DSIN(Deep Session Interest Network)详解
1. 提出动机
这个模型依然是研究如何更好地从用户的历史行为中捕捉到用户的动态兴趣演化规律。DIEN存在一个问题,就是只关注了如何去改进网络,而忽略了用户历史行为序列本身的特点,我们仔细去想,用户过去可能有很多历史点击行为,比如[]item3,item45,item69,item21,...],这个按照用户的点击时间排好序了,既然我们说用户的兴趣是非常广泛且多变的,那么这一大串序列的商品中,往往出现的一个规律就是再比较短的时间间隔内的商品往往会很相似,时间间隔长了之后,商品之间就会出现很大的差别,这个是很容易理解的,一个用户再半个小时之内的浏览点击的几个商品的相似度和一个用户上午点击和晚上点击的商品的相似度很可能是不一样的。这其实就是作者所说的homogeneous和heterogeneous.而DIEN模型,它并没有考虑这个问题,而是会直接把一大串行为序列放入GRU让它自己去学,如果一大串序列一块让GRU学习的话,往往用户的行为快速改变和突然终止的序列会有很多噪声点,不利于模型的学习。
所以,作者这里就是从序列本身的特点出发,把一个用户的行为序列分成了多个会话,所谓会话,其实就是按照时间间隔把序列分段,每一段的商品列表就是一个会话,那这时候,会话里面每个商品之间的相似度就比较大了,而会话与会话之间商品相似度就可能比较小。这就是DSIN改进的动机了,主要是再S上。
DSIN模型的整体逻辑为:
1.首先,分段是必须的,也就是用户行为序列输入到模型之前,要按照固定的时间间隔(比如30分钟)给他分开段,每一段里面的商品序列称为一个会话session,这个叫做会话划分层。
2.然后,就是学习商品时间的依赖关系或者序列关系,由于上面把一个整的行为序列划分成了多段,那么再这里就是每一段的商品时间的序列关系要进行学习,当然我们说可以用GRU,不过这里作者用了多头的注意力机制,这个东西是在多个角度研究一个会话里面各个商品的关联关系,相比GRU来讲,没有啥梯度消失,并且可以并行计算,比GRU更加强大。这个叫做会话兴趣提取层。
3.上面研究了会话内各个商品之间的关联关系,接下来就是研究会话与会话之间的关系了,虽然我们说各个会话之间的关联性貌似不太大,但是别忘了会话可以能够表示一段时间内用户兴趣的,所以研究会话与会话的关系其实就是再学习用户兴趣的变化规律,这里用了双向的LSTM,不仅看从现在到未来的兴趣演化,还能学习未来到现在的变化规律,这个叫做会话交互层。
4.既然会话内各个商品之间的关系学到了,会话与会话之间的关系学习了,然后呢?当然也是针对性的模拟与目标广告相关的兴趣进化路径了,所以后面是会话兴趣局部激活层,这个就是注意力机制,每次关注与当前商品更相关的兴趣。
2. DSIN的架构剖析
先放上DSIN的模型结构图。

DSIN的两个目的对应着本模型最核心的两个层(会话兴趣提取层和会话交互层)
2.1 Session Division Layer
这一层是将用户的行为序列进行切分,首先将用户的点击行为按照时间排序,判断两个行为之间的时间间隔,如果前后间隔大于30min,就进行切分,具体的时间间隔根据自己的业务场景来。
划分完了之后,我们就把一个行为序列S转成了Sessions Q,比如行为序列切分成了4个会话,会分别用Q1,Q2,Q3,Q4表示。第k个会话Qk中,又包含了T个行为,即
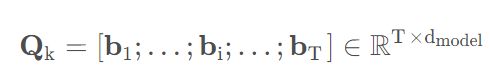
bi表示的是第k个会话里面的第i个点击行为(具体的item),这个东西是一个 ������ 维的embedding向量。所以Qk是一个 �∗������ 维的。而整个大Q,就是一个 �∗�∗������ 维的矩阵。这里的K指的是session的个数。但是要注意,这个层是在每个embedding 层之后的,也就是各个商品转成了embedding向量之后,我们再进行切割。
2.2 Session Interest Extractor Layer
这个层是学习每个会话中各个行为之间的关系,之前分析过,在同一个会话中的各个商品的相关性是非常大的。此外,作者这里还提到,用户的随意的那种点击行为会偏离用户当前会话兴趣的表达,所以为了捕获同一会话中行为之间的内在关系,同时降低这些不相关行为的影响,这里采用了multi-head self-attention.这个东西,在这里不再详细说明,具体可以我整理的transformer的文章,这里给出核心的图。
第一个是transformer编码器的一小块。
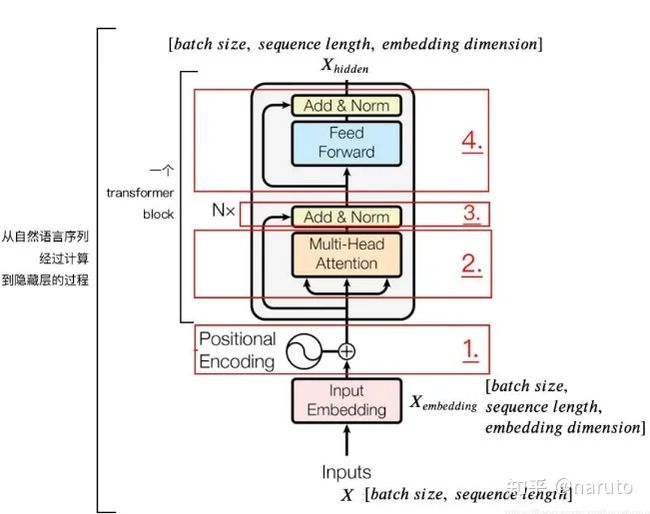
DSIN结构的第二层,其实就是这个东西。这个东西整体的计算过程,如下图。
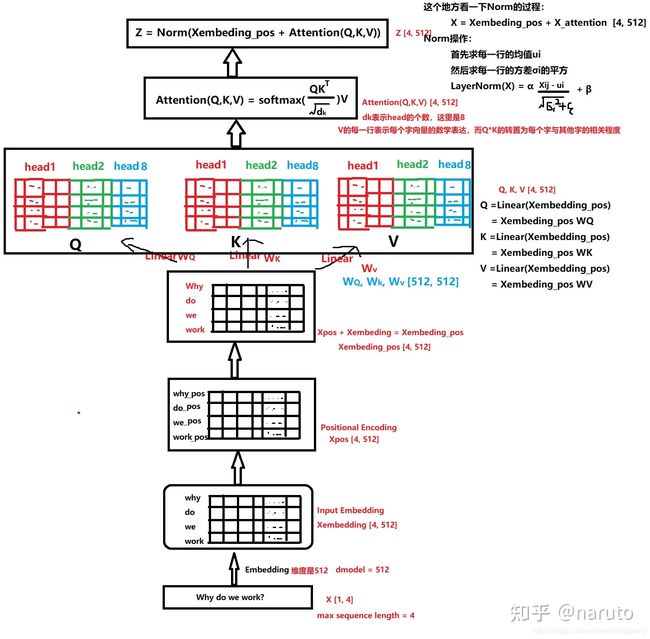
这一块其实是分两步,第一步叫做位置编码,而第二步就是self-attention计算关联。同样,DSIN中也是这两步,只不过第一步的位置编码,作者这里做了点改进,称为Bias Encoding。具体来看下做法。
这里还是再解释下为啥要进行位置编码或者Bias Encoding。这是因为我们说self-attention机制是要学习会话里面各个商品之间的关系
的,而商品我们知道是一个按照时间排好的小序列,由于后面的self-attention并没有循环神经网络的迭代计算,所以我们必须提供
每个字的位置信息给后面的self-attention,这个后面self-attention的输出结果才能蕴含商品之间的顺序信息。在Transformer中,对输入的序列会进行Positional Encoding。具体处理方式就不再列了,依旧看我整理的Transformer的文章。
而这里,作者做了些改造,这是因为在这里还需要考虑各个会话之间的位置信息,毕竟这里是多个会话,并且各个会话之间也是又位置顺序的呀,所以还需要对每个会话添加一个Positional Encoding,在DSIN中,这种对位置的处理,称为Bias Encoding.
于是乎作者在这里提出了个 ��∈��∗�∗������ ,这个东西的具体计算如下。
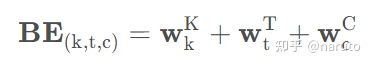
BE(k,t,c)表示的第k个会话中,第t个物品在第c维度这个位置上的偏置项(是一个数),其中 ��∈�� 表示的会话层次的偏置项(位置信息)。如果有n个样本的话,这个应该是[n,K,1,1]的矩阵,后面两个维度表示的T和emb_dim。 ��∈�� 这个是在会话里面时间位置层次上的偏置项(位置信息),这个应该是[n,1,T,1]的矩阵。 ��∈������� 这个是embedding维度层析上的偏置(位置信息),这个应该是[n,1,1,d_model]的矩阵。而上面的 ���,���,��� 都是表示某个维度上的具体的数字,所以BE(k,t,c)是一个数。
所以BE就是一个[n,K,T,d_model]的矩阵,蕴含了每个会话,每个物品,每个embedding位置的位置信息,所以经过Bias编码之后,得到的结果如下:
Q=Q+BE
这个Q的维度是[n,K,T,d_model],当然这里我们先不考虑样本个数,所以是[K,T,d_model].相比Transformer,这里多出一个会话的维度来。
接下来,就是每个会话的序列都通过Transformer进行处理。

一定要注意,这里说的是每个会话,就是每个Qi都会走这个自注意力机制,因为我们算的是某个会话当中各个物品之间的关系。这里我们就拿一个会话来解释。
首先Q1是一个T*embed_dim的一个矩阵。
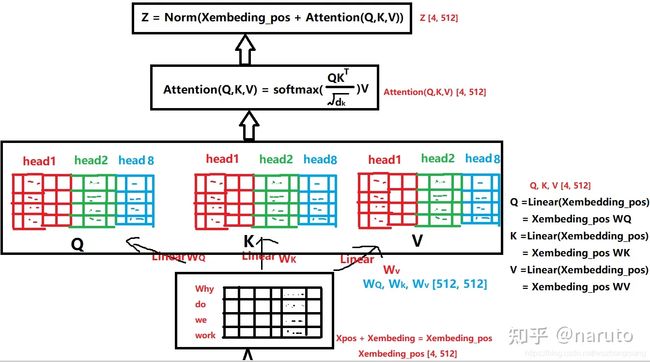
然后就是进入上图这样一个多头的自注意力机制中,能够得到当前的商品与其他商品在多个角度上的相关性。


即这个I_k是一个embedding维度的向量,表示当前用户在第k会话的兴趣。这就是一个会话里面兴趣提取的全过程。
接下来就是不同的会话都走这样的一个Transformer网络,就会得到一个K*embed_dim的矩阵,代表的是某个用户在K个会话里面的兴趣信息,这个就是会话兴趣提取层的结果了。两个注意点:
1.这K个会话是走同一个Transformer网络的,也就是在自注意力机制中不同的会话之间权重共享
2.最后得到的这个矩阵,K这个维度上是有时间先后顺序的,这为后面用LSTM学习各个会话之间的兴趣向量奠定了基础。
2.3 Session Interest Interacting Layer
作者这里想用一个双向的LSTM来学习下会话兴趣之间的关系,从而增加用户兴趣的丰富度,或者还能学习到演化规律。
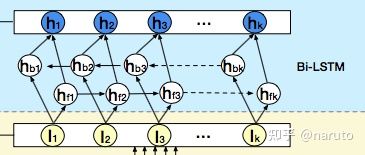
双向的LSTM就是从头学到尾,再从尾到头回来。所以这里每个时刻隐藏状态的输出计算公式为:
这是一个[1,#hidden_units]的维度。相加的两项分别是前向传播和反向传播对应的t时刻的Hidden state,这里得到的隐藏状态Ht,我们可以认为混合了上下文信息的会话兴趣。
2.4 Session Interest Activating Layer
用户的会话兴趣与目标物品越相近,那么应该赋予更大的权重,这里依然使用注意力机制来刻画这种相关性,根据结构图能看出,这里用了两波注意力计算。
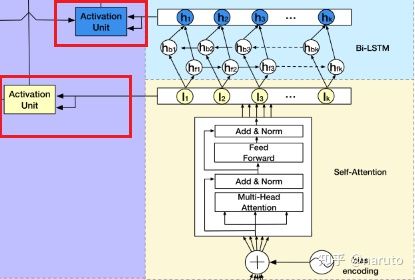
这里的局部attention机制,就不再详细介绍了,之前DIN和DIEN都见过。
1.会话兴趣提取层

2.会话兴趣交互层

2.5 输出层
上面的用户行为特征,物品行为特征以及求出的会话兴趣特征进行拼接,然后过一个DNN网络,就可以得到输出了。

损失这里依然使用交叉熵损失:
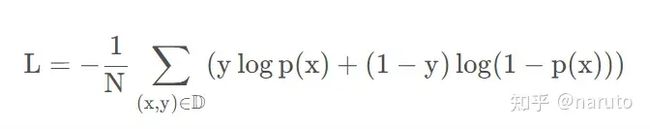
这里的x表示的是[X^U, X^I, S],分别表示用户特征,物品特征和会话兴趣特征
DSIN最大改进点:划分行为序列得到会话;会话内部用户兴趣提取借鉴了nlp领域的transformer,利用多头注意力机制进行兴趣提取。
https://zhongqiang.blog.csdn.net/article/details/114500619
https://arxiv.org/pdf/1905.0648