Kafka 与 Flume
一、Kafka与Flume比较
1、Flume主要是为了发送数据给HDFS和HBase用的工具。 Flume集成了Hadoop的安全体系。
如果数据将被多个系统所消费,那么采用Kafka。
Kafka是一个更加通用的系统。 可以有很多数据的Producer和Consumer。 这些Consumer之间共享多个主题。
2、Flume具有多个内置的源和sink,
如果Flume的源和sink正好满足你的要求,而且你希望使用一个不需要开发的采集系统(只需要配置),那么你就使用Flume。
相对而言,Kafka只有一个较少的Producer和COnsumer生态圈。
如果你想开发一个采集系统,那就基于Kafka开发。
3、Flume可以使用interceptors来即时处理数据,这对对数据过滤由帮助;
Kafka需要外部的流处理系统来完成这个功能。
4、都是可靠的系统,都可以保证数据不会丢失。
5、Flume和Kafka可以一起工作。
如果你需要从Kafka流数据到Hadoop,那么就可以将Flume代理和Kafka源一起使用来读取数据。
二、Kafka 消息订阅分发系统
是一个分布式的消息队列,可用在不同的系统之间传递数据。 实际上是一个消息发布订阅系统。
开源
Scala编写
多个交换部门之间进行交换,每两个之间都建立交换通道的话,最后形成一张维护难度极大的数据交换网络,不好。
Kafka可以解决这个问题,它可以担当中间桥梁。
它使用了多种优化机制,整体架构比较新颖(push/pull),更适合异构集群。
它实现了高吞吐率,在普通的服务器上每秒也能处理几十万条信息。
Kafka架构:
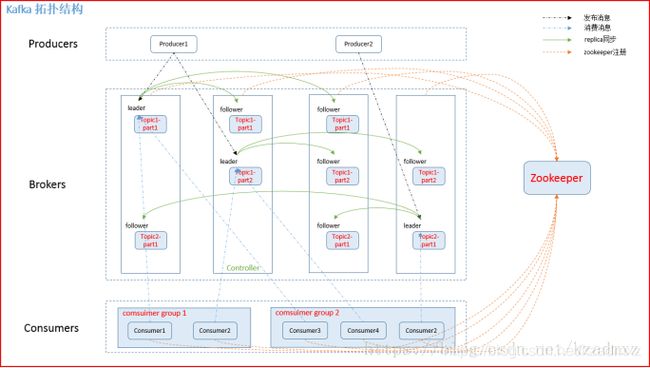
Kafka集群由多个Kafka实例(server)组成,每个实例成为Broker
无论是Kafka集群还是Producer、Consumer都依赖于ZooKeeper来保证分布式协作、负载均衡。
Kafka中主要由三种角色:Producer、Broker、Consumer。
1 Producer(生产者) 用于将流数据发送到Kafka消息队列上,它的任务时向Broker发送数据。
2 Broker Kafka包含一个或多个服务器,这种服务器成为Broker。
3 Consumer(消费者) 作用是处理数据, 比如将消息加载到持久化存储系统上。
Kafka是基于文件系统存储。 通过分区(partiton)将文件内容分散到多个server上来避免文件大小达到单机磁盘的上限,没分分区都会被当前server(Kafka实例)保存。
更多kafka介绍,请见本人另一篇博文: https://blog.csdn.net/kzadmxz/article/details/80487313
三、Flume【海量数据(日志)采集系统
用于从不同的数据源可靠有效地加载数据流到HDFS中。
具有一定的容错性,并支持failover和系统恢复。
Flume是一个分布式、高容错、高可靠、高可用、易于定制和扩展的轻量级工具,
非常简单,容易适应各种方式的数据收集。
Java编写,需要运行在Java1.6之上。
Flume将数据从产生、传输、处理并写入目标的路径的过程抽象为数据流。
总之,Flume是一个可扩展、适合复杂环境的海量数据采集系统。
Flume架构:

核心概念:
事件 (Event):Flume传递的一个数据单元,除了采集到的数据(如单个日志)之外,它还带有可选的消息头。
源 (Source):
接收器 (Sink):
通道 (Channel):
数据流 (Flow):
Flume代理 (Agent):
Flume在源Source和接收段Sink 使用了transaction(事务)机制保证在数据传输中没有数据丢失。如图
