3.3 Python利用Pandas进行数据文件读写

本文章是3.3的内容,如果想要源代码和数据可以看以下链接:
https://download.csdn.net/download/Ahaha_biancheng/83338868
文章目录
-
- 3.3 数据文件读写
-
- 3.3.1 读写CSV和TXT文件
-
- 3.3.1.1 读写CSV文件
- 3.3.1.2 读写TXT文件
- 3.3.1.3 保存csv文件
- 3.3.2 读取Excel文件
3.3 数据文件读写
3.3.1 读写CSV和TXT文件
3.3.1.1 读写CSV文件

例3-5 从students1.csv文件读出数据,保存为DataFrame对象
# 未定义行索引,自动生成
sdt = pd.read_csv('data/student1.csv')
# 显示最后三条数据
sdt[-3:]
| 序号 | 性别 | 年龄 | 身高 | 体重 | 省份 | 成绩 | |
|---|---|---|---|---|---|---|---|
| 2 | 3 | male | 22 | 180 | 62 | FuJian | 57 |
| 3 | 4 | male | 20 | 177 | 72 | LiaoNing | 79 |
| 4 | 5 | male | 20 | 172 | 74 | ShanDong | 91 |

# 文件中每个同学已有序号,读取时作为行索引,所以此时,序号一列为行索引
sdt = pd.read_csv('data/student1.csv', index_col=0)
sdt[3:] # 输出第三行往后
| 性别 | 年龄 | 身高 | 体重 | 省份 | 成绩 | |
|---|---|---|---|---|---|---|
| 序号 | ||||||
| 4 | male | 20 | 177 | 72 | LiaoNing | 79 |
| 5 | male | 20 | 172 | 74 | ShanDong | 91 |
sdt = pd.read_csv('data/student1.csv', index_col=0, header=None)
sdt[:] # 输出
| 1 | 2 | 3 | 4 | 5 | 6 | |
|---|---|---|---|---|---|---|
| 0 | ||||||
| 序号 | 性别 | 年龄 | 身高 | 体重 | 省份 | 成绩 |
| 1 | male | 20 | 170 | 70 | LiaoNing | 71 |
| 2 | male | 22 | 180 | 71 | GuangXi | 77 |
| 3 | male | 22 | 180 | 62 | FuJian | 57 |
| 4 | male | 20 | 177 | 72 | LiaoNing | 79 |
| 5 | male | 20 | 172 | 74 | ShanDong | 91 |
# 由于不是utf编码所以报错
# 先调整文件
utf = pd.read_csv('data/utf_student1.csv')
utf
| 序号 | 性别 | 年龄 | 身高 | 体重 | 省份 | 成绩 | |
|---|---|---|---|---|---|---|---|
| 0 | 1 | male | 20 | 170 | 70 | LiaoNing | 71 |
| 1 | 2 | male | 22 | 180 | 71 | GuangXi | 77 |
| 2 | 3 | male | 22 | 180 | 62 | FuJian | 57 |
| 3 | 4 | male | 20 | 177 | 72 | LiaoNing | 79 |
| 4 | 5 | male | 20 | 172 | 74 | ShanDong | 91 |
3.3.1.2 读写TXT文件
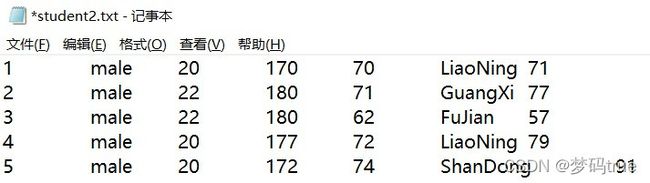
# stxt = pd.read_csv('data/student2.txt')
# stxt = pd.read_csv('data/student2.txt', sep='\t')
# stxt = pd.read_csv('data/student2.txt', sep='\t', header=None)
name = ['序号','性别','年龄','身高','体重','省份','成绩']
# stxt = pd.read_csv('data/student2.txt', sep='\t', names=name)
stxt = pd.read_csv('data/student2.txt', sep='\t', names=name, index_col=0)
stxt
| 性别 | 年龄 | 身高 | 体重 | 省份 | 成绩 | |
|---|---|---|---|---|---|---|
| 序号 | ||||||
| 1 | male | 20 | 170 | 70 | LiaoNing | 71 |
| 2 | male | 22 | 180 | 71 | GuangXi | 77 |
| 3 | male | 22 | 180 | 62 | FuJian | 57 |
| 4 | male | 20 | 177 | 72 | LiaoNing | 79 |
| 5 | male | 20 | 172 | 74 | ShanDong | 91 |
通配符
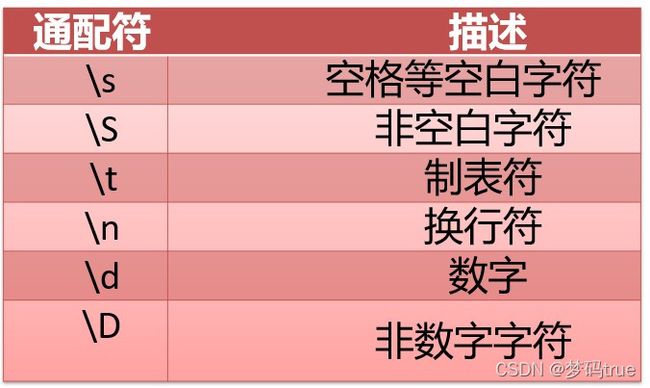
使用详情可参考:
https://www.coolcou.com/pandas/pandas-read-write/pandas-read-txt.html
stxt = pd.read_csv('data/student2.txt', sep='\d', index_col=0, header=None)
stxt
:1: ParserWarning: Falling back to the 'python' engine because the 'c' engine does not support regex separators (separators > 1 char and different from '\s+' are interpreted as regex); you can avoid this warning by specifying engine='python'.
stxt = pd.read_csv('data/student2.txt', sep='\d', index_col=0, header=None)
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | ||||||||||
| 锘� | \tmale\t | NaN | \t | NaN | NaN | \t | NaN | \tLiaoNing\t | NaN | NaN |
| NaN | \tmale\t | NaN | \t | NaN | NaN | \t | NaN | \tGuangXi\t | NaN | NaN |
| NaN | \tmale\t | NaN | \t | NaN | NaN | \t | NaN | \tFuJian\t | NaN | NaN |
| NaN | \tmale\t | NaN | \t | NaN | NaN | \t | NaN | \tLiaoNing\t | NaN | NaN |
| NaN | \tmale\t | NaN | \t | NaN | NaN | \t | NaN | \tShanDong\t | NaN | NaN |
3.3.1.3 保存csv文件

例3-7:新建DataFrame对象student,数据保存到out.csv文件
data = [[19,68,170],[20,65,165],[18,65,175]]
st = DataFrame(data, columns=['age', 'weight','height'])
print(st)
st.to_csv('out.csv',mode='w' )
age weight height
0 19 68 170
1 20 65 165
2 18 65 175
3.3.2 读取Excel文件
从Excel文件中读取数据的函数类似CSV文件,需给出数据所在的Sheet表单名
pd.read_excel(file, sheetname, ...)

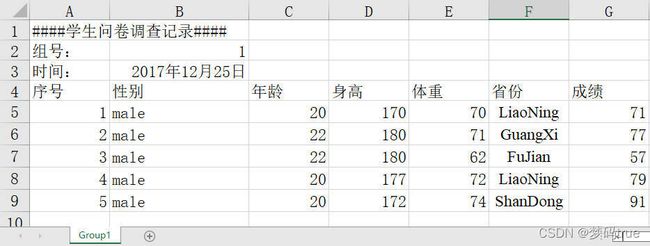
例3-8:从student3. xlsx文件名为“Group1”的页中读取数据
# 出错ImportError: Missing optional dependency 'xlrd'. Install xlrd >= 1.0.0 for
# Excel support Use pip or conda to install xlrd. 版本问题
# stexl = pd.read_excel('data/student3.xlsx')
# skiprows=3 跳过前三行
# stexl = pd.read_excel('data/student3.xlsx', 'Group1', skiprows=3, index_col=0)
stexl = pd.read_excel('data/student3.xlsx', 'Group1', skiprows=[0,1,2,3], index_col=0)
stexl
| male | 20 | 170 | 70 | LiaoNing | 71 | |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | male | 22 | 180 | 71 | GuangXi | 77 |
| 3 | male | 22 | 180 | 62 | FuJian | 57 |
| 4 | male | 20 | 177 | 72 | LiaoNing | 79 |
| 5 | male | 20 | 172 | 74 | ShanDong | 91 |