哈希函数和哈希表及其应用
哈希函数-散列函数
1.输入阈无穷大
2.输出阈有穷尽,S阈
3.输入参数一样,返回值也是一样的
4.输入不一样,输出也可能一样,哈希碰撞
5.两个不同输入对应一样的输出值,若输入域样本足够大,对应的输出每一个中的点对应的数量差不多,均匀分布(喷香水,香水分子均匀分布在房间内,所以叫做打乱/散列函数)
大数据问题:若将一个100T的大文件中的重复的字符串打印出来,给1000个机器,0~999号机器,大文件存在分布式系统上,若处理这个大文件按行读取,有读取效率很高的工具:
通过哈希表分流,用分布式文件读取的方法,把每一行的文件读出来,每一行作为一个文本,用哈希函数把每一个文本的哈希code都出来,然后模上1000,分到一千个机器上,相同的文本一定会分到同一个机器上,重复的文本会分到同一台机器上,文件种类相同的会均匀的分到1000个机器上,然后单独在每台机器进行重复的处理,一台机器上可以跑并行任务,大任务化成小任务。原理:相同输入导致相同输出,不同输入均匀分布!
哈希表就是利用哈希函数分桶,桶结构如果开始效率变差,就将整体进行扩容。
题目一:认识哈希函数和哈希表
package zuoshen5;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map.Entry;
public class Code_01_HashMap {
public static void main(String[] args) {
HashMap map = new HashMap<>();
map.put("zuo", "31");
System.out.println(map.containsKey("zuo"));
System.out.println(map.containsKey("chengyun"));
System.out.println("=========================");
System.out.println(map.get("zuo"));
System.out.println(map.get("chengyun"));
System.out.println("=========================");
System.out.println(map.isEmpty());
System.out.println(map.size());
System.out.println("=========================");
System.out.println(map.remove("zuo"));
System.out.println(map.containsKey("zuo"));
System.out.println(map.get("zuo"));
System.out.println(map.isEmpty());
System.out.println(map.size());
System.out.println("=========================");
map.put("zuo", "31");
System.out.println(map.get("zuo"));
map.put("zuo", "32");
System.out.println(map.get("zuo"));
System.out.println("=========================");
map.put("zuo", "31");
map.put("cheng", "32");
map.put("yun", "33");
for (String key : map.keySet()) {
System.out.println(key);
}
System.out.println("=========================");
for (String values : map.values()) {
System.out.println(values);
}
System.out.println("=========================");
map.clear();
map.put("A", "1");
map.put("B", "2");
map.put("C", "3");
map.put("D", "1");
map.put("E", "2");
map.put("F", "3");
map.put("G", "1");
map.put("H", "2");
map.put("I", "3");
for (Entry entry : map.entrySet()) {
String key = entry.getKey();
String value = entry.getValue();
System.out.println(key + "," + value);
}
System.out.println("=========================");
// you can not remove item in map when you use the iterator of map
// for(Entry entry : map.entrySet()){
// if(!entry.getValue().equals("1")){
// map.remove(entry.getKey());
// }
// }
// if you want to remove items, collect them first, then remove them by
// this way.
List removeKeys = new ArrayList();
for (Entry entry : map.entrySet()) {
if (!entry.getValue().equals("1")) {
removeKeys.add(entry.getKey());
}
}
for (String removeKey : removeKeys) {
map.remove(removeKey);
}
for (Entry entry : map.entrySet()) {
String key = entry.getKey();
String value = entry.getValue();
System.out.println(key + "," + value);
}
System.out.println("=========================");
}
}
题目二:设计RandomPool结构
【题目】 设计一种结构,在该结构中有如下三个功能: insert(key):将某个key加入到该结构,做到不重复加入。 delete(key):将原本在结构中的某个key移除。 getRandom(): 等概率随机返回结构中的任何一个key。 【要求】 Insert、delete和getRandom方法的时间复杂度都是 O(1)
package zuoshen5;
import java.util.HashMap;
public class Code_02_RandomPool {
public static class pool{
private HashMapkeyIndexMap;
private HashMapindexKeyMap;
private int size;
public pool(){
this.keyIndexMap=new HashMap();
this.indexKeyMap=new HashMap();
this.size=0;
}
public void insert(K key){
if(!this.keyIndexMap.containsKey(key)){
this.keyIndexMap.put(key,this.size);
this.indexKeyMap.put(this.size++,key);
}
}
public void delete(K key){
if(this.keyIndexMap.containsKey(key)){
int deleteIndex=this.keyIndexMap.get(key);//找到需要删除的索引
int lastIndex=--this.size;//最后一个索引
K lastKey=this.indexKeyMap.get(lastIndex);//最后一个索引的值
//交换要删除的和最后一个,也就是拿最后一个补前边删除的“洞”,然后删除
this.keyIndexMap.put(lastKey,deleteIndex);
this.indexKeyMap.put(deleteIndex,lastKey);
this.keyIndexMap.remove(lastKey);
this.indexKeyMap.remove(deleteIndex);
}
}
public K getRandom(){
if(this.size==0){
return null;
}
int randomIndex=(int)(Math.random()*this.size);//0~size-1
return this.indexKeyMap.get(randomIndex);
}
}
public static void main(String[] args) {
poolpool=new pool();
pool.insert("gai");
pool.insert("xin");
pool.insert("yu");
System.out.println(pool.getRandom());
System.out.println(pool.getRandom());
System.out.println(pool.getRandom());
System.out.println(pool.getRandom());
}
}
题目四:认识布隆过滤器
布隆过滤器原理:https://blog.csdn.net/weixin_44021180/article/details/108942059

具体的操作流程:假设集合里面有3个元素{x, y, z},哈希函数的个数为3。首先将位数组进行初始化,将里面每个位都设置位0。对于集合里面的每一个元素,将元素依次通过3个哈希函数进行映射,每次映射都会产生一个哈希值,这个值对应位数组上面的一个点,然后将位数组对应的位置标记为1。查询W元素是否存在集合中的时候,同样的方法将W通过哈希映射到位数组上的3个点。如果3个点的其中有一个点不为1,则可以判断该元素一定不存在集合中。反之,如果3个点都为1,则该元素可能存在集合中。注意:此处不能判断该元素是否一定存在集合中,可能存在一定的误判率。可以从图中可以看到:假设某个元素通过映射对应下标为4,5,6这3个点。虽然这3个点都为1,但是很明显这3个点是不同元素经过哈希得到的位置,因此这种情况说明元素虽然不在集合中,也可能对应的都是1,这是误判率存在的原因。
//https://blog.csdn.net/u014653197/article/details/76397037
public class BloomFilter implements Serializable{
private final int[] seeds;
private final int size;
private final BitSet notebook;
private final MisjudgmentRate rate;
private final AtomicInteger useCount = new AtomicInteger();
private final Double autoClearRate;
//dataCount逾预期处理的数据规模
public BloomFilter(int dataCount){
this(MisjudgmentRate.MIDDLE, dataCount, null);
}
//自动清空过滤器内部信息的使用比率,传null则表示不会自动清理;
//当过滤器使用率达到100%时,则无论传入什么数据,都会认为在数据已经存在了;
//当希望过滤器使用率达到80%时自动清空重新使用,则传入0.8
public BloomFilter(MisjudgmentRate rate, int dataCount, Double autoClearRate){
//每个字符串需要的bit位数*总数据量
long bitSize = rate.seeds.length * dataCount;
if(bitSize<0 || bitSize>Integer.MAX_VALUE){
throw new RuntimeException("位数太大溢出了,请降低误判率或者降低数据大小");
}
this.rate = rate;
seeds = rate.seeds;
size = (int)bitSize;
//创建一个BitSet位集合
notebook = new BitSet(size);
this.autoClearRate = autoClearRate;
}
//如果存在返回true,不存在返回false
public boolean addIfNotExist(String data){
//是否需要清理
checkNeedClear();
//seeds.length决定每一个string对应多少个bit位,每一位都有一个索引值
//给定data,求出data字符串的第一个索引值index,如果第一个index值对应的bit=false说明,该data值不存在,则直接将所有对应bit位置为true即可;
//如果第一个index值对应bit=true,则将index值保存,但此时并不能说明data已经存在,
//则继续求解第二个index值,若所有index值都不存在则说明该data值不存在,将之前保存的index数组对应的bit位置为true
int[] indexs = new int[seeds.length];
//假定data已经存在
boolean exist = true;
int index;
for(int i=0; i0){
for(int i=0; i= autoClearRate){
synchronized (this) {
if(getUseRate() >= autoClearRate){
notebook.clear();
useCount.set(0);
}
}
}
}
}
private Double getUseRate() {
return (double)useCount.intValue()/(double)size;
}
public void saveFilterToFile(String path) {
try (ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream(path))) {
oos.writeObject(this);
} catch (Exception e) {
throw new RuntimeException(e);
}
}
public static BloomFilter readFilterFromFile(String path) {
try (ObjectInputStream ois = new ObjectInputStream(new FileInputStream(path))) {
return (BloomFilter) ois.readObject();
} catch (Exception e) {
throw new RuntimeException(e);
}
}
/**
* 清空过滤器中的记录信息
*/
public void clear() {
useCount.set(0);
notebook.clear();
}
public MisjudgmentRate getRate() {
return rate;
}
/**
* 分配的位数越多,误判率越低但是越占内存
*
* 4个位误判率大概是0.14689159766308
*
* 8个位误判率大概是0.02157714146322
*
* 16个位误判率大概是0.00046557303372
*
* 32个位误判率大概是0.00000021167340
*
*/
public enum MisjudgmentRate {
// 这里要选取质数,能很好的降低错误率
/**
* 每个字符串分配4个位
*/
VERY_SMALL(new int[] { 2, 3, 5, 7 }),
/**
* 每个字符串分配8个位
*/
SMALL(new int[] { 2, 3, 5, 7, 11, 13, 17, 19 }), //
/**
* 每个字符串分配16个位
*/
MIDDLE(new int[] { 2, 3, 5, 7, 11, 13, 17, 19, 23, 29, 31, 37, 41, 43, 47, 53 }), //
/**
* 每个字符串分配32个位
*/
HIGH(new int[] { 2, 3, 5, 7, 11, 13, 17, 19, 23, 29, 31, 37, 41, 43, 47, 53, 59, 61, 67, 71, 73, 79, 83, 89, 97,
101, 103, 107, 109, 113, 127, 131 });
private int[] seeds;
//枚举类型MIDDLE构造函数将seeds数组初始化
private MisjudgmentRate(int[] seeds) {
this.seeds = seeds;
}
public int[] getSeeds() {
return seeds;
}
public void setSeeds(int[] seeds) {
this.seeds = seeds;
}
}
public static void main(String[] args) {
BloomFilter fileter = new BloomFilter(7);
System.out.println(fileter.addIfNotExist("1111111111111"));
System.out.println(fileter.addIfNotExist("2222222222222222"));
System.out.println(fileter.addIfNotExist("3333333333333333"));
System.out.println(fileter.addIfNotExist("444444444444444"));
System.out.println(fileter.addIfNotExist("5555555555555"));
System.out.println(fileter.addIfNotExist("6666666666666"));
System.out.println(fileter.addIfNotExist("1111111111111"));
//fileter.saveFilterToFile("C:\\Users\\john\\Desktop\\1111\\11.obj");
//fileter = readFilterFromFile("C:\\Users\\john\\Desktop\\111\\11.obj");
System.out.println(fileter.getUseRate());
System.out.println(fileter.addIfNotExist("1111111111111"));
}
} 题目四:认识一致性哈希
一致性哈希就是一种服务器的设计。
先说经典的服务器是怎样的抗压结构:有一个前端来接收request,假设现在有三台机器012,前端里边带有相同的哈希函数,值经过哈希函数,可能会得到012其中的一个值,就存到012相应的一个中,然后因为不同的string经过哈希函数计算之后,均匀的得到012中的一个,所以012三台机器负载均衡(每一台机器占用的内存,CPU……一些性能指标差不多),在查找的过程中,就将要查找的值进行模函数计算,之后对应机器上将对应的值提取出来。
有一个问题:当想要加减机器的时候,这时候需要模其他的数,所有的数据都需要迁移,需要将所有数据全部拿出来重新计算,再放到相应机器上
一致性哈希可以解决这个问题,并且可以保证负载均衡
结构:假设hash范围是0~2^64,将其想象成一个环,假设有三台机器,将m1,m2,m3三台机器通过函数,对应到环上,这时候开始存数据,将数据的value进行计算,会对应到环上的一个位置,顺时针找到离它最近的机器,就归属于这个机器上,

实现:后端还是三台机器,前端还是无差别的负载的服务器,将m1.m2,m3排序之后组成一个数组,进来的数据从左到右二分的方式进行查找,找到第一个>=这个数的机器


在这种环上加一台机器:
加一个m4,m4对应环上一个位置,将本来属于m3上的数的一部分给m4
减一台机器:
给m3
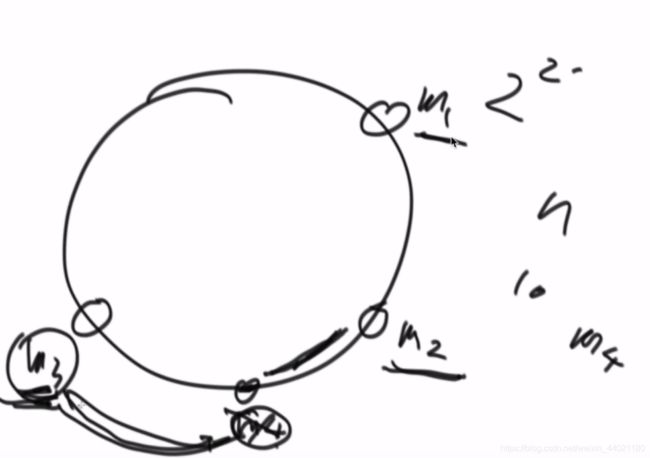
这种结构的问题:
1.机器分布不均匀
2.用某些手段使得最开始分布均匀,但加上或者减掉机器之后又不均衡了
若能解决这两个问题,就可以实现即做到数据迁移的代价很低,又能保证负载均衡了。
虚拟节点技术可以解决这个问题:
真实机器m1,m2,m3:
不让m1的IP去抢这个环,给这三个机器都分配1000个虚拟节点,准备一张路由表(从真实的物理机器去查它有哪些虚拟节点,从虚拟节点反查它属于哪个物理节点也可以查),用虚拟节点去抢环,会抢到自己的位置,m1的1000个位置都属于m1来管理,达到均分的效果,这时候加一个m4,也是1000个节点,这时候还是均分的,无论加还是减,负载还是超级均衡的。这就是一致性哈希。只是需要解决哈希冲突的问题:概率非常低。
用途场合:基本所有需要集群化,抗压力的,都需要。
题目六:认识并查集结构
解决的问题:
1.快速检查两个元素是否属于一个集合,isSameSet(A,B)两个集合的代表集合(往上查直到这个节点自己指向自己)相同

2.将两个元素各自所在的集合合在一起,union(A,B)少元素的挂在多元素的底下:

首先一次性把所有数据样本给它,list结构,node结构
优化:任何一次查找某个元素代表集合,在这样的功能中,查找完成后结构改写,找到代表集合之后统一打平,直接接到代表节点:

package zuoshen5;
import java.util.HashMap;
import java.util.List;
public class Code_04_UnionFind {
public static class Node{
}
public static class UnionFindSet{
public HashMapfatherMap;//key:child,value:father
public HashMapsizeMap;//某一个节点所在的集合一共有多少个节点
public UnionFindSet(){
fatherMap=new HashMap();
sizeMap=new HashMap();
}
public void makeSets(Listnodes){
fatherMap.clear();
sizeMap.clear();
for(Node node:nodes){
fatherMap.put(node,node);
sizeMap.put(node,1);
}
}
private Node findHead(Node node){
Node father=fatherMap.get(node);
if(father!=node){
father=findHead(father);
}
fatherMap.put(node,father);
return father;
}
public boolean isSanmeSet(Node a,Node b){
return findHead(a)==findHead(b);
}
public void union(Node a,Node b){
if(a==null ||b==null){
return;
}
Node aHead=findHead(a);
Node bHead=findHead(b);
if(aHead!=bHead){
int aSetSize=sizeMap.get(aHead);
int bSetSize = sizeMap.get(bHead);
if(aSetSize<=bSetSize){
fatherMap.put(aHead,bHead);
sizeMap.put(bHead,aSetSize+bSetSize);
}else {
fatherMap.put(bHead,aHead);
sizeMap.put(aHead,aSetSize+bSetSize);
}
}
}
}
public static void main(String[] args) {
}
}
题目五:岛问题
一个矩阵中只有0和1两种值,每个位置都可以和自己的上、下、左、右 四个位置相连,如果有一片1连在一起,这个部分叫做一个岛,求一个 矩阵中有多少个岛?
举例:
0 0 1 0 1 0 1 1 1 0 1 0 1 0 0 1 0 0 0 0 0 0 0 0
这个矩阵中有三个岛。
分析:合并逻辑,将一个大的矩阵进行块划分,之后合并,通过边界信息进行合并
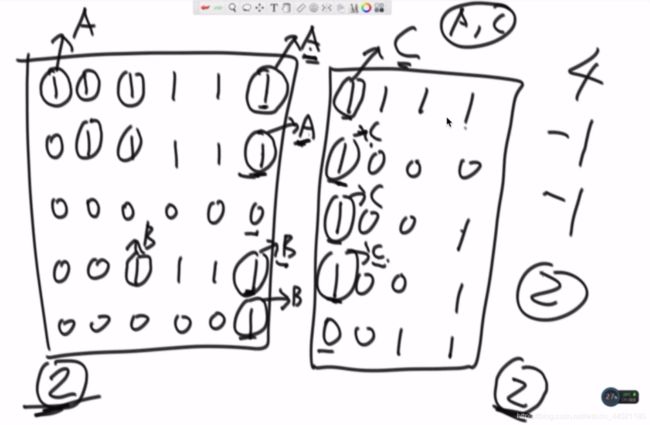
(只需要知道一个块的岛数量信息和这个块的边界信息) 边界,查找第一个A和对应的C是不是一个集合,不是,岛数量-1,第二个A和对应的C是不是一个集合,是,不-1;
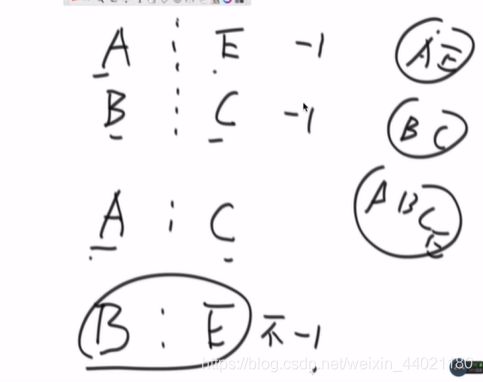
已经合并的不要再减,用并查集最合适。
这里的代码不是合并集的方法,合并集的方法只求了解思想:
package zuoshen5;
public class Code_03_Islands {
public static int countIslands(int[][]m){
if(m==null || m[0]==null){
return 0;
}
int N=m.length;
int M=m[0].length;
int res=0;
for (int i = 0; i =N ||j<0 ||j>=M ||m[i][j]!=1){
return;
}
m[i][j]=2;
infect(m,i+1,j,N,M);
infect(m,i-1,j,N,M);
infect(m,i,j+1,N,M);
infect(m,i,j-1,N,M);
}
public static void main(String[] args) {
int[][] m1 = { { 0, 0, 0, 0, 0, 0, 0, 0, 0 },
{ 0, 1, 1, 1, 0, 1, 1, 1, 0 },
{ 0, 1, 1, 1, 0, 0, 0, 1, 0 },
{ 0, 1, 1, 0, 0, 0, 0, 0, 0 },
{ 0, 0, 0, 0, 0, 1, 1, 0, 0 },
{ 0, 0, 0, 0, 1, 1, 1, 0, 0 },
{ 0, 0, 0, 0, 0, 0, 0, 0, 0 }, };
System.out.println(countIslands(m1));
int[][] m2 = { { 0, 0, 0, 0, 0, 0, 0, 0, 0 },
{ 0, 1, 1, 1, 1, 1, 1, 1, 0 },
{ 0, 1, 1, 1, 0, 0, 0, 1, 0 },
{ 0, 1, 1, 0, 0, 0, 1, 1, 0 },
{ 0, 0, 0, 0, 0, 1, 1, 0, 0 },
{ 0, 0, 0, 0, 1, 1, 1, 0, 0 },
{ 0, 0, 0, 0, 0, 0, 0, 0, 0 }, };
System.out.println(countIslands(m2));
}
}