受限玻尔兹曼机(RBM)原理总结
https://blog.csdn.net/l7H9JA4/article/details/81463954
授权转发自:刘建平《受限玻尔兹曼机(RBM)原理总结》
地址:http://www.cnblogs.com/pinard/p/6530523.html
前 言
本文主要关注于这类模型中的受限玻尔兹曼机(Restricted Boltzmann Machine,以下简称RBM),RBM模型及其推广在工业界比如推荐系统中得到了广泛的应用。
章节目录
-
RBM模型结构
-
RBM概率分布
-
RBM模型的损失函数与优化
-
RBM在实际中应用方法
-
RBM推广到DBM
-
RBM小结
01
RBM模型结构
玻尔兹曼机是一大类的神经网络模型,但是在实际应用中使用最多的则是RBM。RBM本身模型很简单,只是一个两层的神经网络,因此严格意义上不能算深度学习的范畴。不过深度玻尔兹曼机(Deep Boltzmann Machine,以下简称DBM)可以看做是RBM的推广。理解了RBM再去研究DBM就不难了,因此本文主要关注于RBM。
回到RBM的结构,它是一个个两层的神经网络,如下图所示:

上面一层神经元组成隐藏层(hidden layer), 用h向量隐藏层神经元的值。下面一层的神经元组成可见层(visible layer),用v向量表示可见层神经元的值。隐藏层和可见层之间是全连接的,这点和DNN类似, 隐藏层神经元之间是独立的,可见层神经元之间也是独立的。连接权重可以用矩阵W表示。和DNN的区别是,RBM不区分前向和反向,可见层的状态可以作用于隐藏层,而隐藏层的状态也可以作用于可见层。隐藏层的偏倚系数是向量b,而可见层的偏倚系数是向量a。
常用的RBM一般是二值的,即不管是隐藏层还是可见层,它们的神经元的取值只为0或者1。本文只讨论二值RBM。
总结下RBM模型结构的结构:主要是权重矩阵W, 偏倚系数向量a和b,隐藏层神经元状态向量h和可见层神经元状态向量v。
02
RBM概率分布
RBM是基于基于能量的概率分布模型。怎么理解呢?分两部分理解,第一部分是能量函数,第二部分是基于能量函数的概率分布函数。
对于给定的状态向量h和v,则RBM当前的能量函数可以表示为:
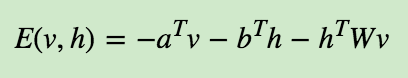
有了能量函数,则我们可以定义RBM的状态为给定v,h的概率分布为:
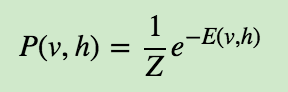
其中Z为归一化因子,类似于softmax中的归一化因子,表达式为:

有了概率分布,我们现在来看条件分布P(h|v):
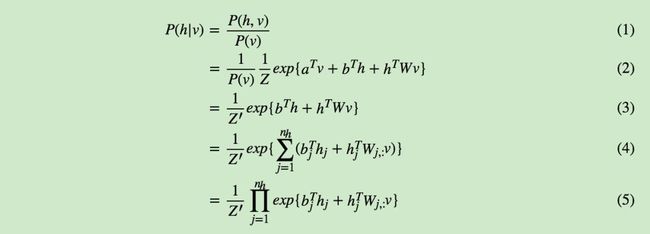
其中Z′为新的归一化系数,表达式为:
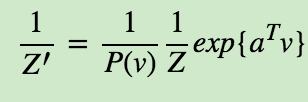
同样的方式,我们也可以求出P(v|h),这里就不再列出了。
有了条件概率分布,现在我们来看看RBM的激活函数,提到神经网络,我们都绕不开激活函数,但是上面我们并没有提到。由于使用的是能量概率模型,RBM的基于条件分布的激活函数是很容易推导出来的。我们以P(hj=1|v)为例推导如下。
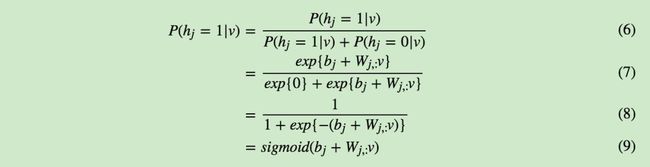
从上面可以看出, RBM里从可见层到隐藏层用的其实就是sigmoid激活函数。同样的方法,我们也可以得到隐藏层到可见层用的也是sigmoid激活函数。即:
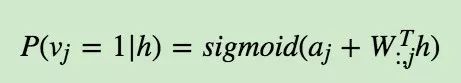
有了激活函数,我们就可以从可见层和参数推导出隐藏层的神经元的取值概率了。对于0,1取值的情况,则大于0.5即取值为1。从隐藏层和参数推导出可见的神经元的取值方法也是一样的。
03
RBM模型的损失函数与优化
RBM模型的关键就是求出我们模型中的参数W,a,b。如果求出呢?对于训练集的m个样本,RBM一般采用对数损失函数,即期望最小化下式:

对于优化过程,我们是首先想到的当然是梯度下降法来迭代求出W,a,b。我们首先来看单个样本的梯度计算, 单个样本的损失函数为:−ln(P(V)), 我们先看看−ln(P(V))具体的内容:

注意,这里面V表示的是某个特定训练样本,而v指的是任意一个样本。
我们以ai的梯度计算为例:

其中用到了:

同样的方法,可以得到W,b的梯度。这里就不推导了,直接给出结果:
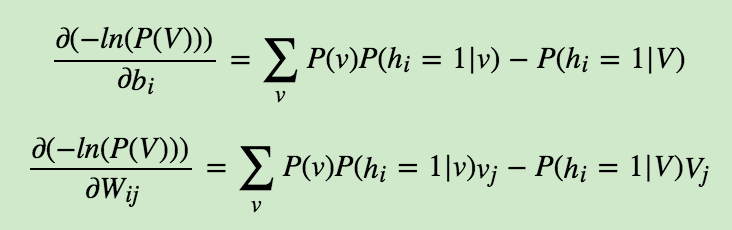
虽然梯度下降法可以从理论上解决RBM的优化,但是在实际应用中,由于概率分布的计算量大,因为概率分布有2^nv+nh种情况, 所以往往不直接按上面的梯度公式去求所有样本的梯度和,而是用基于MCMC的方法来模拟计算求解每个样本的梯度损失再求梯度和,常用的方法是基于Gibbs采样的对比散度方法来求解,对于对比散度方法,由于需要MCMC的知识,这里就不展开了。对对比散度方法感兴趣的可以看参考文献中2的《A Practical Guide to Training Restricted Boltzmann Machines》,对于MCMC,后面我专门开篇来讲。
04
RBM在实际中应用方法
大家也许会疑惑,这么一个模型在实际中如何能够应用呢?比如在推荐系统中是如何应用的呢?这里概述下推荐系统中使用的常用思路。
RBM可以看做是一个编码解码的过程,从可见层到隐藏层就是编码,而反过来从隐藏层到可见层就是解码。在推荐系统中,我们可以把每个用户对各个物品的评分做为可见层神经元的输入,然后有多少个用户就有了多少个训练样本。由于用户不是对所有的物品都有评分,所以任意样本有些可见层神经元没有值。但是这不影响我们的模型训练。在训练模型时,对于每个样本,我们仅仅用有用户数值的可见层神经元来训练模型。
对于可见层输入的训练样本和随机初始化的W,a,我们可以用上面的sigmoid激活函数得到隐藏层的神经元的0,1值,这就是编码。然后反过来从隐藏层的神经元值和W,b可以得到可见层输出,这就是解码。对于每个训练样本, 我们期望编码解码后的可见层输出和我们的之前可见层输入的差距尽量的小,即上面的对数似然损失函数尽可能小。按照这个损失函数,我们通过迭代优化得到W,a,b,然后对于某个用于那些没有评分的物品,我们用解码的过程可以得到一个预测评分,取最高的若干评分对应物品即可做用户物品推荐了。
如果大家对RBM在推荐系统的应用具体内容感兴趣,可以阅读参考文献3中的《Restricted Boltzmann Machines for Collaborative Filtering》
05
RBM推广到DBM
RBM很容易推广到深层的RBM,即我们的DBM。推广的方法就是加入更多的隐藏层,比如一个三层的DBM如下:
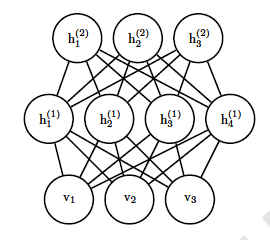
当然隐藏层的层数可以是任意的,随着层数越来越复杂,那模型怎么表示呢?其实DBM也可以看做是一个RBM,比如下图的一个4层DBM,稍微加以变换就可以看做是一个DBM。

将可见层和偶数隐藏层放在一边,将奇数隐藏层放在另一边,我们就得到了RBM,和RBM的细微区别只是现在的RBM并不是全连接的,其实也可以看做部分权重为0的全连接RBM。RBM的算法思想可以在DBM上使用。只是此时我们的模型参数更加的多,而且迭代求解参数也更加复杂了。
06
RBM小结
RBM所在的玻尔兹曼机流派是深度学习中三大流派之一,也是目前比较热门的创新区域之一,目前在实际应用中的比较成功的是推荐系统。以后应该会有更多类型的玻尔兹曼机及应用开发出来,让我们拭目以待吧!

END