定长图文验证码模型训练
文章目录
-
- 自定义数据集生成
- 模型代码
- 计算均值和标准差
- 训练代码
- 测试集成功率计算
- 推理测试
市面上常见的验证码识别方案包括:
-
基于规则的方案:这种识别方案针对一些特定类型的验证码(如数字、字母组合),利用编写规则的方式来分析和提取验证码特征,然后通过对比特征来识别验证码。这种方案比较容易实现,但对于一些复杂的验证码可能无法适用。
-
基于机器学习的方案:这种方案需要通过已经标记的训练数据来训练模型,然后使用训练好的模型来对新的验证码进行识别。 常用的算法包括SVM,Boosting,Random Forests等。
-
基于深度学习的方案:这种方案使用深度学习算法来训练神经网络,然后使用训练好的神经网络对新的验证码进行识别。这种方案的训练需要大量的数据和计算资源,但是可以获得更高的识别精度。 常见的算法包括卷积神经网络(CNN)、循环神经网络(RNN)等。
-
基于人工智能的方案:这种方案利用人工智能算法来实现验证码识别,例如最小割算法、模拟退火算法、遗传算法等。相较于其他方案,需要更多的算法优化和参数调整,复杂度较高。
总之,市面上的验证码识别方案有多种,针对不同类型的验证码,可以选择不同的识别方案来实现更优秀的效果。
本次基于深度学习训练定长图文模型
自定义数据集生成
为节约数据搜集和打标的时间,这里我们选择自己生成数据集进行训练,思路通用
import random
from PIL import Image, ImageDraw, ImageFont, ImageFilter
from io import BytesIO
import base64
import os
import time
def GBK2312():
value = ''
for i in range(36):
head = random.randint(0xb0, 0xe7)
body = random.randint(0xa1, 0xee)
val = f'{head:x} {body:x}'
value += bytes.fromhex(val).decode('gb2312')
return value
# 小写字母,去除可能干扰的i,l,o,z
# _letter_cases = "abcdefghjkmnpqrstuvwxy"
# _upper_cases = _letter_cases.upper() # 大写字母
# _numbers = ''.join(map(str, range(2, 10))) # 数字
# init_chars = ''.join((_letter_cases, _upper_cases, _numbers, GBK2312()))
init_chars = 'abcdefgh' # 初始化数据
def create_validate_code(fg_color,
chars=init_chars,
size=(150, 50),
mode="RGB",
bg_color=(255, 255, 255),
font_size=18,
font_type="./msyh.ttc",
length=4, # 4位一组
draw_lines=True,
n_line=(1, 2),
draw_points=True,
point_chance=1):
"""
@todo: 生成验证码图片
@param size: 图片的大小,格式(宽,高),默认为(120, 30)
@param chars: 允许的字符集合,格式字符串
@param img_type: 图片保存的格式,默认为GIF,可选的为GIF,JPEG,TIFF,PNG
@param mode: 图片模式,默认为RGB
@param bg_color: 背景颜色,默认为白色
@param fg_color: 前景色,验证码字符颜色,默认为蓝色#0000FF
@param font_size: 验证码字体大小
@param font_type: 验证码字体
@param length: 验证码字符个数
@param draw_lines: 是否划干扰线
@param n_lines: 干扰线的条数范围,格式元组,默认为(1, 2),只有draw_lines为True时有效
@param draw_points: 是否画干扰点
@param point_chance: 干扰点出现的概率,大小范围[0, 100]
@return: [0]: PIL Image实例
@return: [1]: 验证码图片中的字符串
"""
width, height = size # 宽高
# 创建图形
img = Image.new(mode, size, bg_color)
draw = ImageDraw.Draw(img) # 创建画笔
def get_chars():
"""生成给定长度的字符串,返回列表格式"""
return random.sample(chars, length)
def create_lines():
"""绘制干扰线"""
line_num = random.randint(*n_line) # 干扰线条数
for i in range(line_num):
# 起始点
begin = (random.randint(0, size[0]), random.randint(0, size[1]))
# 结束点
end = (random.randint(0, size[0]), random.randint(0, size[1]))
draw.line([begin, end], fill=(0, 0, 0))
def create_points():
"""绘制干扰点"""
chance = min(100, max(0, int(point_chance))) # 大小限制在[0, 100]
for w in range(width):
for h in range(height):
tmp = random.randint(0, 100)
if tmp > 100 - chance:
draw.point((w, h), fill=(0, 0, 0))
def create_strs():
"""绘制验证码字符"""
c_chars = get_chars()
strs = ' %s ' % ' '.join(c_chars) # 每个字符前后以空格隔开
font = ImageFont.truetype(font_type, font_size)
font_width, font_height = font.getsize(strs)
font_width /= 0.7
font_height /= 0.7
draw.text(((width - font_width) / 3, (height - font_height) / 3),
strs, font=font, fill=fg_color)
return ''.join(c_chars)
if draw_lines:
create_lines()
if draw_points:
create_points()
strs = create_strs()
# 图形扭曲参数
params = [1 - float(random.randint(1, 2)) / 80,
0,
0,
0,
1 - float(random.randint(1, 10)) / 80,
float(random.randint(3, 5)) / 450,
0.001,
float(random.randint(3, 5)) / 450
]
img = img.transform(size, Image.PERSPECTIVE, params) # 创建扭曲
output_buffer = BytesIO()
img.save(output_buffer, format='PNG')
img_byte_data = output_buffer.getvalue()
# img = img.filter(ImageFilter.EDGE_ENHANCE_MORE) # 滤镜,边界加强(阈值更大)
return img_byte_data, strs
# try:
# os.mkdir('./训练图片生成')
# except FileExistsError:
# print('训练图片生成 文件夹已经存在')
# print('生成存储文件夹成功')
while 1:
number = input('请输入要生成的验证码数量:')
try:
for i in range(int(number)):
res = create_validate_code((random.randint(0, 255), random.randint(0, 255), random.randint(0, 255)), chars=init_chars)
# picture作为训练数据集目录 test作为测试数据集目录
with open('./picture/{0}_{1}.png'.format(res[1], int(time.time())), 'wb') as f:
# with open('./test/{0}_{1}.png'.format(res[1], int(time.time())), 'wb') as f:
f.write(res[0])
print('生成第', i+1, '个图片成功')
except ValueError:
print('请输入一个数字,不要输入乱七八糟的东西,打你哦')
except:
import traceback
traceback.print_exc()
break
input('理论上生成完成了~,QAQ 共生成了' + number + '个验证码')
input('出现未知错误,错误已打印')
先创建picture和test目录,picture作为训练数据集目录 test作为测试数据集目录
先用以上程序生成3000张训练数据图片集:
再生成200张测试数据集:
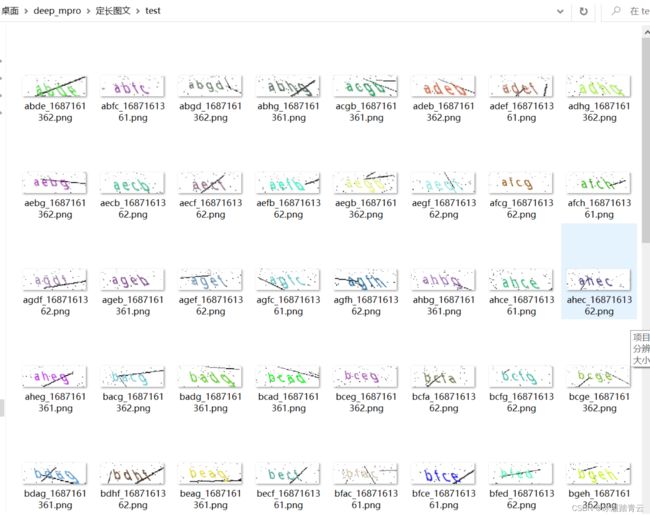
图片增加了较多的干扰,还是比较难以识别的
模型代码
本次直接选用resnet18
from torch import nn
from torchvision import models
class AnlanNet(nn.Module):
def __init__(self):
super(AnlanNet, self).__init__()
self.resnet18 = models.resnet18(num_classes=4*8)
def forward(self, x):
x = self.resnet18(x)
return x
ResNet18的基本含义是,网络的基本架构是ResNet,网络的深度是18层。但是这里的网络深度指的是网络的权重层,也就是包括池化,激活,线性层。而不包括批量化归一层,池化层。
计算均值和标准差
from torch.utils.data import Dataset
import os
from PIL import Image
import torch
class LetterDataset(Dataset):
def __init__(self, root: str, transform=None):
super(LetterDataset, self).__init__()
self.path = root
self.transform = transform
# 可优化
self.mapping = ['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h']
def load_picture_path(self):
picture_list = list(os.walk(self.path))[0][-1]
# 这里可以增加很多的错误判断
return picture_list
def __len__(self):
return len(self.load_picture_path())
def __getitem__(self, item):
load_picture = self.load_picture_path()
image = Image.open(self.path + '/' +load_picture[item])
if self.transform:
image = self.transform(image)
labels = [self.mapping.index(i) for i in load_picture[item].split('_')[0]]
labels = torch.as_tensor(labels, dtype=torch.int64)
return image, labels
if __name__ == '__main__':
from tqdm import tqdm
import numpy as np
from torchvision import transforms
transform = transforms.Compose([transforms.ToTensor(),])
my_train = LetterDataset(root="./picture", transform=transform)
total_mean = [[], [], []]
total_std = [[], [], []]
res_total = [0, 0, 0]
res_std = [0, 0, 0]
for i in tqdm(range(len(my_train))):
for j in range(len(total_std)):
total_mean[j].append([np.array(my_train[i][0][j])])
total_std[j].append([np.array(my_train[i][0][j])])
for i in range(len(total_std)):
res_total[i] = np.mean(total_mean[i])
res_std[i] = np.std(total_std[i])
print(res_total, res_std)
# 训练和推理时transform里要用这个
# [0.945965, 0.94634837, 0.9464047] [0.19021708, 0.18938343, 0.189083]
训练代码
from torch import save, load
from test_p import test
from torchvision import transforms
from torch.utils.data import DataLoader
from torch import nn
from torch import optim
from tqdm import tqdm
from MyModels import AnlanNet
from MyDataset import LetterDataset
import os
import numpy as np
import torch
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# 实例化模型
model = AnlanNet()
model = model.to(device)
optimizer = optim.Adam(model.parameters())
batch_size = 8
# 加载已经训练好的模型和优化器继续进行训练
if os.path.exists('./models/model.pkl'):
model.load_state_dict(load("./models/model.pkl"))
optimizer.load_state_dict(load("./models/optimizer.pkl"))
loss_function = nn.CrossEntropyLoss()
my_transforms = transforms.Compose(
[
transforms.ToTensor(),
transforms.Normalize(mean=(0.94627863, 0.9466971, 0.9461433), std=(0.18962398, 0.18830799, 0.1896048))
]
)
mnist_train = LetterDataset(root="./picture", transform=my_transforms)
def train(epoch):
total_loss = []
dataloader = DataLoader(mnist_train, batch_size=batch_size, shuffle=True, drop_last=True)
dataloader = tqdm(dataloader, total=len(dataloader))
model.train()
for images, labels in dataloader:
images = images.to(device)
labels = labels.to(device)
# 梯度置0
optimizer.zero_grad()
# 前向传播
output = model(images)
# 通过结果计算损失
output = output.view(batch_size*4, 8)
labels = labels.view(-1)
#
loss = loss_function(output, labels)
total_loss.append(loss.item())
dataloader.set_description('loss:{}'.format(np.mean(total_loss)))
# 反向传播
loss.backward()
# 优化器更新
optimizer.step()
save(model.state_dict(), './models/model.pkl')
save(optimizer.state_dict(), './models/optimizer.pkl')
# 打印一下训练成功率, test.test_success()
print('第{}个epoch,成功率, 损失为{}'.format(epoch, np.mean(total_loss)))
for i in range(10):
train(i)
print(test())
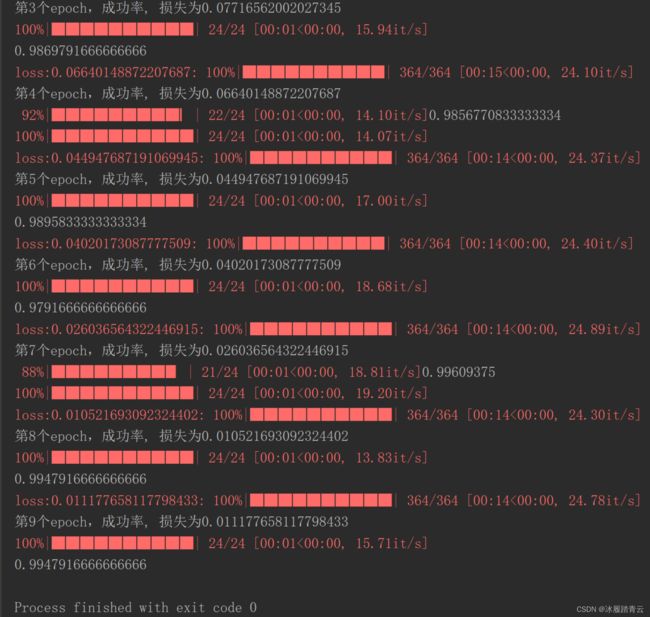
至此模型已经训练好了,看着成功率还挺高的,接下来就看一下使用我们训练好的模型,在测试集上的表现
测试集成功率计算
from torch import save, load
import torch
from torchvision import transforms
from torch.utils.data import DataLoader
from torch import nn
from torch import optim
from tqdm import tqdm
from MyModels import AnlanNet
from MyDataset import LetterDataset
import os
import numpy as np
def test():
# 实例化模型
model = AnlanNet()
optimizer = optim.Adam(model.parameters())
batch_size = 8
# 加载已经训练好的模型和优化器继续进行训练
if os.path.exists('./models/model.pkl'):
model.load_state_dict(load("./models/model.pkl"))
optimizer.load_state_dict(load("./models/optimizer.pkl"))
loss_function = nn.CrossEntropyLoss()
my_transforms = transforms.Compose(
[
transforms.ToTensor(),
transforms.Normalize(mean=(0.945965, 0.94634837, 0.9464047), std=(0.19021708, 0.18938343, 0.189083))
]
)
mnist_train = LetterDataset(root="./test", transform=my_transforms)
total_loss = []
total_acc = []
dataloader = DataLoader(mnist_train, batch_size=batch_size, shuffle=True, drop_last=True)
dataloader = tqdm(dataloader, total=len(dataloader))
model.eval()
with torch.no_grad():
for images, labels in dataloader:
output = model(images)
# 通过结果计算损失
output = output.view(batch_size*4, 8)
labels = labels.view(-1)
loss = loss_function(output, labels)
total_loss.append(loss.item())
# dataloader.set_description('loss:{}'.format(np.mean(total_loss)))
pred = output.max(dim=1)[1]
total_acc.append(pred.eq(labels).float().mean().item())
return np.mean(total_acc)
if __name__ == '__main__':
print(test())

模型在测试集上的表现也很好,成功率高达0.99
推理测试
我们单独生成一张图片进行推理测试,本地生成一张图片test.png。
推理代码:
from torch import load
import torch
from torchvision import transforms
from MyModels import AnlanNet
import os
from PIL import Image
# 实例化模型
model = AnlanNet()
if os.path.exists('./models/model.pkl'):
model.load_state_dict(load("./models/model.pkl"))
my_transforms = transforms.Compose(
[
transforms.ToTensor(),
transforms.Normalize(mean=(0.94627863, 0.9466971, 0.9461433), std=(0.18962398, 0.18830799, 0.1896048))
]
)
mapping = ['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h']
model.eval()
with torch.no_grad():
images = my_transforms(Image.open('test.png'))
images = images.view(1, 3, 50, 150)
output = model(images)
# 通过结果计算损失
output = output.view(4, 8)
pred = output.max(dim=1)[1]
print([mapping[i] for i in list(pred.numpy())])
结果:

还是比较准确的!