得到的是笛卡尔积,数据庞大且无关联。
2)等值联查(内联查询)——查询两个表的共有数据
select * from student,class where student.classid = class.classid;select * from student inner join class
on student.classid = class.classid;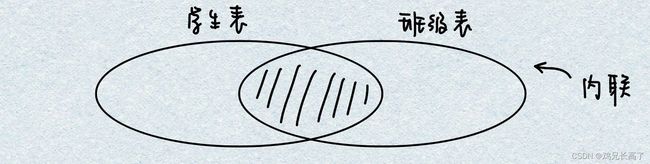
3)外联查询
需要分清哪个是主表,哪个是从表
| left join on | 左外联 | 主表 left join 从表 on 条件 |
| right join on | 右外联 | 从表 right join 主表 on 条件 |
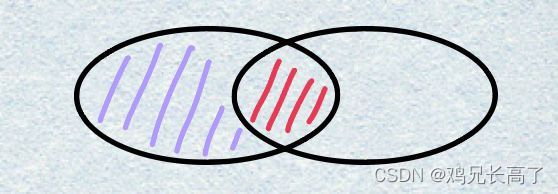
4)查询两个表中某个表的独有数据
select * from t1 left join t2 on t1.id = t2.id where t2.id is null;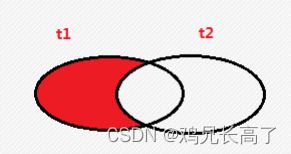
select * from t1 right join t2 on t1.id = t2.id where t1.id is null;