Structured Streaming 入门(整合、数据分析)
#博学谷IT学习技术支持#
Sink扩展: 三种消息语义
流式数据处理步骤
针对任何流式应用处理框架(Storm、SparkStreaming、StructuredStreaming和Flink等)处理数据时,都要考虑语义,任意流式系统处理流式数据三个步骤:
1、Receiving the data:接收数据源端的数据
采用接收器或其他方式从数据源接收数据(The data is received from sources using Receivers or otherwise)。
2、Transforming the data:转换数据,进行处理分析
针对StructuredStreaming来说就是Stream DataFrame(The received data is transformed using DStream and RDD transformations)。
3、Pushing out the data:将结果数据输出
最终分析结果数据推送到外部存储系统,比如文件系统HDFS、数据库等(The final transformed data is pushed out to external systems like file systems, databases, dashboards, etc)。
三种语义:
在处理数据时,往往需要保证数据处理一致性语义:从数据源端接收数据,经过数据处理分析,到最终数据输出仅被处理一次,是最理想最好的状态。在Streaming数据处理分析中,需要考虑数据是否被处理及被处理次数,称为消费语义,
1、At most once:最多一次,可能出现不消费,数据丢失;
2、At least once:至少一次,数据至少消费一次,可能出现多次消费数据;
3、Exactly once:精确一次,数据当且仅当消费一次,不多不少。
Structured Streaming的Extracly-Once
Structured Streaming的核心设计理念和目标之一:支持一次且仅一次Extracly-Once的语义。
为了实现这个目标,Structured Streaming设计source、sink和execution engine来追踪计算处理的进度,这样就可以在任何一个步骤出现失败时自动重试。
1、每个Streaming source都被设计成支持offset,进而可以让Spark来追踪读取的位置;
2、对于Operations,Spark基于checkpoint和wal来持久化保存每个trigger interval内处理的offset的范围;
3、Sink被设计成可以支持在多次计算处理时保持幂等性,就是说,用同样的一批数据,无论多少次去更新sink,都会保持一致和相同的状态。
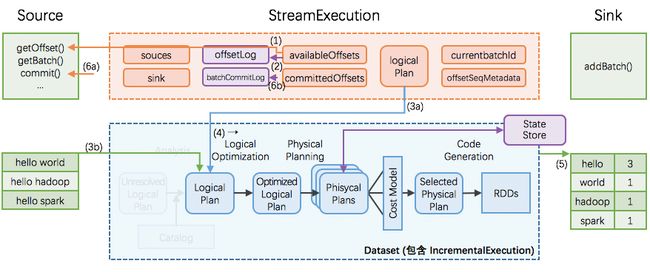
综合利用基于offset的source,基于checkpoint和wal的execution engine,以及基于幂等性的sink,可以支持完整的一次且仅一次的语义。
Source一致性语义支持:
Source |
Options |
Fault-tolerant |
Notes |
File source |
path: path to the input directory, and common to all file formats. maxFilesPerTrigger: maximum number of new files to be considered in every trigger (default: no max) latestFirst: whether to process the latest new files first, useful when there is a large backlog of files (default: false) fileNameOnly: whether to check new files based on only the filename instead of on the full path (default: false). With this set to `true`, the following files would be considered as the same file, because their filenames, "dataset.txt", are the same: "file:///dataset.txt" "s3://a/dataset.txt" "s3n://a/b/dataset.txt" "s3a://a/b/c/dataset.txt" maxFileAge: Maximum age of a file that can be found in this directory, before it is ignored. For the first batch all files will be considered valid. If latestFirst is set to `true` and maxFilesPerTrigger is set, then this parameter will be ignored, because old files that are valid, and should be processed, may be ignored. The max age is specified with respect to the timestamp of the latest file, and not the timestamp of the current system.(default: 1 week) cleanSource: option to clean up completed files after processing. Available options are "archive", "delete", "off". If the option is not provided, the default value is "off". When "archive" is provided, additional option sourceArchiveDir must be provided as well. The value of "sourceArchiveDir" must not match with source pattern in depth (the number of directories from the root directory), where the depth is minimum of depth on both paths. This will ensure archived files are never included as new source files. For example, suppose you provide '/hello?/spark/*' as source pattern, '/hello1/spark/archive/dir' cannot be used as the value of "sourceArchiveDir", as '/hello?/spark/*' and '/hello1/spark/archive' will be matched. '/hello1/spark' cannot be also used as the value of "sourceArchiveDir", as '/hello?/spark' and '/hello1/spark' will be matched. '/archived/here' would be OK as it doesn't match. Spark will move source files respecting their own path. For example, if the path of source file is /a/b/dataset.txt and the path of archive directory is /archived/here, file will be moved to /archived/here/a/b/dataset.txt. NOTE: Both archiving (via moving) or deleting completed files will introduce overhead (slow down, even if it's happening in separate thread) in each micro-batch, so you need to understand the cost for each operation in your file system before enabling this option. On the other hand, enabling this option will reduce the cost to list source files which can be an expensive operation. Number of threads used in completed file cleaner can be configured with spark.sql.streaming.fileSource.cleaner.numThreads (default: 1). NOTE 2: The source path should not be used from multiple sources or queries when enabling this option. Similarly, you must ensure the source path doesn't match to any files in output directory of file stream sink. NOTE 3: Both delete and move actions are best effort. Failing to delete or move files will not fail the streaming query. Spark may not clean up some source files in some circumstances - e.g. the application doesn't shut down gracefully, too many files are queued to clean up. For file-format-specific options, see the related methods in DataStreamReader (Scala/Java/Python/R). E.g. for "parquet" format options see DataStreamReader.parquet(). In addition, there are session configurations that affect certain file-formats. See the SQL Programming Guide for more details. E.g., for "parquet", see Parquet configuration section. |
Yes |
Supports glob paths, but does not support multiple comma-separated paths/globs. |
Socket Source |
host: host to connect to, must be specified port: port to connect to, must be specified |
No |
|
Rate Source |
rowsPerSecond (e.g. 100, default: 1): How many rows should be generated per second. rampUpTime (e.g. 5s, default: 0s): How long to ramp up before the generating speed becomes rowsPerSecond. Using finer granularities than seconds will be truncated to integer seconds. numPartitions (e.g. 10, default: Spark's default parallelism): The partition number for the generated rows. The source will try its best to reach rowsPerSecond, but the query may be resource constrained, and numPartitions can be tweaked to help reach the desired speed. |
Yes |
|
Kafka Source |
See the Kafka Integration Guide. |
Yes |
Sink一致性语义支持:
Sink |
Supported OutputModes |
Options |
Fault-tolerant |
Notes |
File Sink |
Append |
path: path to the output directory, must be specified. retention: time to live (TTL) for output files. Output files which batches were committed older than TTL will be eventually excluded in metadata log. This means reader queries which read the sink's output directory may not process them. You can provide the value as string format of the time. (like "12h", "7d", etc.) By default it's disabled. For file-format-specific options, see the related methods in DataFrameWriter (Scala/Java/Python/R). E.g. for "parquet" format options see DataFrameWriter.parquet() |
Yes (exactly-once) |
Supports writes to partitioned tables. Partitioning by time may be useful. |
Kafka Sink |
Append, Update, Complete |
See the Kafka Integration Guide |
Yes (at-least-once) |
More details in the Kafka Integration Guide |
Foreach Sink |
Append, Update, Complete |
None |
Yes (at-least-once) |
More details in the next section |
ForeachBatch Sink |
Append, Update, Complete |
None |
Depends on the implementation |
More details in the next section |
Console Sink |
Append, Update, Complete |
numRows: Number of rows to print every trigger (default: 20) truncate: Whether to truncate the output if too long (default: true) |
No |
|
Memory Sink |
Append, Complete |
None |
No. But in Complete Mode, restarted query will recreate the full table. |
Table name is the query name. |
2.整合Kafka
Apache Kafka 是目前最流行的一个分布式的实时流消息系统,给下游订阅消费系统提供了并行处理和可靠容错机制,现在大公司在流式数据的处理场景,Kafka基本是标配。
Structured Streaming能够很好的集成Kafka,从Kafka拉取消息,然后就可以把流数据看做一个DataFrame, 一张无限增长的大表,在这个大表上做查询,Structured Streaming保证了端到端的 exactly-once,用户只需要关心业务即可,不用费心去关心底层是怎么做的StructuredStreaming既可以从Kafka读取数据,还可以向Kafka 写入数据
整合Kafka准备工作
StructuredStreaming在整合Kafka的时候, 需要依赖相关的整合包, 对于使用Python而言, 在测试环境中, 我们需要将其所依赖的相关依赖包导入spark环境中,如果在生产环境中, 可以选择通过spark-submit方式指定jar包依赖的方式来处理
测试环境
当我们通过在pycharm右键运行的时候, 在python代码中, 我们会指定spark环境所在的位置, 此时需要将相关的依赖包添加到spark的jars目录下
1- jar包位置:
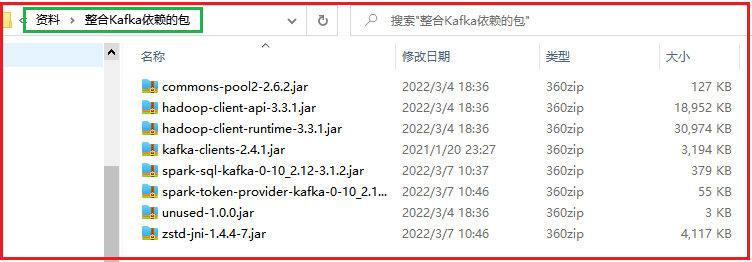
2- 将jar包上传到spark的jars目录下
cd /export/server/spark/jars/
rz 上传即可注意: 如果添加后, 后续还报找不到jar类似的错误, 可以尝试将jar包拷贝到python的pyspark库的jars目录下, 同时也可以拷贝到hdfs上的spark的jars目录下

生产环境
与任何 Spark 应用程序一样,spark-submit用于启动您的应用程序。spark-sql-kafka-0-10_2.12 并且它的依赖可以直接添加到spark-submitusing 中--packages,例如,
./bin/spark-submit --packages org.apache.spark:spark-sql-kafka-0-10_2.12:3.1.2 ...
测试中
./bin/spark-shell --packages org.apache.spark:spark-sql-kafka-0-10_2.12:3.1.2 ...从kafka读取数据
Structured Streaming整合Kafka:
# 消费1个Topicdf = spark \
.readStream \
.format("kafka") \
.option("kafka.bootstrap.servers", "host1:port1,host2:port2") \
.option("subscribe", "topic1") \
.load()
df.selectExpr("CAST(key AS STRING)", "CAST(value AS STRING)")
# 消费多个Topicdf = spark \
.readStream \
.format("kafka") \
.option("kafka.bootstrap.servers", "host1:port1,host2:port2") \
.option("subscribe", "topic1,topic2") \
.load()
df.selectExpr("CAST(key AS STRING)", "CAST(value AS STRING)")
# 基于规则消费符合规则的Topic中的数据df = spark \
.readStream \
.format("kafka") \
.option("kafka.bootstrap.servers", "host1:port1,host2:port2") \
.option("subscribePattern", "topic.*") \
.load()
df.selectExpr("CAST(key AS STRING)", "CAST(value AS STRING)")
批处理源与kafka集成
# 订阅一个Topic主题, 默认从最早到最晚的偏移量范围df = spark \
.read \
.format("kafka") \
.option("kafka.bootstrap.servers", "host1:port1,host2:port2") \
.option("subscribe", "topic1") \
.load()df.selectExpr("CAST(key AS STRING)", "CAST(value AS STRING)")
# 订阅多个Topic, 明确指定偏移量df = spark \
.read \
.format("kafka") \
.option("kafka.bootstrap.servers", "host1:port1,host2:port2") \
.option("subscribe", "topic1,topic2") \
.option("startingOffsets", """{"topic1":{"0":23,"1":-2},"topic2":{"0":-2}}""") \
.option("endingOffsets", """{"topic1":{"0":50,"1":-1},"topic2":{"0":-1}}""") \
.load()df.selectExpr("CAST(key AS STRING)", "CAST(value AS STRING)")
# 订阅符合规则的Topic, 指定从最早到最晚的偏移量范围df = spark \
.read \
.format("kafka") \
.option("kafka.bootstrap.servers", "host1:port1,host2:port2") \
.option("subscribePattern", "topic.*") \
.option("startingOffsets", "earliest") \
.option("endingOffsets", "latest") \
.load()df.selectExpr("CAST(key AS STRING)", "CAST(value AS STRING)")读取后的数据结构说明
基于sparkSession读取后 返回的都是一个DF的对象, 也就是说是一个二维的表:
列名 |
类型 |
key |
binary |
value |
binary |
topic |
string |
partition |
int |
offset |
long |
timestamp |
timestamp |
timestampType |
int |
headers (optional) |
array |
相关的参数
必备参数:
选项 |
值 |
说明 |
assign |
通过一个Json 字符串的方式来表示: {"topicA":[0,1],"topicB":[2,4]} |
设置使用特定的TopicPartitions,Kafka源代码只能指定一个"assign", "subscribe"或"subscribePattern"选项。 |
subscribe |
以逗号分隔的主题列表 |
要订阅的主题列表,Kafka源代码只能指定一个"assign", "subscribe"或"subscribePattern"选项。 |
subscribePattern |
正则表达式字符串 |
订阅匹配符合条件的Topic。Kafka源代码只能指定一个“assign”,“subscribe”或“subscribePattern”选项。 |
kafka.bootstrap.servers |
以逗号分隔的host:port列表 |
指定kafka服务的地址 |
可选参数:
选项 |
值 |
默认值 |
支持查询类型 |
说明 |
startingOffsetsByTimestamp |
通过Json字符串来配置: """ {"topicA":{"0": 1000, "1": 1000}, "topicB": {"0": 2000, "1": 2000}} """ |
无(startingOffsets将应用的值) |
streaming and batch |
查询开始时间戳的起始点,一个json字符串,指定每个TopicPartition的起始时间戳。每个分区返回的偏移量是对应分区中时间戳大于或等于给定时间戳的最早偏移量。如果匹配的偏移量不存在,查询将立即失败,以防止从该分区进行意外读取。 注意:对于流式查询,这仅适用于新查询开始时,并且恢复将始终从查询停止的地方开始。查询期间新发现的分区将最早开始。 |
startingOffsets |
"earliest", "latest" , or 通过json字符串 """ {"topicA":{"0":23,"1":-1},"topicB":{"0":-2}} """ |
"latest" 表示流, "earliest" 表示批处理 |
streaming and batch |
查询开始时的起始点,可以是“最早的”(从最早的偏移量开始),也可以是“最新的”(从最近的偏移量开始),或者是为每个TopicPartition指定起始偏移量的json字符串。在json中,-2作为偏移量可以用来指代最早的,-1到最新的。注意:对于批量查询,latest(隐式或在json中使用-1)是不允许的。对于流查询,这只适用于新查询开始时,而恢复将总是从查询停止的地方开始。查询期间新发现的分区将最早启动。 |
endingOffsetsByTimestamp |
json 字符串 """ {"topicA":{"0": 1000, "1": 1000}, "topicB": {"0": 2000, "1": 2000}} """ |
latest |
batch query |
批量查询结束时的结束点,为每个TopicPartition指定结束时间戳的json字符串。每个分区返回的偏移量是其时间戳大于或等于对应分区中给定时间戳的最早偏移量。如果匹配的偏移量不存在,则将偏移量设置为latest。 注:endingOffsetsByTimestamp优先于endingOffsets。 |
endingOffsets |
latest or json string {"topicA":{"0":23,"1":-1},"topicB":{"0":-1}} |
latest |
batch query |
批量查询结束时的结束点,可以是“latest”(仅引用最新的),也可以是为每个TopicPartition指定结束偏移量的json字符串。在json中,-1作为偏移量可以用来引用latest, -2(最早的)作为偏移量是不允许的。 |
failOnDataLoss |
true or false |
true |
streaming and batch |
当数据可能丢失(例如,主题被删除,或者偏移量超出范围)时,查询是否失败。当它不像期望的那样工作时,您可以禁用它。 |
kafkaConsumer.pollTimeoutMs |
long |
120000 |
streaming and batch |
在执行器中从Kafka轮询数据的超时时间(毫秒)。如果没有定义,则返回spark.network.timeout。 |
fetchOffset.numRetries |
int |
3 |
streaming and batch |
在放弃取回Kafka偏移量之前重试的次数。 |
fetchOffset.retryIntervalMs |
long |
10 |
streaming and batch |
在重新尝试获取Kafka偏移量之前等待的毫秒数 |
maxOffsetsPerTrigger |
long |
none |
streaming and batch |
每个触发间隔处理的最大偏移量的速率限制。指定的偏移量总数将在不同卷的topicPartitions上按比例分割。 |
minPartitions |
int |
none |
streaming and batch |
从Kafka读取所需的最小分区数。默认情况下,Spark有一个1-1的topicPartitions到Spark分区的映射,从Kafka消费。如果你设置这个选项的值大于你的topicPartitions, Spark会把大的Kafka分区划分成小块。请注意,这个配置就像一个提示:Spark任务的数量将大约为minPartitions。它可以更少或更多,取决于舍入错误或Kafka分区没有接收任何新数据。 |
groupIdPrefix |
string |
spark-kafka-source |
streaming and batch |
由结构化流查询生成的消费者组标识符(group.id)的前缀。如果“kafka.group。Id "被设置时,此选项将被忽略。 |
kafka.group.id |
string |
none |
streaming and batch |
当从Kafka中读取时,在Kafka消费者中使用的Kafka组id |
includeHeaders |
boolean |
false |
streaming and batch |
是否在行中包含卡夫卡头。 |
将数据写入到Kafka中
Apache Kafka 仅支持至少一次写入语义。因此,当向 Kafka 写入流式查询或批量查询时,一些记录可能会重复;例如,如果 Kafka 需要重试未经 Broker 确认的消息,即使该 Broker 接收并写入消息记录,也会发生这种情况。由于这些 Kafka 写入语义,结构化流式处理无法防止此类重复的发生。但是,如果写入查询成功,那么可以假设查询输出至少被写入一次。在读取写入数据时删除重复项的一种可能解决方案是引入一个主(唯一)键,该键可用于在读取时执行重复数据删除。
如果要写入到KAFKA中, DF中需要具备以下列:
列 |
类型 |
key (可选) |
string or binary |
value (必填) |
string or binary |
headers (可选) |
array |
topic (*可选) |
string |
partition (可选) |
int |
* 如果未指定“主题”配置选项,则需要主题列。
必备配置:
选项 |
价值 |
意义 |
kafka.bootstrap.servers |
逗号分隔的主机列表:端口 |
Kafka“bootstrap.servers”配置。 |
可选配置
选项 |
值 |
默认 |
查询类型 |
意义 |
topic |
string |
没有任何 |
流式传输和批处理 |
设置将在 Kafka 中写入所有行的主题。此选项会覆盖数据中可能存在的任何主题列。 |
includeHeaders |
boolean |
错误的 |
流式传输和批处理 |
是否在行中包含 Kafka 标头。 |
代码演示:
流式处理
# 从DataFrame中写入key-value数据到指定的Kafka topic中ds = df \
.selectExpr("CAST(key AS STRING)", "CAST(value AS STRING)") \
.writeStream \
.format("kafka") \
.option("kafka.bootstrap.servers", "host1:port1,host2:port2") \
.option("topic", "topic1") \
.start()
# 使用数据中指定的主题将key-value数据从DataFrame写入Kafkads = df \
.selectExpr("topic", "CAST(key AS STRING)", "CAST(value AS STRING)") \
.writeStream \
.format("kafka") \
.option("kafka.bootstrap.servers", "host1:port1,host2:port2") \
.start()批处理
# 从DataFrame中写入key-value数据到一个选项中指定的特定Kafka topic中df.selectExpr("CAST(key AS STRING)", "CAST(value AS STRING)") \
.write \
.format("kafka") \
.option("kafka.bootstrap.servers", "host1:port1,host2:port2") \
.option("topic", "topic1") \
.save()
# 使用数据中指定的主题将key-value数据从DataFrame写入Kafkadf.selectExpr("topic", "CAST(key AS STRING)", "CAST(value AS STRING)") \
.write \
.format("kafka") \
.option("kafka.bootstrap.servers", "host1:port1,host2:port2") \
.save()3.物联网设备数据分析
需求说明
在物联网时代,大量的感知器每天都在收集并产生着涉及各个领域的数据。物联网提供源源不断的数据流,使实时数据分析成为分析数据的理想工具。

模拟一个智能物联网系统的数据统计分析,产生设备数据发送到Kafka,结构化流Structured Streaming实时消费统计。对物联网设备状态信号数据,实时统计分析:
1)、信号强度大于30的设备;
2)、各种设备类型的数量;
3)、各种设备类型的平均信号强度;
求: 各种信号强度>30的设备的各个类型的数量和平均信号强度,先过滤再聚合
准备工作
编写程序模拟生成物联网设备监控数据,发送到Kafka Topic中,此处为了演示字段较少,实际生产项目中字段很多。
创建Topic
启动 kafka Broker服务, 创建Topic【search-log-topic】, 命令如下所示:
Kafka相关常用使用脚本:
#查看topic信息
/export/server/kafka/bin/kafka-topics.sh --list --zookeeper node1:2181
#删除topic
/export/server/kafka/bin/kafka-topics.sh --delete --zookeeper node1:2181 --topic search-log-topic
#创建topic
/export/server/kafka/bin/kafka-topics.sh --create --zookeeper node1:2181 --replication-factor 1 --partitions 3 --topic search-log-topic
#模拟生产者
/export/server/kafka/bin/kafka-console-producer.sh --broker-list node1:9092 --topic search-log-topic
#模拟消费者
/export/server/kafka/bin/kafka-console-consumer.sh --bootstrap-server node1:9092 --topic search-log-topic --from-beginning模拟数据
模拟设备监控日志数据, 字段信息封装
importjson
importrandom
importsys
importtime
importos
fromkafka importKafkaProducer
fromkafka.errors importKafkaError
# 锁定远端操作环境, 避免存在多个版本环境的问题os.environ['SPARK_HOME'] = '/export/server/spark'os.environ["PYSPARK_PYTHON"] = "/root/anaconda3/bin/python"os.environ["PYSPARK_DRIVER_PYTHON"] = "/root/anaconda3/bin/python"# 快捷键: main 回车if__name__ == '__main__':
print("模拟物联网数据")
# 1- 构建一个kafka的生产者:producer = KafkaProducer(
bootstrap_servers=['node1:9092', 'node2:9092', 'node3:9092'],
acks='all',
value_serializer=lambdam: json.dumps(m).encode("utf-8")
)
# 2- 物联网设备类型deviceTypes = ["洗衣机", "油烟机", "空调", "窗帘", "灯", "窗户", "煤气报警器", "水表", "燃气表"]
whileTrue:
index = random.choice(range(0, len(deviceTypes)))
deviceID = f'device_{index}_{random.randrange(1, 20)}'deviceType = deviceTypes[index]
deviceSignal = random.choice(range(10, 100))
# 组装数据集print({'deviceID': deviceID, 'deviceType': deviceType, 'deviceSignal': deviceSignal,
'time': time.strftime('%s')})
# 发送数据producer.send(topic='search-log-topic',
value={'deviceID': deviceID, 'deviceType': deviceType, 'deviceSignal': deviceSignal,
'time': time.strftime('%s')}
)
# 间隔时间 5s内随机time.sleep(random.choice(range(1, 5)))相当于各大物联网设置, 不断向服务器汇报监控信息, 目前采集其连接信号强弱信息, 数据样本:
{'deviceID': 'device_4_14', 'deviceType': '灯', 'deviceSignal': 49, 'time': '1646383001'}
{'deviceID': 'device_2_14', 'deviceType': '空调', 'deviceSignal': 83, 'time': '1646383005'}
{'deviceID': 'device_5_1', 'deviceType': '窗户', 'deviceSignal': 83, 'time': '1646383007'}
{'deviceID': 'device_6_9', 'deviceType': '煤气报警器', 'deviceSignal': 66, 'time': '1646383011'}
{'deviceID': 'device_4_19', 'deviceType': '灯', 'deviceSignal': 58, 'time': '1646383013'}
{'deviceID': 'device_4_10', 'deviceType': '灯', 'deviceSignal': 20, 'time': '1646383016'}
{'deviceID': 'device_7_9', 'deviceType': '水表', 'deviceSignal': 83, 'time': '1646383017'}代码实现: SQL 风格
开发步骤:
从Kafka消费日志数据,
提取字段信息,
将DataFrame注册为临时视图,其中使用函数get_json_object提取JSON字符串中字段值,
编写SQL执行分析,
将最终结果打印控制台
代码实现- SQL 风格
frompyspark importSparkContext, SparkConf
frompyspark.sql importSparkSession
importpyspark.sql.functions asF
importos
# 锁定远端操作环境, 避免存在多个版本环境的问题os.environ['SPARK_HOME'] = '/export/server/spark'os.environ["PYSPARK_PYTHON"] = "/root/anaconda3/bin/python"os.environ["PYSPARK_DRIVER_PYTHON"] = "/root/anaconda3/bin/python"# 快捷键: main 回车if__name__ == '__main__':
print("基于SQL方案, 完成分析操作")
# 1- 创建SparkSession对象spark = SparkSession.builder\
.master('local[*]')\
.appName('IOT_SQL')\
.config('spark.sql.shuffle.partitions','3')\
.getOrCreate()
# 2- 从kakfa读取数据:df = spark.readStream\
.format('kafka')\
.option('kafka.bootstrap.servers','node1:9092,node2:9092,node3:9092')\
.option('subscribe','search-log-topic') \
.option('maxOffsetsPerTrigger', '100000')\
.load()
# 3- 处理数据# 3.1: 将DF注册为一个表:df.createTempView('kakfa_data')
# 3.2 提取数据spark.sql("""
select
deviceID,
deviceType,
deviceSignal,
`time`
from kakfa_data lateral view json_tuple(cast(value as string),'deviceID','deviceType','deviceSignal','time') t1 as deviceID,deviceType,deviceSignal,`time`
""").createTempView('kafka_iot')
#3.3 分析数据:df = spark.sql("""
select
deviceType,
count(*) counts,
avg(deviceSignal) avg_signal
from kafka_iot
where deviceSignal > 30
group by deviceType
""")
df.writeStream.format('console') \
.outputMode('complete') \
.option("truncate", False) \
.start() \
.awaitTermination()代码实现: DSL风格
importjson
importrandom
importsys
importtime
importos
fromkafka importKafkaProducer
fromkafka.errors importKafkaError
# 锁定远端操作环境, 避免存在多个版本环境的问题os.environ['SPARK_HOME'] = '/export/server/spark'os.environ["PYSPARK_PYTHON"] = "/root/anaconda3/bin/python"os.environ["PYSPARK_DRIVER_PYTHON"] = "/root/anaconda3/bin/python"# 快捷键: main 回车if__name__ == '__main__':
print("模拟物联网数据")
# 1- 构建一个kafka的生产者:producer = KafkaProducer(
bootstrap_servers=['node1:9092', 'node2:9092', 'node3:9092'],
acks='all',
value_serializer=lambdam: json.dumps(m).encode("utf-8")
)
# 2- 物联网设备类型deviceTypes = ["洗衣机", "油烟机", "空调", "窗帘", "灯", "窗户", "煤气报警器", "水表", "燃气表"]
whileTrue:
index = random.choice(range(0, len(deviceTypes)))
deviceID = f'device_{index}_{random.randrange(1, 20)}'deviceType = deviceTypes[index]
deviceSignal = random.choice(range(10, 100))
# 组装数据集print({'deviceID': deviceID, 'deviceType': deviceType, 'deviceSignal': deviceSignal,
'time': time.strftime('%s')})
# 发送数据producer.send(topic='search-log-topic',
value={'deviceID': deviceID, 'deviceType': deviceType, 'deviceSignal': deviceSignal,
'time': time.strftime('%s')}
)
# 间隔时间 5s内随机time.sleep(random.choice(range(1, 5)))