第三章-Python中的数据类型
欢迎来到python的世界
博客主页:卿云阁欢迎关注点赞收藏⭐️留言
本文由卿云阁原创!
本阶段属于练气阶段,希望各位仙友顺利完成突破
首发时间:2021年3月14日
✉️希望可以和大家一起完成进阶之路!
作者水平很有限,如果发现错误,请留言轰炸哦!万分感谢!
目录
一、数值类型
二. 序列数据类型
三,集合
四、字典

内存模型
程序在计算中运行时,数据时存放在内存中的,CPU从内存中读取数据,进行运算并把结果返回到内存中。内存条是计算机的一个物理组件,主要是用来存放程序运行的临时数据的。
内存的物理状态:
内存主要有两个性能指标,存储容量(8G)和存储速度(1066MHz)。我们在给电脑增加内存条是要注意版本和标压(或低压)。 内存是临时存储数据的,比如此时我们运行一个软件QQ,QQ代码和资源文件全部都要放到内存中。CPU再从内存中加载再运行。
内存的逻辑状态:
内存可以划分成很多的内存区域。
数值类型
1.整型
可以表示整数,复数,和0
整数可以表示成不同进制
a=123
(1)python的整数长度为16,32位,并且通常是连续分配内存空间的。从上面的空间地址看,地址之间正好差16,32。print(id(1)) print(id(2)) 结果: 1775791168 1775791200小整数对象池python初始化的时候会自动建立一个小整数对象池,方便我们调用,避免后期重复生成!这是一个包含262个指向整数对象的指针数组,范围是-5到256。也就是说比如整数10,即使我们在程序里没有创建它,其实在Python后台已经悄悄为我们创建了。为什么要这样呢?我们都知道,在程序运行时,包括Python后台自己的运行环境中,会频繁使用这一范围内的整 数,如果每需要一个,你就创建一个,那么无疑会增加很多开销。创建一个一直存在,永不销毁,随用随拿的小 整数对象池,无疑是个比较实惠的做法。print(id(-6)) print(id(-5)) print(id(255)) 结果: 2424787371344 1775790976 1775799296内存模型分析:在一个代码区(同时运行解释)
解释器本来是解释一段代码,执行一段代码;但是一个python文件通常情况下会一次性的加载到内存中(代码有一个预加载的检查过程),发现i1赋值1200,再进行i2的赋值时会检查常量区如果存在了1200的数据就直接赋值给i2(不需要重新的申请空间)
i1=1200;i2=1200
不在一个代码区解释器(交互模式下没有预加载检查)两种变量的赋值操作都是独立运行的,内存中出现了重复的数据(这和交互模式有关,交互模式通常用于少量代码的调试的,所以每次执行单行代码都会独立申请内存,防止多个代码块的数据互相的影响,造成测试结果出错)。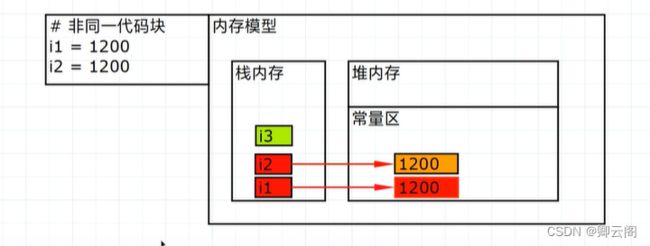 特定的整数python中对常用的整数数据提前加载到常量区。
特定的整数python中对常用的整数数据提前加载到常量区。
2.浮点型
因为计算机是采用二级制存储的。
a=1.1 b=2.2 print(a+b)3.布尔类型
bool(0) bool("abc") a=True b=False
4.复数类型
序列数据类型
序列数据类型常用的操作
(1)索引和切片操作
步长为2
a="Hellow" print(a[0:-1:2])
(2)加和乘操作
a="Hello" a+=",World" print(a) a=a*2 print(a) 结果: Hello,World Hello,WorldHello,World(3)成员测试
a="Hello" print('e'in a) 结果: True1.字符串
a="Hello"
2.序列数据
地址分布不连续
s='abcdef' print(s[0]) print(s[1:3])
字符串常⽤操作
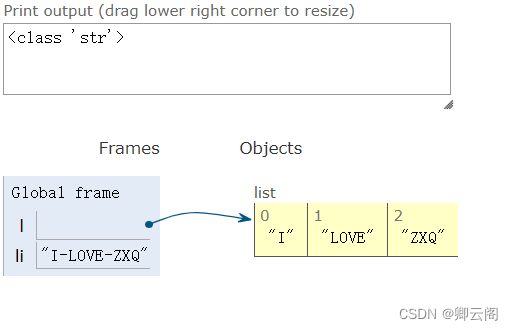
a = "I LOVE ZXQ" print(a.center(50,"-")) # output : --------------------I LOVE ZXQ--------------------- print(a.count("L",0,4)) #查找出现的次数 print(a.endswith("ZXQ")) # 判断结尾 print(a.startswith("I")) # 判断开头 print(a.find("O")) # 字符查找,返回-1代表没找到,如果找到了,就返回所查字符的索引 print(a.isdigit()) print("22".isdigit()) # 判断是否是整数 l = ["I","LOVE","ZXQ"] print("-".join(l)) # 拼接字符串 print(a.replace("I","ME" ,1)) # 字符串替换,替换一次 print(a.split(" L",1)) # 字符串分割,以L分,分割一次 #结果 --------------------I LOVE ZXQ-------------------- 1 True True 3 False True I-LOVE-ZXQ ME LOVE ZXQ ['I', 'OVE ZXQ']l = ["I","LOVE","ZXQ"] li="-".join(l)# 拼接字符串 print(type(li)) print(li)
字符串的内存分析:
字符串的赋值:
变量在我们程序里是最不稳定的存在,所以会分配给栈内存,name1和name2里存储的是Tom的内存地址。在python中认为字符串是用的最多的数据类型,所以TOM会放到常量区,当我们执行到第二句的时候,会先向常量区中找这个字符串是否存在,如果不存在就新建一个,反之name2存储Tom的内存地址。
字符串不可更改
TOM去哪里了?当我们执行到name='JERRY'的时候,计算机会先在常量区找是否有这个字符串,如果存在(不需要申请内存空间),如果不存在则需要申请空间创建一个数据,然后将新的内存地址赋给变量,通过变量找到内存地址,再通过内存的地址找到具体的数据。
结论:字符串数据不可更改,是不可变的数据,字典中的key只能是不可变得数据。
拼接
python认为如果字符串是直接通过字面量得赋值,这样得数据需要重复使用,会放到常量区中,如果是通过字符串得运算得到得数据,认为是动态变化得,不需要永久得存储,所以会放在堆内存中。
3.元组
s=(1,2,3)

地址分布是连续的
元组只保证它的一级子元素不可变,对于嵌套的元素内部,不保证不可变!tup = ('a', 'b', ['A', 'B']) tup[2][0] = 'a' tup[2][1] = 'b'
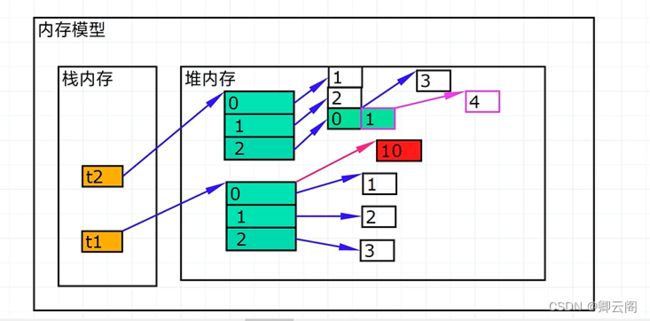
列表和元组的转换使用list函数可以把元组转换成列表使用tuple函数可以把列表转换成元组元组的内存分析:
t2=(1,2,[3,4]) t2[2].append(5)
4.列表
s=[1,2,3]

地址分布是连续的
列表是Python中最基本也是最常用的数据结构之一。列表中的每个元素都被分配一个数字作为索引,用来表示该 元素在列表内所排在的位置。第一个元素的索引是0,第二个索引是1,依此类推。 Python的列表是一个有序可重复的元素集合,可嵌套、迭代、修改、分片、追加、删除,成员判断。 从数据结构角度看,Python的列表是一个可变长度的顺序存储结构,每一个位置存放的都是对象的指针。alist = ["卿云", 19, [11,22]]
追加元素
list=[1,2,3] list.append(4) print(list) list1=[5,6,7] list.extend(list1) print(list) 结果: [1, 2, 3, 4] [1, 2, 3, 4, 5, 6, 7]删除元素
使用del语句或者remove(),pop()方法删除指定的元素。list = ["a", "b", "c"] del list[0] # 根据索引删除 print(list) list.remove("b") # 直接根据值进行删除 print(list) list.pop() # 弹出最后一个 l1 = [1, 'hello', 1] l2 = l1.pop(1) # 根据索引来弹出 1为索引 print(l2) 结果: ['b', 'c'] ['c'] hello
列表的特殊操作
l1 = [1, 2, 3] l2 = [4, 5, 6] print(l1+l2) print(l1.__add__(l2)) # 底层调用了__add__方法 print( ['Hi!'] * 4 )#列表的乘法 l1 = [1, 2, 3] print(l1.__mul__(3)) print(3 in [1, 2, 3] )#判断元素是否存在于 列表中 l1 = [1, 2, 3] print(l1.__contains__(1)) for x in [1, 2, 3]: print(x) #迭代列表中的每个元素 结果: [1, 2, 3, 4, 5, 6] [1, 2, 3, 4, 5, 6] ['Hi!', 'Hi!', 'Hi!', 'Hi!'] [1, 2, 3, 1, 2, 3, 1, 2, 3] True True 1 2 3排序和反转list=[2,1,3] list.reverse() print(list) list.sort() print(list) 结果: [3, 1, 2] [1, 2, 3]列表的内置方法
names=['zxq', 'qingyun', 'liyvhe'] for i in names: print(i) for i in enumerate(names): print(i[0],i[1]) 结果: zxq qingyun liyvhe 0 zxq 1 qingyun 2 liyvhe班级分组⼩程序现要求按考试成绩⾼低将学员们分成 5 组,全存在⼀个新的⼤列表⾥ , 5 组分别是 90-100, 80-89, 70-79,60-69, 0-59#coding:utf-8 stu_list = [['李渊', 82], ['李世民', 7], ['侯君集', 5], ['李靖', 58], ['魏征', 41], ['房玄龄', 64], ['杜如晦', 65], ['柴绍', 94], ['程知节', 45], ['尉迟恭', 94], ['秦琼', 54], ['长孙无忌', 85], ['李存恭', 98], ['封德彝', 16], ['段志玄', 44], ['刘弘基', 18], ['徐世绩', 86], ['李治', 19], ['武则天', 39], ['太平公主', 57], ['韦后', 76], ['李隆基', 95], ['杨玉环', 33], ['王勃', 49], ['陈子昂', 91], ['卢照邻', 70], ['杨炯', 81], ['王之涣', 82], ['安禄山', 18], ['史思明', 9], ['张巡', 15], ['雷万春', 72], ['李白', 61], ['高力士', 58], ['杜甫', 27], ['白居易', 5], ['王维', 14], ['孟浩然', 32], ['杜牧', 95], ['李商隐', 34], ['郭子仪', 53], ['张易之', 39], ['张昌宗', 61], ['来俊臣', 8], ['杨国忠', 84], ['李林甫', 95], ['高适', 100], ['王昌龄', 40], ['孙思邈', 46], ['玄奘', 84], ['鉴真', 90], ['高骈', 85], ['狄仁杰', 62], ['黄巢', 79], ['王仙芝', 16], ['文成公主', 13], ['松赞干布', 47], ['薛涛', 79], ['鱼玄机', 16], ['贺知章', 20], ['李泌', 17], ['韩愈', 100], ['柳宗元', 88], ['上官婉儿 五代十国:朱温', 55], ['刘仁恭', 6], ['丁会', 26], ['李克用', 39], ['李存勖', 11], ['葛从周', 25], ['王建', 13], ['刘知远', 95], ['石敬瑭', 63], ['郭威', 28], ['柴荣', 50], ['孟昶', 17], ['荆浩', 84], ['刘彟', 18], ['张及之', 45], ['杜宇', 73], ['高季兴', 39], ['喻皓', 50], ['历真', 70], ['李茂贞', 6], ['朱友珪', 7], ['朱友贞', 11], ['刘守光', 2]] stu_groups = [ [], # 90-100 [], # 80-89 [], # 70-79 [], # 60-69 [], # 0-59 ] for i in stu_list: if i[1] >=90: stu_groups[0].append(i) elif i[1] >=80: stu_groups[1].append(i) elif i[1] >= 70: stu_groups[2].append(i) elif i[1] >= 60: stu_groups[3].append(i) else: stu_groups[4].append(i) for group in stu_groups: print(group) 结果: [['柴绍', 94], ['尉迟恭', 94], ['李存恭', 98], ['李隆基', 95], ['陈子昂', 91], ['杜牧', 95], ['李林甫', 95], ['高适', 100], ['鉴真', 90], ['韩愈', 100], ['刘知远', 95]] [['李渊', 82], ['长孙无忌', 85], ['徐世绩', 86], ['杨炯', 81], ['王之涣', 82], ['杨国忠', 84], ['玄奘', 84], ['高骈', 85], ['柳宗元', 88], ['荆浩', 84]] [['韦后', 76], ['卢照邻', 70], ['雷万春', 72], ['黄巢', 79], ['薛涛', 79], ['杜宇', 73], ['历真', 70]] [['房玄龄', 64], ['杜如晦', 65], ['李白', 61], ['张昌宗', 61], ['狄仁杰', 62], ['石敬瑭', 63]] [['李世民', 7], ['侯君集', 5], ['李靖', 58], ['魏征', 41], ['程知节', 45], ['秦琼', 54], ['封德彝', 16], ['段志玄', 44], ['刘弘基', 18], ['李治', 19], ['武则天', 39], ['太平公主', 57], ['杨玉环', 33], ['王勃', 49], ['安禄山', 18], ['史思明', 9], ['张巡', 15], ['高力士', 58], ['杜甫', 27], ['白居易', 5], ['王维', 14], ['孟浩然', 32], ['李商隐', 34], ['郭子仪', 53], ['张易之', 39], ['来俊臣', 8], ['王昌龄', 40], ['孙思邈', 46], ['王仙芝', 16], ['文成公主', 13], ['松赞干布', 47], ['鱼玄机', 16], ['贺知章', 20], ['李泌', 17], ['上官婉儿 五代十国:朱温', 55], ['刘仁恭', 6], ['丁会', 26], ['李克用', 39], ['李存勖', 11], ['葛从周', 25], ['王建', 13], ['郭威', 28], ['柴荣', 50], ['孟昶', 17], ['刘彟', 18], ['张及之', 45], ['高季兴', 39], ['喻皓', 50], ['李茂贞', 6], ['朱友珪', 7], ['朱友贞', 11], ['刘守光', 2]]列表的内存分析:
列表的声明和赋值
#声明一个列表存放不同类型的数据 lst=['钟无艳','橘右京',True,18]
列表数据的修改
#声明一个列表存放不同类型的数据 lst=['钟无艳','橘右京',True,18] lst[1]='马可波罗'
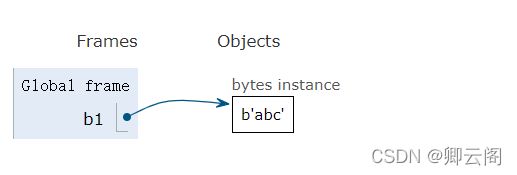
5.字节序列
b1=b"abc"
三,集合(不可修改)
a={1,2,3}

set不支持索引
set集合是一个无序不重复元素的集,基本功能包括关系测试和消除重复元素。集合使用大括号({})框定元素,并 以逗号6进行分隔。但是注意:如果要创建一个空集合,必须用 set() 而不是 {} ,因为后者创建的是一个空字典。 集合数据类型的核心在于自动去重。s={1,2,3,4} s.add(5) s.update("json")
# # # 集合 set 无序的, 不重复 set1 = {1, 2, 3} Movie1 = {"Alex", "佩奇", "村长", "pyyu", "qingyun", "black girl"} Movie2 = {"唐艺昕", "李孝利", "black girl", "刘诗诗", "李沁", "柳岩", "qingyun"} # 1,找出,同时参演了这两部电影的人都有谁(交集) print(Movie1 & Movie2) # # # 2,这两部电影中,一共包含了有哪些演员(并集) print(Movie1 | Movie2) # # # 3,参演了抗战片,五男大战黑姑娘的演员中,谁没有参演开心的一天 print(Movie1 - Movie2) # # # 4,哪些演员,只参演了一部电影 print(Movie1 ^ Movie2) #print(Movie1[0]) 集合不能通过下标来访问 set1 = {1, 1, 1, 1, 1, 2, 2, 2, 2, 4, 3, 3, 34, 4} print(set1) #集合会自动去重 # 可以帮助其它类型去重 lis1 = [23, 23, 23, 23, 3, 3, 4, 34, 3, 4] lis1 = list(set(lis1)) print(lis1) 结果: {'qingyun', 'black girl'} {'唐艺昕', '刘诗诗', '佩奇', '村长', 'Alex', 'pyyu', '柳岩', 'qingyun', '李孝利', '李沁', 'black girl'} {'Alex', '佩奇', 'pyyu', '村长'} {'唐艺昕', '柳岩', '李孝利', '佩奇', '村长', 'pyyu', 'Alex', '李沁', '刘诗诗'} {1, 2, 3, 4, 34} [34, 3, 4, 23]
四、字典(强调键值对应)
d={1:'food',2:'drink',3:'fruit'}

可以看到地址的分布是不连续的
访问字典字典是集合类型,不是序列类型,因此没有索引下标的概念,更没有切片的说法。但是,与list类似,字典采用把 相应的键放入方括号内获取对应值的方式取值。字典的重要方法。 key 必须为不可变数据类型(字符串、数字)、必须唯⼀get(key) 返回指定键的值,如果值不在字典中,则返回default值 items() 以列表返回可遍历的(键, 值) 元组对 keys() 以列表返回字典所有的键 values()以列表返回字典所有的值遍历字典d={1:'food',2:'drink',3:'fruit'} for k in d: print("键={0},值={1}".format(k,d[k])) 结果: 键=1,值=food 键=2,值=drink 键=3,值=fruit# -*- coding:utf-8 -*- dic = { "洪留荣" :[53,"教授",66000], "刘升" :[42,"教授",50000], "付明兰": [26,"讲师",40000], } print("付明兰" in dic) print(dic["付明兰"]) 结果; True [26, '讲师', 40000]操作
# -*- coding:utf-8 -*- dic = { "洪留荣" :[53,"教授",66000], "刘升" :[42,"教授",50000], "付明兰": [26,"讲师",40000], } #增加操作 dic["刘赛"] = [26, "讲师", 40000] #查操作 dic['刘赛'] #返回字典中key对应的值,若key不存在字典中,则报错; '刘赛' in dic #若存在则返回True,没有则返回False dic.keys() #返回⼀个包含字典所有KEY的列表; dic.values() #返回⼀个包含字典所有value的列表; dic.items() #返回⼀个包含所有(键,值)元组的列表; # k,v 2个变量 for k,v in dic.items(): print(k,v) for k in dic: print(k,dic[k]) #修改操作 dic['key'] = 'new_value' # 如果key在字典中存在,'new_value'将会替代原来的value值; #删除操作 dic.pop("刘赛") # 删除指定key del dic["付明兰"] # 删除指定key,同pop⽅法 dic.clear() # 清空dict补充:
在python中万物皆对象