零样本参考图像分割 ReCLIP: A Strong Zero-Shot Baseline for Referring Expression Comprehension 论文阅读笔记
零样本参考图像分割 ReCLIP: A Strong Zero-Shot Baseline for Referring Expression Comprehension 论文阅读笔记
- 一、Abstract
- 二、引言
- 三、背景
-
- 3.1 问题描述
- 3.2 预训练的模型架构
- 3.3 Colorful Prompt Tuning (CPT)
- 3.4 基于梯度的可视化
- 四、ReCLIP
-
- 4.1 Isolated Proposal Scoring (IPS)
- 4.2 CLIP 能够解析空间关系吗?
- 4.3 空间关系解析器
-
- 主语
- 关系
- 最高级关系
- 语义树
- 五、实验
-
- 5.1 数据集
- 5.2 实施细节
- 5.3 RefCOCO/g/+ 数据集上的结果
- 5.4 RefGTA 数据集上的结果
- 5.5 使用其他的预训练模型
- 5.6 分析
-
- IPS 的性能
- 误差分析和限制
- 六、相关工作
-
- 参考表达式理解
- 预训练的视觉语言模型
- 预训练模型的 Zero-shot 应用
- 七、结论
写在前面
这一周有点事情,一直拖到周六才有时间写篇博文。马上也是毕业季了,祝 前程锦绣~
这篇论文是顺着上一篇博客:零样本参考图像分割 Zero-shot Referring Image Segmentation with Global-Local Context Features 论文笔记 的参考文献顺过来的,随着有监督模型的精度越来越难提高,接下来该转战 Few-shot 和 Zero-shot 了。
- 论文地址:ReCLIP: A Strong Zero-Shot Baseline for Referring Expression Comprehension
- 代码地址:https://github.com/allenai/reclip
- 收录于:ACL 2022
- Ps:2023 年每周一篇博文,主页更多干货,欢迎关注,期待 4 千粉丝有你的参与~
一、Abstract
重新训练一个参考表达式理解模型 referring expression comprehension (ReC) 以适应新的目标域需要收集参考表达式和相应的 bounding boxes(BBox)。虽然大规模预训练模型在其他的目标域上可能会有用,但是以 Zero-shot 的方式应用在 ReC 这类复杂任务上效果不太好。本文提出一种 Zero-shot 模型 ReCLIP 用于 ReC,其中包含一个区域打分方法通过裁剪和模糊来对目标 Proposals 进行打分,还包含一个空间关系解析器用于应对不同的空间关系。在 RefCOCOg、RefGTA 上表现很好。
二、引言
ReC 的定义,意义。指出问题,有监督的 ReC 模型在跨域的表现上不太好,如下图所示:

弱监督 ReC 一定程度上解决了收集数据的问题,但是仍需要一定的参考表示图像对,于是 Zero-shot 出现了。
下面一段对 CLIP 的介绍以及相应的 VQA 模型和 ReC 模型介绍,但是性能不太行。本文提出 ReCLIP,如下图所示:

ReCLIP 主要由两个关键组件组成:使用 CLIP 给目标 Proposal 打分的模块 Isolated Proposal Scoring (IPS),应对目标间的空间关系模块。
在 RefCOCO/g/+、RefGTA 数据集上表现很好。本文贡献总结如下:
- 提出一种 Zero-shot 方法 Re-CLIP 用于 ReC;
- 表明 CLIP 模型在 Zero-shot 的空间推理性能上不太好;
- 实验结果表明 ReCLIP 性能很好。
三、背景
3.1 问题描述
ReC 的定义,目标,评估标准。本文采用 Zero-shot 设置。
3.2 预训练的模型架构
本文采用 CLIP 作为预训练模型,版本为 ResNet-50/ViT-B/32。模型配对图像 i i i 和字幕 j j j 的概率为 exp ( β x i T y j ) ∑ k = 1 N exp ( β x i T y k ) \frac{\exp(\beta\mathrm{x_i}^T\mathrm{y_j})}{\sum_{k=1}^N\exp(\beta\mathrm{x_i}^T\mathrm{y_k})} ∑k=1Nexp(βxiTyk)exp(βxiTyj),其中 β \beta β 为超参数。
3.3 Colorful Prompt Tuning (CPT)
列举一下从 21 年开始的 Prompt 工作。
3.4 基于梯度的可视化
主要是一些 GradCAM 方法,原理: G = M ⊙ ∂ L ∂ M G=M\odot\frac{\partial L}{\partial M} G=M⊙∂M∂L,其中 L L L 为模型的输出 Logits,即图像-文本对的相似度得分, ⊙ \odot ⊙ 表示逐元素乘法。最后计算每个 proposal b i = ( x 1 , y 1 , x 2 , y 2 ) b_i=(x_1,y_1,x_2,y_2) bi=(x1,y1,x2,y2) 的得分 1 A α ∑ i = x 1 x 2 ∑ j = y 1 y 2 G [ i , j ] \frac{1}{A^{\alpha}}\sum_{i=x_1}^{x_2}\sum_{j=y_1}^{y_2}G[i,j] Aα1∑i=x1x2∑j=y1y2G[i,j],其中 A A A 为图像区域, α {\alpha} α 为超参数,于是选择最高得分的 Proposal。
四、ReCLIP
ReCLIP 主要由两个部件组成:不同于 CPT 和 GradCAM 的区域打分方法 Isolated Proposal Scoring (IPS),基于规则的关系解析器。
4.1 Isolated Proposal Scoring (IPS)
设计 IPS 的动机:REC 类似于 CLIP 架构的对比学习任务,只是从选择图像变为选择图像区域了。于是对每一个 Proposal,创建一个新的孤立图像。考虑两种孤立方法:裁剪和模糊:裁剪只包含 Proposal 的图像区域;利用标准偏差为 σ \sigma σ 的高斯模糊除 Proposal 外的区域。将孤立的 Proposal 和表达式穿过预训练模型得到每一 Proposal 分数。分别用 s s c o r e s_{score} sscore 和 s b l u r s_{blur} sblur 为每个区域的裁剪和模糊得分,最后的得分表示为 s s c o r e + s b l u r s_{score}+s_{blur} sscore+sblur,于是选择得分最高的 Proposal。
4.2 CLIP 能够解析空间关系吗?
IPS 的一个关键限制就是不能考虑到不同 proposals 内目标的关系,于是设计实验确定预训练模型是否有这个能力。首先根据 CLEVR 数据集得到一些合成图像,包含三类形状的目标:球体、立方体、圆柱体,8 种颜色:灰、蓝、绿、青、黄、紫、棕、红。随机选择目标间的关系:左、右、前、后,并基于此构建句子框架(一对相反的位置关系对)。实验结果如下表所示:

如上表所示,CLIP 模型并未充分考虑空间关系。
4.3 空间关系解析器
主语
主语词是引用对象必须满足的文本属性。用 P ( i ) P(i) P(i) 表示目标 i i i 满足主语 P P P。将 P P P 视为一个目标类别的分布,利用预训练模型和 ISP 来估计 p ( i ) = Pr [ P ( i ) ] p(i)=\text{Pr}[P(i)] p(i)=Pr[P(i)]
关系
考虑 7 种空间关系:左、右、上、下、更大、更小、内部。用 R ( i , j ) R(i,j) R(i,j) 表示目标 i i i 和 目标 j j j 之间的关系,然后使用启发式来决定概率 r ( i , j ) = Pr [ R ( i , j ) ] r(i,j)=\text{Pr}[R(i,j)] r(i,j)=Pr[R(i,j)],若 box i i i 的中心在 box j j j 中心点的左边,那么 r ( i , j ) = 1 r(i,j)=1 r(i,j)=1,反之 r ( i , j ) = 0 r(i,j)=0 r(i,j)=0。
最高级关系
将最高级关系视为一种特别案例,其中 r ( i , j ) r(i,j) r(i,j) 的第二个参数通过复制指定第一个参数的主语来填充。最高级关系包含上述的普通关系,但是除了 内部。
语义树
首先使用 spaCy 来建立表达式的依赖分析,如下图所示:

然后从依赖分析中提取语义树。其中每个名字块为一个节点,名字块首的依赖路径为所包含的目标实体间关系。当关系/最高级关系都没有出现在表达式中时,则将整个句子送入 IPS 中进行打分。
树上的每个节点 N N N 包含一个主语 P N P_N PN及其子集;节点 N N N 及其子节点 N ′ N^\prime N′ 之间的边 ( N , N ′ ) (N,N^\prime) (N,N′) 对应着关系 R N , N ′ R_{N,N^\prime} RN,N′。定义 π N ( i ) \pi_{N}\left(i\right) πN(i) 为节点 N N N 指向目标 i i i 的概率,进行递归计算。
对于每个节点 N N N,首先设 π N ( i ) = p N ( i ) \pi_{N}\left(i\right)=p_N(i) πN(i)=pN(i),然后通过每个子节点 N ′ N^\prime N′ 和 π N ( i ) \pi_{N}\left(i\right) πN(i) 来更新:
π N ′ ( i ) ∝ π N ( i ) ∑ j P r [ R N , N ′ ( i , j ) ∧ P N ′ ( j ) ] ∝ π N ( i ) ∑ j r N , N ′ ( i , j ) π N ′ ( j ) \begin{gathered} \pi_{N}^{\prime}\left(i\right) \propto\pi_{N}(i)\sum_{j}\mathrm{Pr}\left[R_{N,N^{\prime}}(i,j)\wedge P_{N^{\prime}}(j)\right] \\ \propto\pi_{N}(i)\sum_{j}r_{N,N'}(i,j)\pi_{N'}(j) \end{gathered} πN′(i)∝πN(i)j∑Pr[RN,N′(i,j)∧PN′(j)]∝πN(i)j∑rN,N′(i,j)πN′(j)
为了计算最终输出,通过输出的 IPS 得分与 proposal 概率点乘来得到根节点的分布概率 π r o o t \pi_{root} πroot。
五、实验
5.1 数据集
RefCOCOg、RefCOCO+、RefGTA。
5.2 实施细节
CLIP ResNet-50x16、ViT-B/32, α = 0.5 \alpha=0.5 α=0.5, σ = 100 \sigma=100 σ=100。
5.3 RefCOCO/g/+ 数据集上的结果

5.4 RefGTA 数据集上的结果

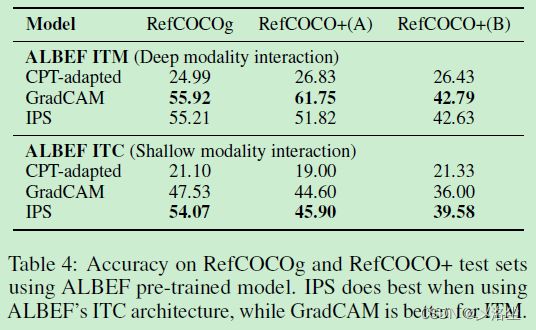
5.5 使用其他的预训练模型

5.6 分析
IPS 的性能


误差分析和限制
图 4 b。限制:计数能力、需要查找多个 Proposal 的关系。
六、相关工作
参考表达式理解
介绍一些数据集,之前的方法,最近的弱监督方法。
预训练的视觉语言模型
以 CLIP 为主的一系列预训练模型。
预训练模型的 Zero-shot 应用
以 CLIP 为主的一系列预训练模型的应用,包含 VQA 等方向。
七、结论
本文提出 ReCLIP 用于 ReC,将表达式分解为多个子序列,采用 IPS 模块给这些子序列及图像打分,结合空间启发式的空间关系解析器。实验表明 ReCLIP 的效果很好,还表明 CLIP 的空间推理性能不太好,所以需要考虑预训练模型的空间推理能力。
写在后面
附录里面还有一些有趣的东东,留给读者来探索一番吧~