已解决Python爬虫网页中文乱码问题
已解决Python爬虫网页中文乱码问题
文章目录
- 报错代码
- 乱码原因
- 解决方法
- 千人全栈VIP答疑群联系博主帮忙解决报错
报错代码
粉丝群里面的一个粉丝在用Python爬取网页源码,但是拿到的源码却是乱码的(跑来找我求助,然后顺利帮助他解决了,顺便记录一下希望可以帮助到更多遇到这个bug不会解决的小伙伴),报错信息和代码如下:
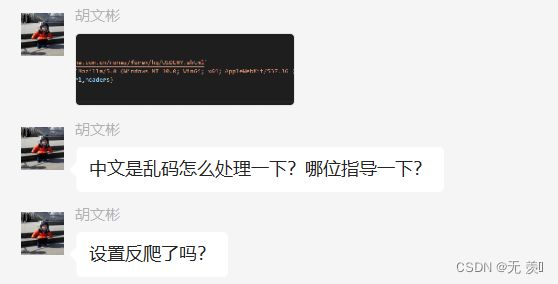
打印的网页如下:
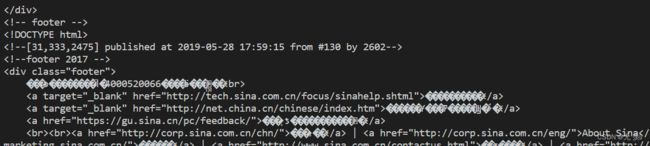
乱码原因
乱码原因:
出现乱码的原因一般是网页的编解码的问题。小伙伴只要按下面的方法设置和网页对应的编码格式即可!!!
解决方法
(1)设置编解格式即可,一般是设置utf-8:
response.encoding="utf-8"
(2)但是如果网页是gb2312编码格式如下所示:
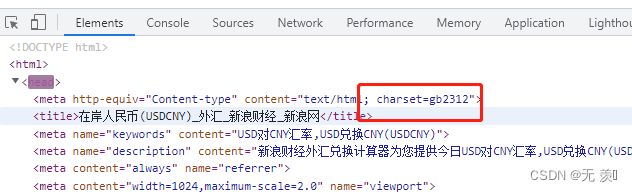
就需要设置为:
response.encoding="gb2312"
再次运行就成功了:

以上是此问题报错原因的解决方法,欢迎评论区留言讨论是否能解决,如果有用欢迎点赞收藏文章谢谢支持,博主才有动力持续记录遇到的问题!!!
千人全栈VIP答疑群联系博主帮忙解决报错
由于博主时间精力有限,每天私信人数太多,没办法每个粉丝都及时回复,所以优先回复VIP粉丝,可以通过订阅限时9.9付费专栏《100天精通Python从入门到就业》进入千人全栈VIP答疑群,获得优先解答机会(代码指导、远程服务),白嫖80G学习资料大礼包,专栏订阅地址:https://blog.csdn.net/yuan2019035055/category_11466020.html
-
优点:作者优先解答机会(代码指导、远程服务),群里大佬众多可以抱团取暖(大厂内推机会),此专栏文章是专门针对零基础和需要进阶提升的同学所准备的一套完整教学,从0到100的不断进阶深入,后续还有实战项目,轻松应对面试!
-
专栏福利:简历指导、招聘内推、每周送实体书、80G全栈学习视频、300本IT电子书:Python、Java、前端、大数据、数据库、算法、爬虫、数据分析、机器学习、面试题库等等
-
注意:如果希望得到及时回复,订阅专栏后私信博主进千人VIP答疑群


