HTTP协议中的响应码和实体数据
目录
HTTP世界中的名词术语
OSI七层模型
TCP的三次握手和四次挥手
HTTP报文
HTTP/1.1中规定的八种方法
HTTP的安全与幂等
HTTP的特点
HTTP的优缺点
HTTP的响应状态码
【响应码2xx】
【响应码3xx】
【响应码4xx】
【响应码5xx】
HTTP的实体数据
HTTP传输大文件的方法
HTTP世界中的名词术语
- HTTP 就是超文本传输协议,也就是HyperText Transfer Protocol。
- CDN,全称是“Content Delivery Network”,翻译过来就是“内容分发网络”。它应用了 HTTP 协议里的缓存和代理技术,代替源站响应客户端的请求。
- URI(Uniform Resource Identifier),中文名称是 统一资源标识符,使用它就能够唯一地标记互联网上资源。URI 另一个更常用的表现形式是 URL(Uniform Resource Locator), 统一资源定位符,也就是我们俗称的“网址”,它实际上是 URI 的一个子集,不过因为这两者几乎是相同的,差异不大,所以通常不会做严格的区分。
- HTTPS 相当于“HTTP+SSL/TLS+TCP/IP”,为 HTTP 套了一个安全的外壳;
- 代理是 HTTP 传输过程中的“中转站”,可以实现缓存加速、负载均衡等功能。
- TCP 是一个有状态的协议,需要先与对方建立连接然后才能发送数据,而且保证数据不丢失不重复。而 UDP 则比较简单,它无状态,不用事先建立连接就可以任意发送数据,但不保证数据一定会发到对方。
- 应用层:有各种面向具体应用的协议。例如 Telnet、SSH、FTP、SMTP、HTTP。
- DNS 就像是我们现实世界里的电话本、查号台,统管着互联网世界里的所有网站,是一个“超级大管家”;DNS 是一个树状的分布式查询系统,但为了提高查询效率,外围有多级的缓存;使用 DNS 可以实现基于域名的负载均衡,既可以在内网,也可以在外网。
如何理解TCP和UDP:TCP 是面向连接的、可靠的、只支持点对点通信;UDP 是无连接的、不可靠的、支持一对一、一对多、多对一、多对多的通信模式。TCP就像是两个人打电话,UDP就像是马路上的广播。
如何理解WebSocket:是一种基于 TCP 的轻量级网络通信协议,在地位上是与 HTTP“平级”的。HTTP 难以应用在动态页面、即时消息、网络游戏等要求“实时通信”的领域;WebSocket 客户端和服务器都可以随时向对方发送数据。
OSI七层模型
(2)数据链路层:建立逻辑连接、进行硬件地址寻址、差错校验等功能;
(3)网络层:进行逻辑地址寻址,实现不同网络之间的路径选择,协议有:IP。
(4)传输层:定义传输数据的协议端口号,以及流控和差错校验。协议有:TCP和UDP,数据包一旦离开网卡即进入网络传输层。
(5)会话层:建立、管理、终止会话。
(6)表示层:数据的表示、安全、压缩。
(7)应用层:网络服务与最终用户的一个接口。协议有:HTTP、FTP、TFTP、SMTP、SNMP、DNS、TELNET、HTTPS、POP3、DHCP。
常见网络协议含义及端口:
FTP:文件传输协议,默认端口21
Telnet:用于远程登录,端口23
SMTP:简单邮件传输协议,端口25.
POP3:用于接收邮件,端口110
HTTP:超文本传输协议,端口80
HTTPS:端口443
DNS:用于域名解析服务,端口53
【问题】在浏览器输入一个网址,再按下回车,后面究竟发生了什么?1. 根据浏览器输入的域名从本地hosts找IP,如果没有,则去DNS解析IP和端口号;2. 浏览器用 TCP 的三次握手与服务器建立连接;3. 浏览器向服务器发送拼好的报文;4. 服务器收到报文后处理请求,同样拼好报文再发给浏览器;5. 浏览器解析报文,渲染输出页面。
TCP的三次握手和四次挥手
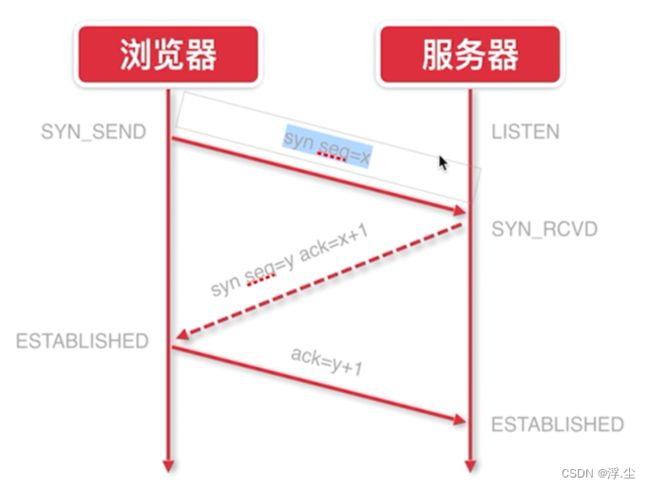
- 第一次握手:建立连接时,客户端发送syn包(syn=j)到服务器,并进入SYN_SEND状态,等待服务器确认;SYN:同步序列编号(Synchronize Sequence Numbers)
- 第二次握手:服务器收到syn包,必须确认客户的SYN(ack=j+1),同时自己也发送一个SYN包(syn=k),即SYN+ACK包,此时服务器进入SYN_RECV状态;
- 第三次握手:客户端收到服务器的SYN+ACK包,向服务器发送确认包ACK(ack=k+1),此包发送完毕,客户端和服务器进入ESTABLISHED状态,完成三次握手.
第一次:A给B发送信息,想验证自己的网络是否正常;
第二次:B收到信息,知道此时A网络正常,但是A不知道,因此B给A回复了一条信息;
第三次:A收到B的回信,知道了自己网络正常,但是此时B还不知道自己的网络是否正常。因此A又给B回复了一条信息,B收到后知道了自己的网络也是正常的。
TCP的四次挥手:
1. 第一次挥手:主动关闭方发送 fin 包到被动关闭方,告诉被动关闭方不会再发送数据了;
2. 第二次挥手:被动关闭方收到 syn 包,发送 ack 给对方,确认序号为收到序号+1;
3. 第三次挥手:被动关闭方也也发送 fin 包给主动关闭方,告诉对方我也不会给你发 送数据了;
4. 第四次挥手:主动关闭方收到 syn 包,发送 ack 给对方,至此,完成四次挥手;
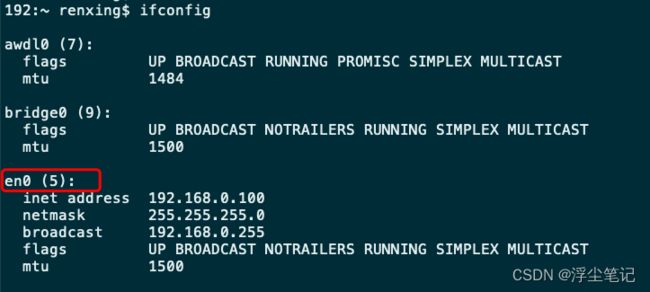
使用 ifconfig 命令查看当前默认网卡名称,一般是 eth0,我本机是 en0
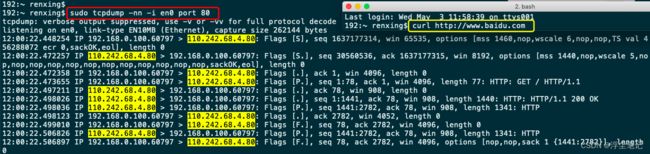
然后使用下面的命令抓包查看TCP的三次握手和四次挥手:
# 如果你的默认网卡名称是eth0,就把下面的en0改为eth0
sudo tcpdump -nn -i en0 port 80下面演示对百度网站的抓包测试:
HTTP报文
-
HTTP 报文可以没有 body,但必须要有 header,而且 header 后也必须要有空行;
-
请求头由“请求行 + 头部字段”构成,响应头由“状态行 + 头部字段”构成;
-
请求行有三部分:请求方法,请求目标和版本号;
-
状态行也有三部分:版本号,状态码和原因字符串;
-
头部字段是 key-value 的形式,用“:”分隔,不区分大小写,顺序任意,除了规定的标准头,也可以任意添加自定义字段,实现功能扩展;
-
HTTP/1.1 里唯一要求必须提供的头字段是 Host,它必须出现在请求头里,标记虚拟主机名。
-
User-Agent是请求字段,只出现在请求头里。它使用一个字符串来描述发起 HTTP 请求的客户端,服务器可以依据它来返回最合适此浏览器显示的页面。
-
Date字段是一个通用字段,但通常出现在响应头里,表示 HTTP 报文创建的时间,客户端可以使用这个时间再搭配其他字段决定缓存策略。
-
Server字段是响应字段,只能出现在响应头里。它告诉客户端当前正在提供 Web 服务的软件名称和版本号。为了安全, 有的网站响应头里要么没有这个字段,要么就给出一个完全无关的描述信息。
HTTP/1.1中规定的八种方法
- GET:在 URI 后使用“#”,就可以在获取页面后直接定位到某个标签所在的位置;使用 If-Modified-Since 字段就变成了“有条件的请求”,仅当资源被修改时才会执行获取动作;使用 Range 字段就是“范围请求”,只获取资源的一部分数据。
- HEAD 方法可以看做是 GET 方法的一个“简化版”或者“轻量版”。因为它的响应头与 GET 完全相同,所以可以用在很多并不真正需要资源的场合,避免传输 body 数据的浪费。比如,想要检查一个文件是否存在,只要发个 HEAD 请求就可以了,没有必要用 GET 把整个文件都取下来。再比如,要检查文件是否有最新版本,同样也应该用 HEAD,服务器会在响应头里把文件的修改时间传回来。
- 通常 POST 表示的是“新建”“create”的含义,而 PUT 则是“修改”“update”的含义。在实际应用中,PUT 用到的比较少。
HTTP的安全与幂等
HTTP的特点
1、HTTP 协议是一个“灵活可扩展”的传输协议。HTTP 协议逐渐增加了请求方法、版本号、状态码、头字段等特性。而 body 也不再限于文本形式的 TXT 或 HTML,而是能够传输图片、音频视频等任意数据,这些都是源于它的“灵活可扩展”的特点。HTTP 协议里的请求方法、URI、状态码、原因短语、头字段等每一个核心组成要素都没有被“写死”,允许开发者任意定制、扩充或解释,给予了浏览器和服务器最大程度的信任和自由。
2、HTTP 协议是一个“可靠”的传输协议。因为 HTTP 协议是基于 TCP/IP 的,而 TCP 本身是一个“可靠”的传输协议,所以 HTTP 自然也就继承了这个特性,能够在请求方和应答方之间“可靠”地传输数据。但是HTTP 并不能 100% 保证数据一定能够发送到另一端,在网络繁忙、连接质量差等恶劣的环境下,也有可能收发失败。“可靠”只是向使用者提供了一个“承诺”,会在下层用多种手段“尽量”保证数据的完整送达。
3、HTTP 协议是一个应用层的协议。其他的许多应用层协议都局限在很少的应用场景。例如 FTP 只能传输文件、SMTP 只能发送邮件、SSH 只能远程登录等。HTTP可携带任意头字段和实体数据的报文结构,以及连接控制、缓存代理等方便易用的特性。
4、HTTP 协议使用的是请求 -- 应答通信模式。这个请求 - 应答模式是 HTTP 协议最根本的通信模型,通俗来讲就是“一发一收”“有来有去”。永远是请求方先发起连接和请求,是主动的,而应答方只有在收到请求后才能答复,是被动的,如果没有请求时不会有任何动作。此外,请求 - 应答模式也完全符合 RPC(Remote Procedure Call)的工作模式,可以把 HTTP 请求处理封装成远程函数调用,导致了 WebService、RESTful 和 gPRC 等的出现。
5、HTTP 协议是无状态的。TCP 协议是有状态的,一开始处于 CLOSED 状态,连接成功后是 ESTABLISHED 状态,断开连接后是 FIN-WAIT 状态,最后又是 CLOSED 状态。对比一下 UDP 协议,是无连接也无状态的,顺序发包乱序收包,数据包发出去后就不管了,收到后也不会顺序整理。而 HTTP 是有连接无状态,顺序发包顺序收包,按照收发的顺序管理报文。
HTTP的优缺点
1. 简单、灵活和易于扩展;
2. 拥有成熟的软硬件环境,应用的非常广泛,是互联网的基础设施;
3. 无状态的,可以轻松实现集群化,扩展性能,但有时也需要用 Cookie 技术来实现“有状态”;
4. 明文传输,数据完全肉眼可见,能够方便地研究分析,但也容易被窃听;
5. 不安全的,无法验证通信双方的身份,也不能判断报文是否被窜改;
HTTP的响应状态码
1××:提示信息,表示目前是协议处理的中间状态,还需要后续的操作(实际很少用);2××:成功,报文已经收到并被正确处理;3××:重定向,资源位置发生变动,需要客户端重新发送请求;4××:客户端错误,请求报文有误,服务器无法处理;5××:服务器错误,服务器在处理请求时内部发生了错误。
【响应码2xx】
-
200 OK ,表示一切正常,如果是非 HEAD 请求,通常在响应头后都会有 body 数据。
-
204 No Content ,含义与“200 OK”基本相同,但响应头后没有 body 数据。
-
206 Partial Content ,是 HTTP 分块下载或断点续传的基础,在客户端发送“范围请求”、要求获取资源的部分数据时出现,它与 200 一样,也是服务器成功处理了请求,但 body 里的数据不是资源的全部,而是其中的一部分。 状态码 206 通常还会伴随着头字段“Content-Range”,表示响应报文里 body 数据的具体范围,供客户端确认,例如“Content-Range: bytes 0-99/2000”,意思是此次获取的是总计 2000 个字节的前 100 个字节。
【响应码3xx】
-
301 Moved Permanently :永久重定向,此次请求的资源已经不存在了,需要改用改用新的 URI 再次访问。
-
302 Found :临时重定向,意思是请求的资源还在,但需要暂时用另一个 URI 来访问。
301 和 302 都会在响应头里使用字段Location指明后续要跳转的 URI,浏览器都会重定向到新的 URI。301重定向类似于“搬家了,原来的地方不住了”,302类似于“临时出去玩几天,还会回来”。比如,你的网站升级到了 HTTPS,原来的 HTTP 不打算用了,这就是“永久”的,所以要配置 301 跳转,把所有的 HTTP 流量都切换到 HTTPS。再比如,今天夜里网站后台要系统维护,服务暂时不可用,这就属于“临时”的,可以配置成 302 跳转,把流量临时切换到一个静态通知页面,浏览器看到这个 302 就知道这只是暂时的情况,不会做缓存优化,第二天还会访问原来的地址。
-
304 Not Modified 用于 If-Modified-Since 等条件请求,表示资源未修改,用于缓存控制。它不具有通常的跳转含义,但可以理解成“重定向已到缓存的文件”(即“缓存重定向”)。
【响应码4xx】
-
400 Bad Request :表示请求报文有错误,但具体是数据格式错误、缺少请求头还是 URI 超长它没有明确说,只是一个笼统的错误,客户端看到 400 只会是“一头雾水”,所以,在开发 Web 应用时应当尽量避免给客户端返回 400,而是要用其他更有明确含义的状态码。
-
403 Forbidden :实际上不是客户端的请求出错,而是表示服务器禁止访问资源。原因可能多种多样,例如信息敏感、法律禁止等,如果服务器友好一点,可以在 body 里详细说明拒绝请求的原因。
-
404 Not Found :资源在本服务器上未找到。
-
405 Method Not Allowed:不允许使用某些方法操作资源,例如不允许 POST 只能 GET;
-
406 Not Acceptable:资源无法满足客户端请求的条件,例如请求中文但只有英文;
-
408 Request Timeout:请求超时,服务器等待了过长的时间;
-
409 Conflict:多个请求发生了冲突,可以理解为多线程并发时的竞态;
-
413 Request Entity Too Large:请求报文里的 body 太大;
-
414 Request-URI Too Long:请求行里的 URI 太大;
-
429 Too Many Requests:客户端发送了太多的请求,通常是由于服务器的限连策略;
-
431 Request Header Fields Too Large:请求头某个字段或总体太大;
【响应码5xx】
-
500 Internal Server Error :与 400 类似,也是一个通用的错误码,服务器究竟发生了什么错误我们是不知道的。不过对于服务器来说这应该算是好事,通常不应该把服务器内部的详细信息,例如出错的函数调用栈告诉外界。虽然不利于调试,但能够防止黑客的窥探或者分析。
-
501 Not Implemented :表示客户端请求的功能还不支持,这个错误码比 500 要“温和”一些,和“即将开业,敬请期待”的意思差不多,不过具体什么时候“开业”就不好说了。
-
502 Bad Gateway :通常是服务器作为网关或者代理时返回的错误码,表示服务器自身工作正常,访问后端服务器时发生了错误,但具体的错误原因也是不知道的。
-
503 Service Unavailable :表示服务器当前很忙,暂时无法响应服务,我们上网时有时候遇到的“网络服务正忙,请稍后重试”的提示信息就是状态码 503。 503 是一个“临时”的状态,很可能过几秒钟后服务器就不那么忙了,可以继续提供服务,所以 503 响应报文里通常还会有一个“Retry-After”字段,指示客户端可以在多久以后再次尝试发送请求。
-
504 Gateway Timeout:代理服务器请求真实服务器的时候,真实服务器没有及时将相应返回给代理服务器,此时代理服务器会返回504表示响应超时。
HTTP的实体数据
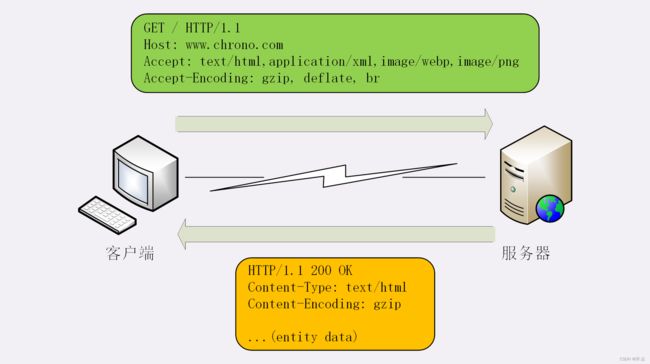
客户端用 Accept 头告诉服务器希望接收什么样的数据,而服务器用 Content 头告诉客户端实际发送了什么样的数据。
HTTP可以发送的数据类型:
- text:文本格式的可读数据,比如:text/html ,text/plain(纯文本)、text/css(样式表)。
- image:图像文件,有 image/gif、image/jpeg、image/png 等。
- audio/video:音频和视频数据,例如 audio/mpeg、video/mp4 等。
- application:数据格式不固定,可能是文本也可能是二进制,必须由上层应用程序来解释。常见的有application/json,application/javascript、application/pdf、application/octet-stream(不透明的二进制数据)。
HTTP协议常见的请求头、响应头、请求方法:
Content-Type:请求的与实体对应的IMME信息
Accept:指定客户端能接受的内容类型
Origin:最初的请求的来源,主要用于POST请求
Cookie:HTTP发送给服务端的cookie值
Cache-Control:指定请求和响应的缓存机制
User-Agent:用户信息
Referrer:上级请求路径
X-Forwarded-For:请求端的真实IP
Access-Control-Allow-Origin:允许特定的域名访问,跨域使用
Last-Modified:请求资源的最后响应时间
HTTP的实体数据:
Accept-Encoding:字段标记的是客户端支持的压缩格式,可以用“,”列出多个。常用的有:gzip和deflate。
Content-Encoding:服务器实际使用的压缩格式。
如果请求报文里没有 Accept-Encoding 字段,就表示客户端不支持压缩数据;如果响应报文里没有 Content-Encoding 字段,就表示响应数据没有被压缩。
1. gzip:GNU zip 压缩格式,也是互联网上最流行的压缩格式;
2. deflate:zlib(deflate)压缩格式,流行程度仅次于 gzip;
3. br:一种专门为 HTTP 优化的新压缩算法(Brotli)。
Accept-Language: 客户端可理解的自然语言,比如 zh-CN, zh, en
Content-Language: 服务器告诉客户端实体数据使用的实际语言类型,比如 zh-CN
Accept-Charset:字符集,但响应头里是在Content-Type字段的数据类型后面用“charset=xxx”来表示:
客户端:Accept-Charset: gbk, utf-8
服务端:Content-Type: text/html; charset=utf-8
细节:在 HTTP 协议里用 Accept、Accept-Encoding、Accept-Language 等请求头字段进行内容协商的时候,还可以用一种特殊的“q”参数表示权重来设定优先级,这里的“q”是“quality factor”的意思。权重的最大值是 1,最小值是 0.01,默认值是 1,如果值是 0 就表示拒绝。具体的形式是在数据类型或语言代码后面加一个“;”,然后是“q=value”。
Accept: text/html,application/xml;q=0.9,*/*;q=0.8
表示浏览器最希望使用的是 HTML 文件,权重是 1,其次是 XML 文件,权重是 0.9,最后是任意数据类型,权重是 0.8。
服务器收到请求头后,就会计算权重,再根据自己的实际情况优先输出 HTML 或者 XML。
HTTP传输大文件的方法
1、数据压缩:把大文件整体变小。客户端指定Accept-Encoding,服务端把原数据压缩后返回,指明使用的Content-Encoding压缩格式。
gzip 等压缩算法通常只对文本文件有较好的压缩率,而图片、音频视频等多媒体数据本身就已经是高度压缩的,再用 gzip 处理也不会变小(甚至还有可能会增大一点),所以它就失效了。不过数据压缩在处理文本的时候效果还是很好的,所以各大网站的服务器都会使用这个手段作为“保底”。例如,在 Nginx 里就会使用“gzip on”指令,启用对“text/html”的压缩。
2、分块传输,化整为零:分批发给浏览器,浏览器收到后再组装复原。
在响应报文里用头字段“Transfer-Encoding: chunked”来表示,意思是报文里的 body 部分不是一次性发过来的,而是分成了许多的块(chunk)逐个发送。
“Transfer-Encoding: chunked”和“Content-Length”这两个字段是互斥的,也就是说响应报文里这两个字段不能同时出现,一个响应报文的传输要么是长度已知,要么是长度未知(chunked)。
分块传输的编码规则:
1. 每个分块包含两个部分,长度头和数据块;
2. 长度头是以 CRLF(回车换行,即\r\n)结尾的一行明文,用 16 进制数字表示长度;
3. 数据块紧跟在长度头后,最后也用 CRLF 结尾,但数据不包含 CRLF;
4. 最后用一个长度为 0 的块表示结束,即“0\r\n\r\n”。
3、范围请求:允许客户端在请求头里使用专用字段来表示只获取文件的一部分,相当于是客户端的“化整为零”。比如:播放视频的快进和快退;多段下载;断点续传。主要步骤是:
(1)先发个 HEAD,看服务器是否支持范围请求,同时获取文件的大小;
(2)开 N 个线程,每个线程使用 Range 字段划分出各自负责下载的片段,发请求传输数据;
(3)下载意外中断也不怕,不必重头再来一遍,只要根据上次的下载记录,用 Range 请求剩下的那一部分就可以了。
范围请求不是 Web 服务器必备的功能,可以实现也可以不实现;所以服务器必须在响应头里使用字段“Accept-Ranges: bytes”明确告知客户端:“我是支持范围请求的”。
第一,服务端必须检查范围是否合法,比如文件只有 100 个字节,但请求“200-300”,这就是范围越界了。服务器就会返回状态码416,意思是“你的范围请求有误,我无法处理,请再检查一下”。
第二,如果范围正确,服务器就可以根据 Range 头计算偏移量,读取文件的片段了,返回状态码“206 Partial Content”,和 200 的意思差不多,但表示 body 只是原数据的一部分。
第三,服务器要添加一个响应头字段Content-Range,告诉片段的实际偏移量和资源的总大小,格式是“bytes x-y/length”,与 Range 头区别在没有“=”,范围后多了总长度。例如,对于“0-10”的范围请求,值就是“bytes 0-10/100”。
4、多段数据。刚才说的范围请求一次只获取一个片段,其实它还支持在 Range 头里使用多个“x-y”,一次性获取多个片段数据。这种情况需要使用一种特殊的 MIME 类型:“multipart/byteranges”,表示报文的 body 是由多段字节序列组成的,并且还要用一个参数“boundary=xxx”给出段之间的分隔标记。