注意力机制——Multi-Head Attention(MHA)
Multi-Head Attention(MHA):MHA是一种多头注意力模型,将注意力机制扩展到多个头,从而增强模型对于不同特征的关注度。
MHA 的输入包括三个向量:查询向量(query)、键向量(key)和值向量(value)。对于一个给定的查询向量,MHA 会对键向量进行加权求和,权重由查询向量和键向量之间的相似度计算得到,然后将得到的加权和乘以值向量进行输出。在计算相似度时,常用的方法是使用点积(dot product)或者是双线性(bilinear)计算。
MHA 的多头机制可以有效提高模型的表达能力,同时也可以使模型学习到更加多样化和复杂的特征。在多头机制下,输入的序列数据会被分成多个头,每个头进行独立的计算,得到不同的输出。这些输出最后被拼接在一起,形成最终的输出。
MHA 的计算可以表示为以下的公式:
![]() 其中 Q, K, V 分别表示查询向量、键向量和值向量,ℎ 表示头的数量,headi 表示第 i 个头的输出,WO 是输出变换矩阵。每个头的输出 headi 可以表示为:
其中 Q, K, V 分别表示查询向量、键向量和值向量,ℎ 表示头的数量,headi 表示第 i 个头的输出,WO 是输出变换矩阵。每个头的输出 headi 可以表示为:

其中 WiQ, WiK, WiV 分别是第 i 个头的查询、键、值变换矩阵,AttentionAttention 是注意力计算函数。在 MHA 中,一般使用自注意力机制(Self-Attention)来计算注意力。
自注意力机制的计算可以表示为以下的公式:
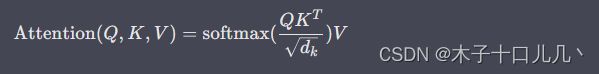
其中 dk 是键向量的维度,softmax相似度进行归一化,将每个键向量的权重计算出来,然后将权重乘以值向量,最后进行加权求和得到注意力输出。
MHA 的流程可以总结为以下几步:
- 将输入的序列数据分成多个头;
- 对每个头进行独立的查询、键、值线性变换;
- 对每个头进行自注意力计算,得到该头的输出;
- 将所有头的输出拼接在一起,并进行输出线性变换。
MultiHeadAttention模块pytorch实现:
import torch
import torch.nn as nn
import torch.nn.functional as F
class MultiHeadAttention(nn.Module):
def __init__(self, d_model, num_heads, dropout=0.1):
super().__init__()
# 初始化模块的属性
self.num_heads = num_heads # 多头注意力头数
self.d_model = d_model # 模型维度
self.depth = d_model // num_heads # 每个头的维度
# 定义权重矩阵
self.Wq = nn.Linear(d_model, d_model)
self.Wk = nn.Linear(d_model, d_model)
self.Wv = nn.Linear(d_model, d_model)
# 定义最终的线性层
self.fc = nn.Linear(d_model, d_model)
# 定义dropout层
self.dropout = nn.Dropout(p=dropout)
def scaled_dot_product_attention(self, Q, K, V, mask=None):
# 计算注意力得分
scores = torch.matmul(Q, K.transpose(-1, -2)) / torch.sqrt(torch.tensor(self.depth, dtype=torch.float32))
# 如果存在掩码,应用掩码
if mask is not None:
scores += mask * -1e9
# 计算softmax
attention = F.softmax(scores, dim=-1)
# 应用dropout
attention = self.dropout(attention)
# 将注意力得分乘以value向量
output = torch.matmul(attention, V)
return output, attention
def forward(self, Q, K, V, mask=None):
batch_size = Q.size(0)
# 线性投影
Q = self.Wq(Q).view(batch_size, -1, self.num_heads, self.depth).transpose(1, 2)
K = self.Wk(K).view(batch_size, -1, self.num_heads, self.depth).transpose(1, 2)
V = self.Wv(V).view(batch_size, -1, self.num_heads, self.depth).transpose(1, 2)
# Scaled Dot-Product Attention
scores, attention = self.scaled_dot_product_attention(Q, K, V, mask)
concat = scores.transpose(1, 2).contiguous().view(batch_size, -1, self.d_model)
# 最终的线性投影
output = self.fc(concat)
return output, attention在这个实现中,我们首先定义了一个MultiHeadAttention类,它继承了nn.Module,并包含以下属性:
num_heads:多头注意力中头的数量。d_model:输入向量的维度。depth:每个头的向量维度,即dmodel/num_heads。Wq、Wk、Wv:输入的Q、K、V向量分别通过这些线性层进行转换。fc:输出向量通过这个线性层进行转换。
scaled_dot_product_attention 函数是 MultiHeadAttention 模块中的一个重要方法,实现了Scaled Dot-Product Attention操作。
该函数的输入参数 Q,K 和 V 分别表示查询向量、键向量和值向量,均为张量。其中,Q 和 K 的 shape 为 (batch_size, num_heads, seq_len, depth),而 V 的 shape 为 (batch_size, num_heads, seq_len, depth),其中 seq_len 代表序列长度,depth 代表每个头的维度。
将 MultiHeadAttention 模块添加到 PyTorch 模型示例:
import torch.nn as nn
class MyModel(nn.Module):
def __init__(self):
super(MyModel, self).__init__()
# 定义一个 MultiHeadAttention 模块
self.attn = nn.MultiheadAttention(embed_dim=512, num_heads=8)
# 其他模型层的定义
self.linear1 = nn.Linear(512, 256)
self.relu = nn.ReLU()
self.linear2 = nn.Linear(256, 10)
def forward(self, x):
# 输入 x 的 shape 为 (batch_size, seq_len, input_dim)
# 将输入张量转换为 (seq_len, batch_size, input_dim) 的形式
x = x.permute(1, 0, 2)
# 使用 MultiHeadAttention 模块进行注意力机制
attn_output, attn_weights = self.attn(x, x, x)
# 将输出张量转换回 (batch_size, seq_len, input_dim) 的形式
attn_output = attn_output.permute(1, 0, 2)
# 其他模型层的计算
x = self.linear1(attn_output)
x = self.relu(x)
x = self.linear2(x)
return x在上面的示例中,我们定义了一个名为 MyModel 的 PyTorch 模型,其中包含一个 MultiHeadAttention 模块。在模型的 __init__ 方法中,我们创建了一个 MultiHeadAttention 实例,并将其存储在模型中的 self.attn 属性中。在模型的 forward 方法中,我们将输入张量 x 转换为 (seq_len, batch_size, input_dim) 的形式,并使用 self.attn 对其进行注意力机制。注意力机制的输出为元组 (attn_output, attn_weights),其中 attn_output 表示注意力机制的输出张量,attn_weights 表示注意力权重。最后,我们将 attn_output 转换回 (batch_size, seq_len, input_dim) 的形式,并将其输入到其他模型层中。