6.Hadoop之源码解析
内容过于繁杂,建议去看尚硅谷hadoop官方视频和笔记
视频:https://www.bilibili.com/video/BV1Qp4y1n7EN?spm_id_from=333.337.search-card.all.click
笔记和其余文件:链接:https://pan.baidu.com/s/10iGIiUuFV5JaOhozUvoNcQ 提取码:fgnd
0.RPC 通信原理解析
0)回顾
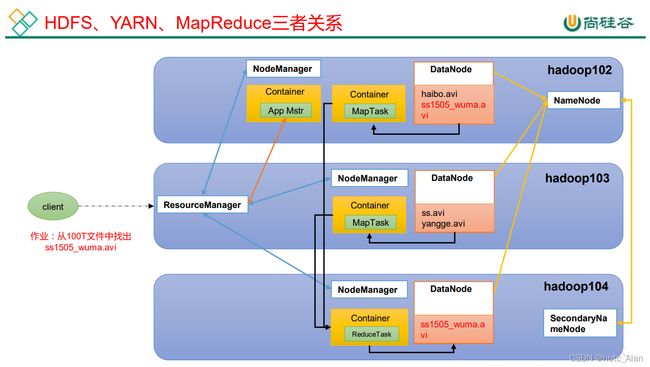
1)需求:
模拟 RPC 的客户端、服务端、通信协议三者如何工作的

2)代码编写:
(1)在 HDFSClient 项目基础上创建包名 com.atguigu.rpc
(2)创建 RPC 协议
public interface RPCProtocol {
long versionID = 666;
void mkdirs(String path);
}
(3)创建 RPC 服务端
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.ipc.RPC;
import org.apache.hadoop.ipc.Server;
import java.io.IOException;
public class NNServer implements RPCProtocol{
@Override
public void mkdirs(String path) {
System.out.println("服务端,创建路径" + path);
}
public static void main(String[] args) throws IOException {
Server server = new RPC.Builder(new Configuration())
.setBindAddress("localhost")
.setPort(8888)
.setProtocol(RPCProtocol.class)
.setInstance(new NNServer())
.build();
System.out.println("服务器开始工作");
server.start();
}
}
(4)创建 RPC 客户端
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.ipc.RPC;
import java.io.IOException;
import java.net.InetSocketAddress;
public class HDFSClient {
public static void main(String[] args) throws IOException {
RPCProtocol client = RPC.getProxy(
RPCProtocol.class,
RPCProtocol.versionID,
new InetSocketAddress("localhost", 8888),
new Configuration());
System.out.println("我是客户端");
client.mkdirs("/input");
}
}
3)测试
(1)启动服务端
观察控制台打印:服务器开始工作
在控制台 Terminal 窗口输入,jps,查看到 NNServer 服务
(2)启动客户端
观察客户端控制台打印:我是客户端
观察服务端控制台打印:服务端,创建路径/input
4)总结
RPC 的客户端调用通信协议方法,方法的执行在服务端;
通信协议就是接口规范。
1.NameNode 启动源码解析

0)在 pom.xml 中增加如下依赖
org.apache.hadoop
hadoop-client
3.1.3
org.apache.hadoop
hadoop-hdfs
3.1.3
org.apache.hadoop
hadoop-hdfs-client
3.1.3
provided
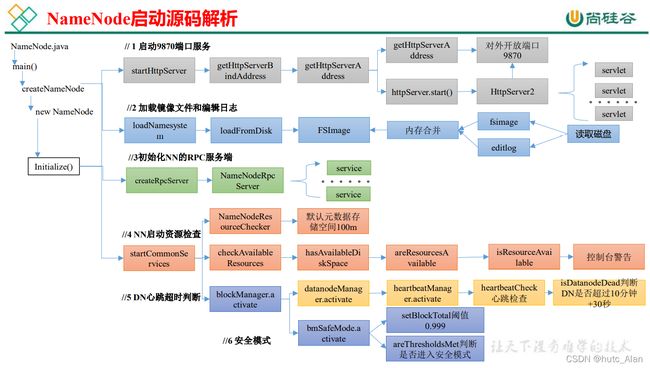
1)ctrl + n 全局查找 namenode,进入 NameNode.java
2)ctrl + f,查找 main 方法
点击 createNameNode
点击 initialize
1.1 启动 9870 端口服务
1)点击 startHttpServer
NameNode.java
2)点击 startHttpServer 方法中的 httpServer.start();
NameNodeHttpServer.java
点击 setupServlets
1.2 加载镜像文件和编辑日志
1)点击 loadNamesystem
NameNode.java
1.3 初始化 NN 的 RPC 服务端
1)点击 createRpcServer
NameNode.java
NameNodeRpcServer.java
1.4 NN 启动资源检查
1)点击 startCommonServices
NameNode.java
2)点击 startCommonServices
FSNamesystem.java
点击 NameNodeResourceChecker
NameNodeResourceChecker.java
点击 checkAvailableResources
FNNamesystem.java
NameNodeResourceChecker.java
NameNodeResourcePolicy.java
ctrl + h,查找实现类 CheckedVolume
NameNodeResourceChecker.java
1.5 NN 对心跳超时判断
Ctrl + n 搜索 namenode,ctrl + f 搜索 startCommonServices
点击 namesystem.startCommonServices(conf, haContext);
点击 blockManager.activate(conf, completeBlocksTotal);
点击 datanodeManager.activate(conf);
DatanodeManager.java
DatanodeManager.java
1.6 安全模式
FSNamesystem.java
点击 getCompleteBlocksTotal
点击 activate
点击 activate
点击 setBlockTotal
点击 areThresholdsMet
2.DataNode 启动源码解析

org.apache.hadoop
hadoop-client
3.1.3
org.apache.hadoop
hadoop-hdfs
3.1.3
org.apache.hadoop
hadoop-hdfs-client
3.1.3
provided
1)ctrl + n 全局查找 datanode,进入 DataNode.java
DataNode 官方说明
2)ctrl + f,查找 main 方法
DataNode.java
2.1 初始化 DataXceiverServer
点击 initDataXceiver
2.2 初始化 HTTP 服务
点击 startInfoServer();
DataNode.java
DatanodeHttpServer.java
2.3 初始化 DN 的 RPC 服务端
点击 initIpcServer
DataNode.java
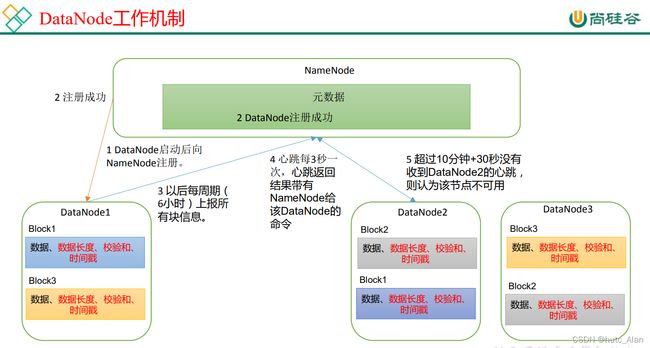
2.4 DN 向 NN 注册
点击 refreshNamenodes
BlockPoolManager.java
点击 startAll()
点击 start ()
BPOfferService.java
点击 start ()
BPServiceActor.java
ctrl + f 搜索 run 方法
DatanodeProtocolClientSideTranslatorPB.java
点击 register
BPServiceActor.java
ctrl + n 搜索 NameNodeRpcServer
NameNodeRpcServer.java
ctrl + f 在 NameNodeRpcServer.java 中搜索 registerDatanode
FSNamesystem.java
BlockManager.java
2.5 向 NN 发送心跳
点击 BPServiceActor.java 中的 run 方法中的 offerService 方法
BPServiceActor.java
ctrl + n 搜索 NameNodeRpcServer
NameNodeRpcServer.java
ctrl + f 在 NameNodeRpcServer.java 中搜索 sendHeartbeat
点击 handleHeartbeat
DatanodeManager.java
HeartbeatManager.java
BlockManager.java
DatanodeDescriptor.java
3.HDFS 上传源码解析
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-LVtbV44T-1649085604907)(https://note.youdao.com/yws/res/6700/WEBRESOURCE39074ed0d95145fe6192ae7b7402156c)]
org.apache.hadoop
hadoop-client
3.1.3
org.apache.hadoop
hadoop-hdfs
3.1.3
org.apache.hadoop
hadoop-hdfs-client
3.1.3
provided
junit
junit
4.12
org.slf4j
slf4j-log4j12
1.7.30
3.1.1 DN 向 NN 发起创建请求
用户自己写的代码
@Test
public void testPut2() throws IOException {
FSDataOutputStream fos = fs.create(new Path("/input"));
fos.write("hello world".getBytes());
}
点create
FileSystem.java
选中 create,点击 ctrl+h,找到实现类 DistributedFileSystem.java,查找 create 方法。
DistributedFileSystem.java
点击 create,进入 DFSClient.java
点击 newStreamForCreate,进入 DFSOutputStream.java
3.1.2 NN 处理 DN 的创建请求
1)点击 create
ClientProtocol.java
2)Ctrl + h 查找 create 实现类,点击 NameNodeRpcServer,在 NameNodeRpcServer.java 中搜索 create
NameNodeRpcServer.java
FSNamesystem.java
3.1.3 DataStreamer 启动流程
NN 处理完 DN 请求后,再次回到 DN 端,启动对应的线程
DFSOutputStream.java
点击 DFSOutputStream
1)点击 newStreamForCreate 方法中的 out.start(),进入 DFSOutputStream.java
点击 DataStreamer,进入 DataStreamer.java
点击 Daemon,进入 Daemon.java
说明:out.start();实际是开启线程,点击 DataStreamer,搜索 run 方法
DataStreamer.java
3.2 write 上传过程
3.1.1 向 DataStreamer 的队列里面写数据
1)用户写的代码
@Test
public void testPut2() throws IOException {
FSDataOutputStream fos = fs.create(new Path("/input"));
fos.write("hello world".getBytes());
}
2)点击 write
FilterOutputStream.java
3)点击 write
OutputStream.java
ctrl + h 查找 write 实现类,选择 FSOutputSummer.java,在该类中查找 write
FSOutputSummer.java
ctrl + h 查找 writeChunk 实现类 DFSOutputStream.java
DataStreamer.java
3.1.2 建立管道之机架感知(块存储位置)
Ctrl + n 全局查找 DataStreamer,搜索 run 方法
DataStreamer.java
点击 nextBlockOutputStream
ctrl + h 点击 NameNodeRpcServer,在该类中搜索 addBlock
NameNodeRpcServer.java
FSNamesystrm.java
Crtl + h 查找 chooseTarget 实现类 BlockPlacementPolicyDefault.java
3.1.3 建立管道之 Socket 发送
点击 nextBlockOutputStream
3.1.4 建立管道之 Socket 接收
Ctrl +n 全局查找 DataXceiverServer.java,在该类中查找 run 方法
点击 DataXceiver(线程),查找 run 方法
Ctrl +alt +b 查找 writeBlock 的实现类 DataXceiver.java
3.1.5 客户端接收 DN 写数据应答 Response
Ctrl + n 全局查找 DataStreamer,搜索 run 方法
DataStreamer.java
点击 response 再点击 ResponseProcessor,ctrl + f 查找 run 方法
4.Yarn 源码解析

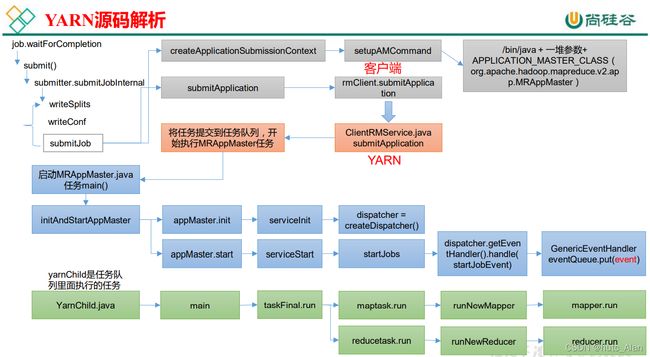
4.1 Yarn 客户端向 RM 提交作业
1)在 wordcount 程序的驱动类中点击
Job.java
点击 submitJobInternal()
JobSubmitter.java
2)创建提交环境
ctrl + alt +B 查找 submitJob 实现类,YARNRunner.java
3)向 Yarn 提交
点击 submitJob 方法中的 submitApplication()
YARNRunner.java
ctrl + alt +B 查找 submitApplication 实现类,YarnClientImpl.java
ctrl + alt +B 查找 submitApplication 实现类,ClientRMService.java
4.2 RM 启动 MRAppMaster
0)在 pom.xml 中增加如下依赖
org.apache.hadoop
hadoop-mapreduce-client-app
3.1.3
ctrl +n 查找 MRAppMaster,搜索 main 方法
ctrl + alt +B 查找 serviceInit 实现类,MRAppMaster.java
点击 MRAppMaster.java 中的 initAndStartAppMaster 方法中的 appMaster.start();
ctrl + alt +B 查找 handle 实现类,GenericEventHandler.java
4.3 调度器任务执行(YarnChild)
1)启动 MapTask
ctrl +n 查找 YarnChild,搜索 main 方法
ctrl + alt +B 查找 run 实现类,maptask.java
Mapper.java(和 Map 联系在一起)
2)启动 ReduceTask
在 YarnChild.java 类中的 main 方法中 ctrl + alt +B 查找 run 实现类,reducetask.java
Reduce.java
5.MapReduce 源码解析
说明:在讲 MapReduce 课程时,已经讲过源码,在这就不再赘述。
5.1 Job 提交流程源码和切片源码详解
1)Job 提交流程源码详解
waitForCompletion()
submit();
// 1 建立连接
connect();
// 1)创建提交 Job 的代理
new Cluster(getConfiguration());
// (1)判断是本地运行环境还是 yarn 集群运行环境
initialize(jobTrackAddr, conf);
// 2 提交 job
submitter.submitJobInternal(Job.this, cluster)
// 1)创建给集群提交数据的 Stag 路径
Path jobStagingArea = JobSubmissionFiles.getStagingDir(cluster, conf);
// 2)获取 jobid ,并创建 Job 路径
JobID jobId = submitClient.getNewJobID();
// 3)拷贝 jar 包到集群
copyAndConfigureFiles(job, submitJobDir);
rUploader.uploadFiles(job, jobSubmitDir);
// 4)计算切片,生成切片规划文件
writeSplits(job, submitJobDir);
maps = writeNewSplits(job, jobSubmitDir);
input.getSplits(job);
// 5)向 Stag 路径写 XML 配置文件
writeConf(conf, submitJobFile);
conf.writeXml(out);
// 6)提交 Job,返回提交状态
status = submitClient.submitJob(jobId, submitJobDir.toString(),
job.getCredentials());
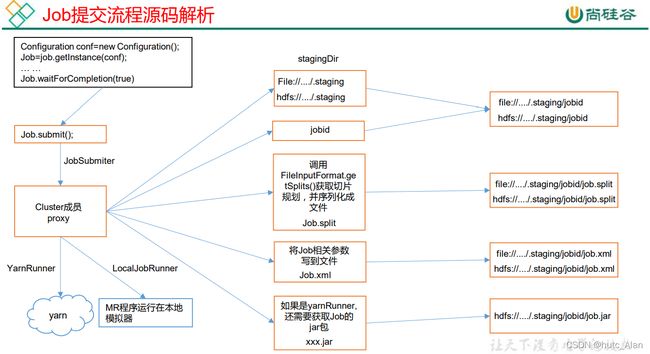
2)FileInputFormat 切片源码解析(input.getSplits(job))

5.2 MapTask & ReduceTask 源码解析
1)MapTask 源码解析流程
=================== MapTask ===================
context.write(k, NullWritable.get()); //自定义的 map 方法的写出,进入
output.write(key, value);
//MapTask727 行,收集方法,进入两次
collector.collect(key, value,partitioner.getPartition(key, value, partitions));
HashPartitioner(); //默认分区器
collect() //MapTask1082 行 map 端所有的 kv 全部写出后会走下面的 close 方法
close() //MapTask732 行
collector.flush() // 溢出刷写方法,MapTask735 行,提前打个断点,进入
sortAndSpill() //溢写排序,MapTask1505 行,进入
sorter.sort() QuickSort //溢写排序方法,MapTask1625 行,进入
mergeParts(); //合并文件,MapTask1527 行,进入
collector.close(); //MapTask739 行,收集器关闭,即将进入 ReduceTask
2)ReduceTask 源码解析流程
=================== ReduceTask ===================
if (isMapOrReduce()) //reduceTask324 行,提前打断点
initialize() // reduceTask333 行,进入
init(shuffleContext); // reduceTask375 行,走到这需要先给下面的打断点
totalMaps = job.getNumMapTasks(); // ShuffleSchedulerImpl 第 120 行,提前打断点
merger = createMergeManager(context); //合并方法,Shuffle 第 80 行
// MergeManagerImpl 第 232 235 行,提前打断点
this.inMemoryMerger = createInMemoryMerger(); //内存合并
this.onDiskMerger = new OnDiskMerger(this); //磁盘合并
rIter = shuffleConsumerPlugin.run();
eventFetcher.start(); //开始抓取数据,Shuffle 第 107 行,提前打断点
eventFetcher.shutDown(); //抓取结束,Shuffle 第 141 行,提前打断点
copyPhase.complete(); //copy 阶段完成,Shuffle 第 151 行
taskStatus.setPhase(TaskStatus.Phase.SORT); //开始排序阶段,Shuffle 第 152 行
sortPhase.complete(); //排序阶段完成,即将进入 reduce 阶段 reduceTask382 行
reduce(); //reduce 阶段调用的就是我们自定义的 reduce 方法,会被调用多次
cleanup(context); //reduce 完成之前,会最后调用一次 Reducer 里面的 cleanup 方法
6.Hadoop 源码编译
6.1 前期准备工作
1)官网下载源码
https://hadoop.apache.org/release/3.1.3.html
2)修改源码中的 HDFS 副本数的设置
3)CentOS 虚拟机准备
(1)CentOS 联网
配置 CentOS 能连接外网。Linux 虚拟机 ping www.baidu.com 是畅通的
注意:采用 root 角色编译,减少文件夹权限出现问题
(2)Jar 包准备(Hadoop 源码、JDK8、Maven、Ant 、Protobuf)
- hadoop-3.1.3-src.tar.gz
- jdk-8u212-linux-x64.tar.gz
- apache-maven-3.6.3-bin.tar.gz
- protobuf-2.5.0.tar.gz(序列化的框架)
- cmake-3.17.0.tar.gz
6.2 工具包安装
注意:所有操作必须在 root 用户下完成
0)分别创建/opt/software/hadoop_source 和/opt/module/hadoop_source 路径
1)上传软件包到指定的目录,例如 /opt/software/hadoop_source
2)解压软件包指定的目录,例如: /opt/module/hadoop_source
3)安装 JDK
(1)解压 JDK
$ tar -zxvf jdk-8u212-linux-x64.tar.gz -C /opt/module/hadoop_source/
(2)配置环境变量
$ vim /etc/profile.d/my_env.sh
输入如下内容:
#JAVA_HOME
export JAVA_HOME=/opt/module/hadoop_source/jdk1.8.0_212
export PATH=$PATH:$JAVA_HOME/bin
(3)刷新 JDK 环境变量
$ source /etc/profile
(4)验证 JDK 是否安装成功
$ java -version
4)配置 maven 环境变量,maven 镜像,并验证
(1)配置 maven 的环境变量
$ vim /etc/profile.d/my_env.sh
#MAVEN_HOME
MAVEN_HOME=/opt/module/hadoop_source/apache-maven-3.6.3
PATH=$PATH:$JAVA_HOME/bin:$MAVEN_HOME/bin
$ source /etc/profile
(2)修改 maven 的镜像
$ vim conf/settings.xml
# 在 mirrors 节点中添加阿里云镜像
<mirrors>
<mirror>
<id>nexus-aliyun</id>
<mirrorOf>central</mirrorOf>
<name>Nexus aliyun</name>
<url>http://maven.aliyun.com/nexus/content/groups/public</url>
</mirror>
</mirrors>
(3)验证 maven 安装是否成功
$ mvn -version
5)安装相关的依赖(注意安装顺序不可乱,可能会出现依赖找不到问题)
(1)安装 gcc make
$ yum install -y gcc* make
(2)安装压缩工具
$ yum -y install snappy* bzip2* lzo* zlib* lz4* gzip*
(3)安装一些基本工具
$ yum -y install openssl* svn ncurses* autoconf automake libtool
(4)安装扩展源,才可安装 zstd
$ yum -y install epel-release
(5)安装 zstd
$ yum -y install *zstd*
6)手动安装 cmake
(1)在解压好的 cmake 目录下,执行./bootstrap 进行编译,此过程需一小时请耐心等待
$ pwd
/opt/module/hadoop_source/cmake-3.17.0
$ ./bootstrap
(2)执行安装
$ make && make install
(3)验证安装是否成功
$ cmake -version
7)安装 protobuf,进入到解压后的 protobuf 目录
$ pwd
/opt/module/hadoop_source/protobuf-2.5.0
(1)依次执行下列命令 --prefix 指定安装到当前目录
$ ./configure --prefix=/opt/module/hadoop_source/protobuf-2.5.0
$ make && make install
(2)配置环境变量
$ vim /etc/profile.d/my_env.sh
输入如下内容
PROTOC_HOME=/opt/module/hadoop_source/protobuf-2.5.0
PATH=$PATH:$JAVA_HOME/bin:$MAVEN_HOME/bin:$PROTOC_HOME/bin
(3)验证
$ source /etc/profile
$ protoc --version
libprotoc 2.5.0
8)到此,软件包安装配置工作完成。
6.3 编译源码
1)进入解压后的 Hadoop 源码目录下
$ pwd
/opt/module/hadoop_source/hadoop-3.1.3-src
$ mvn clean package -DskipTests -Pdist,native -Dtar
注意:第一次编译需要下载很多依赖 jar 包,编译时间会很久,预计 1 小时左右
2)成功的 64 位 hadoop 包在/opt/module/hadoop_source/hadoop-3.1.3-src/hadoop-dist/target 下