抓到一只Linux小白白——生产队有没有驴,我说的算
工欲善其事,必先利其器。生产队有没有驴,我说的算。
看!那人在用Linux
抓到一只Linux小白白
生产队有没有驴,我说的算
文章目录
- 前言
- 第一章 Linux‘s Mr.Knowall
-
- 一 man命令
- 二 whatis命令
- 第二章 Vim文本编辑器
-
- 一 VI基础
-
- .1 vi指令特性
- .2 打开和关闭文件
- .3 退出和保存命令
- .4 初学者错误
- .5 vi的两种工作模式
- .6 没什么用的命令ZZ
- .7 清空及undo、redo
- .8 将文件另存为
- .9 小技巧,多线程
- .10 移动光标所在位置
-
- .10.1 基础光标移动命令
- .10.2 按字移动
- .10.3 移动到指定行
- .10.4 Moving Hurry
- 10.5 重置光标行位置
- 10.6 在页面内移动光标的方法
- 10.7 按行移动
- 10.8 按字块移动
- .11 显示行号
- .12 插入操作
-
- .12.1 Append
- .12.2 Insert
- .12.3 Substitute
- 12.4 Open
- .12.5 带参数的插入
- .13 删除复制粘贴
-
- .13.1 对行的操作
- .13.2 Delete
- .13.3 Change
- .13.4 Replace
- .13.5 对单个英文字母的操作
- .14 搜索
-
- .14.1 下一个
- .14.2 行内搜索
- 14.3 组合操作
- .15 显示文件信息
- .16 G移动命令
- .17 拷贝到缓冲区
- .18 书签
- 二 使用vimtags插件与ctags配合浏览源码
- 第三章 bash/sh与Linux基础命令
-
- 一 背景知识
-
- 1. *Nix软件工具原则
- 2. 两个"偷窥"命令
- 二 Shell脚本入门及Linux基础命令
-
- 1. 什么是脚本
-
- .1.1 脚本注释
- .1.2 选择脚本执行程序
- .1.3 Linux 文件属性及用户权限
- .1.4. 输入输出命令
- .1.5 输入输出重定向
- .1.6 进程和管道
- 2. 脚本的变量和参数
-
- .2.1 变量
- .2.2 参数及处理
- .2.3 数组
- .2.4 运算符
- .2.5 test
- 三 bash脚本调试技术
-
- 1. tee调试管道
- 2. 使用命令解析器的参数
- 3. shell内置环境变量LINENO
- 4. shell内置环境变量FUNCNAME
- 5. shell内置环境变量PS4
- 6. trap
- 附:练手脚本示例
-
- 1. 通过file命令遍历目录
- 2. sed批量修改
- 3. 使用Linux自带随机数生成器
前言
在软件行业,Linux做为生产力工具和Windows、IOS处于同样地位。我们要理解并掌握相关知识才能提升生产力。其中shell编程在unix/linux世界中使用得非常广泛,熟练掌握shell编程也是成为一名优秀的unix/linux开发者和系统管理员的必经之路。在了解Linux之前先了解几个概念:
- Linux命令 命令是用于对Linux系统进行管理的可执行文件。所有的Linux上运行的软件都有对应的linux命令。
- 文件 文件是Linux的核心,Linux认为是一切皆文件。对于Linux系统来说,无论是中央处理器、内存、磁盘驱动器、键盘、鼠标,还是用户等都是文件(部分linux组件,比如网络,有自己的实现现实标准。因此,这类特殊组件,在文件的读、写、查接口上增加了其它接口)。
- 命令解析器Shell 又称之为终端、伪终端、控制台、shell,用于对输入的Linux命令进行解析,交由操作系统执行响应的管理动作。虽然这一组概念我们经常混着用,但其实各自的含义稍有不同。在《关于Unix/Linux的终端、伪终端、控制台和shell》一文中,作者详细介绍了它们的概念及历史渊源。
在*NIX系列(指的是UNIX和Linux以及FreeBSD等以UNIX为原型的操作系统)操作系统发行版的具体使用中,有很多个不同的Shell版本。但其实包括bash、zsh、csh在内的各种Shell都源于最初的sh。
第一章 Linux‘s Mr.Knowall
我们在学习Linux 命令的过程中总会遇到各种各样的问题,这时,有两个Linux命令可以帮助我们了解Linux命令。(本文在Windows 10的WSL Ubuntu子系统下运行所有的脚本和命令)
Ubuntu子系统的安装,参考《抓到一只Linux小白白之Ubuntu初体验》。现在,在Windows 10的程序中搜索Ubuntu,运行Ubuntu子系统,让我们开始学习吧~
一 man命令
第一个你需要知道的Linux命令就是man命令,该命令可以显示指定命令、API的用法和描述。man文档默认的阅读工具是less(可以逐页、逐行查看文本的工具)。我们看一下man的自己的说明:
man man

man文档的显示内容通常由一下几个部分组成:
- 标题:[NAME(即man所查询的命令或API等,统称为NAME)][文档分类] [文档类型描述] [NAME][文档分类], e.g. man(1) Manual pager utils man (1),表明是man在文档分类为1中的帮助文档,它是“ Manual pager utils”
- SYNOPSIS:罗列NAME的所有选项用法。
- DESCRIPTION:NAME用途的详细介绍。
- EXAMPLES:范例
- OPTIONS:参数详细介绍
- 其它组成部分:OVERVIEW、DEFAULTS、EXIT STATUS、ENVIRONMENT、SEE ALSO等
由于在Linux中同一个NAME可能是命令,也可能是一种API,所以man对文档进行了分类以便查询。man文档一共有9种类别,按照man文档的介绍,它们分别为:
| 分类号 | 说明 |
|---|---|
| 1 | Executable programs or shell commands |
| 2 | System calls (functions provided by the kernel) |
| 3 | Library calls (functions within program libraries) |
| 4 | Special files (usually found in /dev) |
| 5 | File formats and conventions eg /etc/passwd |
| 6 | Games |
| 7 | Miscellaneous (including macro packages and conventions), e.g. man(7), groff(7) |
| 8 | System administration commands (usually only for root) |
| 9 | Kernel routines [Non standard] |
二 whatis命令
whatis 命令是一个帮助性质的命令,该命令可以用于查询其他命令的用途。实际上显示的是man帮助文档中的NAME部分
$ whatis man
man (1) - an interface to the on-line reference manuals
man (7) - macros to format man pages
第二章 Vim文本编辑器
本章主要参考:《Learning the vi and Vim Editors》,它基本上涵盖了所有使用vi&vim编辑器所能遇到的所有问题。它同时在附录章节中包含快速预览,也包含了详尽到家的正文描述。
文件是Linux的核心,一切皆文件。遵循这个概念,Shell脚本也是文件。对于文件,我们需要文本编辑器帮助我们创建文件,编辑文件,保存文件。Linux里众多的文本编辑器中,vi & vim是最通用的文本编辑器之一。
vi不是Linux独有的文本编辑器,早在Unix时代,vi就从各个文本编辑中脱颖而出,成为最著名的编辑器之一。vim是vi的增强版,继承了vi并改进和增加了一些新的特性。这里先介绍vi是因为,vim仍然是桌面Linux系统的选装软件包,而vi则是基本上所有桌面*nix系统默认安装包。
对于初学者来说vi使用起来会很难用,它不需要鼠标,并且有编辑模式、命令模式及各种命令。但考虑到它的应用场景包括服务器等只有Terminal供用户使用的环境下,再加上在熟练掌握了vi命令之后可以speed up用户的开发,vi仍被认为是well designed。
特别的,对于英文文档,vi使用nix下通用的formatters来获得良好的排版,比如Latex及torff(如果读者阅读了本文并仔细的了解man命令的话,可以查到torff是man默认的排版工具,同时也是nix通用的排版工具)。同时Vim version7也提供拼写检查。
从下文开始我们逐步介绍vi及vim文档编辑器。
一 VI基础
学习一个工具,第一个事情当然是查看帮助文档:man vi

如图,在实际的Linux桌面发行版中,通常会安装简化的vim版本,我们查看vi的指南就会导向vim。
vi +n [file]:打开文件,并显示n行为当前位置。
同时vi有记录上次文件位置的功能,vi + file打开文件上次的位置
-c参数,即vi -c n [file],具备同样的效果。
vi -R [file]:以只读模式打开文件。
vi同时具有实时文件备份功能,可以使用vi -r + [file]来看系统保存的文件(当出现故障未保存文件的时候)。
我们忽略vi相关的环境配置因素,因为普通用户是没有机会遇到vi的环境配置问题的。最多也就是系统崩溃后只能使用vi进行文件编辑的这种情况。这种use case也是我先介绍vi的原因。我们需要了解它,然后才能遇到问题有解决的方法。
笔者使用的是Ubuntu自带的vim来测试vi指令,如果读者遇到了使用vi的时候某些指令跟描述的不一样,是正常现象。要么你用错了,要么是你用的不是vim。
最后,VI或者VIM不适用于编辑中文。
.1 vi指令特性
vi指令的特性:
- vi的指令是大小写敏感的,比如I和i代表的含义是不一样的。
- vi的指令不在屏幕中显示
- 不需要按回车键指令立即生效
.2 打开和关闭文件
vi是一个文本编辑器,但由于Linux认为“everything is a file”这种观念,所以vi可以打开所有Linux下的文件,包括设备文件、目录等等等等。vi会将打开的文件拷贝到一个缓冲区,然后对缓冲区进行操作。只有在用户保存文件的时候,vi才会将缓冲区的内容写回到文件中。
在终端中直接使用vi + 文件名即可打开文件,如果文件没有被创建,则vi会替用户创建一个文件。
$ vi [文件名]
其中,文件名部分其实是可选项,用户可以在稍后的过程中保持所编辑的文件到指定路径,并给予指定的名词。这里的文件名,如果用户自己定义的话,要符合Linux的文件命名规范。作为初学者来说,这里可以先放一放,简单一提就是区分大小写并使用通配符来指代特殊字符。$是*nix系统的提示符,提示用户当前位置及之前输入的命令。
假定我们只输入vi打开一个空白文件,我们会看到如下内容:

这里的~是指代当前位置是空的,没有内容的。同时文本编辑器会告诉你,你现在在使用的其实是vim。
.3 退出和保存命令
按ESC数次(按这么多次是确保自己确实按了ESC),然后按:会进入vi的命令行模式,输入q直接退出之前打开的未编辑过的文档。输入q!则是强制退出当前的文档,不管用户是否编辑过文档。输入w是保存文档。输入wq则是保存编辑,同时退出。使用w!会强制保存当前文件,慎用,可能会造成替换了不应该替换的文件的惨痛后果。
.4 初学者错误
对于新手来说,最需要注意的是文件名字需要输入正确了,并且在一个正确的路径下。提示:使用pwd查看当前路径,使用ls查看当前路径下的文件。
第二个错误是进入一个奇怪的页面。这里先放一段原文,记得也遇到过类似的问题很多次,唔,暂待作者搞清楚vi如何接收中断以及什么是vi支持的中断。
You invoke vi, but you get a colon prompt (indicating that you’re in ex line-editing
mode).
You probably typed an interrupt before vi could draw the screen. Enter vi by typing
vi at the ex prompt (.
第三个问题是,如果用户打开一些特殊权限的文件,会提示无权限或者一些其它类型的错误。什么是权限,这里先放一放,我们新手先确保自己打开的文件是正确的路径下的正确文件。
最后,如果用户在编辑过程中有未保存的内容,使用q退出的话,会提示用户有未保存的内容。这种情况下具体问题,具体分析,一般的话还是建议使用q!强制退出的比较好。还有很多情况会输错命令,这时候多按几次ESC来撤销之前输入的内容。
.5 vi的两种工作模式
vi有两种工作模式,一种是编辑模式,也就是打开文件后,输入i所进入的模式;另外一种是命令行模式,用户进行一些文件编辑的操作,vi默认的是进入命令行模式。
之前也说过按ESC这件小事,它就是vi进入命令行模式的方式。在命令行模式下,输入i则会进入编辑模式。在编辑模式下,终端左下角会有-- INSERT --字样的提示。在命令行模式下,每个字母有了新的含义,或者执行了一些指令。命令行模式类似于终端的命令行,这些命令直接对文件进行操作,而终端的命令是对操作系统进行操作。
.6 没什么用的命令ZZ
它是保存并退出的作用,在命令行模式下输入ZZ,则会保存当前文档的编辑并退出。等同于:wq,所以一般这个命令也没什么人知道。
.7 清空及undo、redo
作为新手,我们经常会不知道我们对打开的文件编辑了什么鬼东西进去,然而强制退出再次打开这个文件又显得很是繁琐。那么:e!就是用来拯救我们的。它会清空所有编辑的内容并打开原始文件。
u as undo 用来撤销方才编辑的内容。U用于恢复光标所在行的改动。
CTRL+R再vim中可以redo。
.8 将文件另存为
另存为是一个很重要的功能,偶尔我们编辑文件的时候,不想保存、但是当前编辑的内容又很重要的情况下,我们可以使用文件另存为这个功能。它其实也就是在w指令后面加上想要另存为的文件名,即:: w [目录名]/[新文件名] 。/是*nix系统里用来区分pathname里的目录和文件。
pathname即路径,是指一个文件所存在的位置,我们可以在终端中使用realpath [文件名]查看该文件的完整路径。
.9 小技巧,多线程
当我们当前只有一个终端的时候,或者为了省点事,我们可以使用CRTL+Z暂停vi并切回到终端界面。这个时候vi会在后台运行,与此同时我们可以使用终端干点别的事,干完之后,使用fg命令,将后台的vi切换到前台,这样我们又可以继续编辑啦。
.10 移动光标所在位置
通常我们会使用上下箭头来移动光标所在的位置,以便编辑文档。同时ENTER代表是光标向下移动一行,backspace代表光标回退一个字。vi还在命令行模式下提供了光标移动的指定,对于用户来说,这些指令还是很方便的。换句话说,大家都会~~
.10.1 基础光标移动命令
- 上下左右:分别对应的是klhj
- 上下滚动一个段落大小的内容:
- 翻页:
- 移到行首:
0 - 移到行末:
$ - 移动到word尾(以空格判定word):
e - 前进一个word:
w - 后退一个word:
b
对于新手来说,假设我们要将光标左移四个字,那么我们需要按四下h。那么我们不仅会问,有没有更便捷的方式呢?数字参数帮忙实现了这个事情,这里需要注意的是数字参数在vi里是放在命令前的。比如左移四个字需要使用4h。
.10.2 按字移动
Word的缩写w一次向右移动一个单词。
Backwards的缩写b一次向左移动一个单词。
同样的2b向左移动两个单词,3w向右移动三个单词。大写的W和B有类似的作用,但稍微有所区别,没必要掌握。
.10.3 移动到指定行
使用Goto的缩写G命令可以移动到指定行,比如移动到第10行就是10G,注意这里是大写。
或者使用小写的g命令,移动到第十行的命令是10gg。
.10.4 Moving Hurry
[CTRL] + f:前进一个页面
[CTRL] + b:后退一个页面
[CTRL] + d:前进半屏
[CTRL] + u:后退半屏
10.5 重置光标行位置
z可以命令屏幕根据光标行所在位置显示光标行上下文。
z + [ENTER]:移动当前光标行屏幕顶端,显示下文
z + .:移动光标行到屏幕中间,显示上下文
z + -:移动光标行到屏幕靠后位置,显示上下文。
10.6 在页面内移动光标的方法
H 光标移动到接近页面首行的位置。
M光标移动到页面中间位置
L光标移动到接近页面末尾的位置。
10.7 按行移动
[ENTER] 与+相同,移动到下一行首
-移动到上一行首。
^移到当前行首
上述三个命令会考虑空格或者有TAB的情况,仅将光标移动到有字符存在的地方。如果行首是空格,即这三条命令移动到第一个非空格字符位置。
10.8 按字块移动
.11 显示行号
显示行号
: set nu
不显示行号
:set nonu
由于一行可能超过当前屏幕的长度,所以在显示上可能会把一行显示成两行给用户看。这种情况下,实际的行号跟用户所看到的行数目是不对其的。
.12 插入操作
.12.1 Append
Appending - a进入编译模式,在光标后面进行插入,这是与i指令的唯一区别。
.12.2 Insert
i 从光标处插入
.12.3 Substitute
Substituting - s 和 S。s用来从当前位置替换一个英文字母,S直接删除整行并开始编辑。
12.4 Open
o 从光标所在行之下插入
O从光标所在行之上插入
.12.5 带参数的插入
50i*+[ESC]插入50个*
25a*-+[ESC]插入25个*-
.13 删除复制粘贴
.13.1 对行的操作
这里介绍的文本编辑指令包括,删除、复制、粘贴分别对应的是Delete - d,Put - p, Yank - y,这些指令针对行进行操作。
dd删除一行yy拷贝一行,yw拷贝一个word,y$拷贝到行尾。4yy意味着拷贝4行。Y等同于yyp将刚才删除或拷贝的内容粘贴到光标行下方。实际上是拷贝vi缓冲区中的内容粘贴并进入编辑模式。带缓冲区的指令有dd、yy、x。对word进行的操作或者D是没有将相关编辑的字符串存储到缓冲区的,所以不支持p。
上述命令不进入编辑模式。
.13.2 Delete
- 删除一个word
dw,删除光标到下一个空格处的文字(空格会被删除)。 d$等同于D,删除光标到行尾
.13.3 Change
Changing - c清除光标到指定位置,并在光标处允许用户进行编辑。
cw删掉光标处向右数一个word,并在光标处开始编辑c2b从光标处向左删除两个word,并开始编辑c$和c0则分别是到行尾和到行首。
cc是删除整行并进入编辑模式。
.13.4 Replace
Replace - r和R命令,如原意,是一个替换指令。比如coding错的时候需要将||替换成&&,输入2r&即可替换代码中的||。
.13.5 对单个英文字母的操作
~用于改变当前光标所在位置的英文字母的大小写,输入~会改变光标当前位置的英文字母的大小写并将光标后移。
Trans - x用于删除一个英文字母。
这两个指令不进入编辑模式
.14 搜索
\用于搜索,\ + [内容]是从前往后搜索。
? + [内容]是从后往前搜索。
按下\或者?会在当前终端的底部显示这个字符串,随后输入内容即查找当前打开文档的包含有[内容]的位置,并将光标显示在该处。
.14.1 下一个
n光标移动到下一个[内容]的位置。
N光标回退到上一个[内容]的位置。
.14.2 行内搜索
f+[x] 找到并移动光标到x处。
t的功能类似于f,基本一致,t的话光标会停留在x字符前。
14.3 组合操作
df + [x] 删除光标到x处的内容。
ct 替换光标到x处的内容。
.15 显示文件信息
[CTRL] + G会在终端的最下方显示文件名、文件行数、当前光标所在位置占居整个文件的百分比。
.16 G移动命令
G移动到行尾
gg移动到行首
[num] + gg或者G移动到[num]指定行,
``回到光标之前的位置(如果没有进行编辑操作的话)。''移动到光标之前的行首。这两个命令可以一直敲,在两个位置来回切换。
.17 拷贝到缓冲区
[1~9]是常用的无名缓冲区
[a-z]是常用的有名字的缓冲区,[A-Z]大写字母用来向指定缓冲区继续append。
缓冲区用来保存用户删除或者拷贝的行,比如:
zdd,删除当前的行并缓冲到z缓冲区。
Zy,拷贝当前的行,并附加到刚才的z缓冲区。
.18 书签
m + X,其中X是任意字符,并区分大小写。即在当前光标处做了一个标签。
' + X,返回光标所在行的第一个字符。
` + X,返回光标处
'' + X 返回上一个书签所在行的的第一个字符
`` + X 返回上一个书签的光标位置。
二 使用vimtags插件与ctags配合浏览源码
在Windows下面,很多人会使用source insight,后来随着visual studio code的开源免费,不管我们在哪儿,我们都开始用visual studio code作为我们的代码浏览工具。
不过在没有visual studio code之前,emacs和vim都有自己的代码浏览方式。其中vim+ctags+cscope是开发人员常用的工具。
对于新手而言,使用vimtags插件加ctags也就够了。而cscope相对会比较复杂,我们可以直接使用find命令来作为代码查找工具。下面介绍vimtags和ctags的联合场景。
- 安装ctags:
sudo apt-get install ctags
-
安装tagslist插件,从官网下载插件:Vim Taglist插件 (已经许久不更新了,最新的版本仍然是46)
-
解压后拷贝的vim的文档和插件目录:
sudo cp doc/taglist.txt /usr/share/vim/vim81/doc/
sudo cp plugin/taglist.vim /usr/share/vim/vim81/plugin/
- 使用 map TlistToggle 指令
在自己的home目录下创建.vimrc,并添加如下内容:
noremap :Tlist
注:笔记本上有很多命令有多功能,找一个上面空映射的,比如F5、F9。否则快捷键映射不到taglist上。
- 创建索引
ctags -R
运行vim的时候,必须在“tags”文件所在的目录下运行。
- have fun
Ctrl+ ] 跳到光标所在变量的定义处
Ctrl+ t 返回
上述两个命令支持嵌套,可以来回跳转。
使用打开索引界面:

第三章 bash/sh与Linux基础命令
跟学习vi一样,作者也买了本书《Learning the bash shell》,初学者推荐经久不衰的《鸟哥私房菜》。同时对于有一定脚本基础的同学,我推荐快速shell脚本入门教程推荐:《Shell 13问》
一 背景知识
最开始了解Linux的时候我们只需要掌握一些命令来帮助我们完成工作,后来随着任务的增多,重复性任务难免会出现,这时我们就会使用脚本记录类似的工作,减少我们的工作量。
1. *Nix软件工具原则
若程序只做一件事,那么无论是设计、编写、调试、维护,以及生成文件都会容易得多。 举例来说,对于用来查找文件中是否有符合样式的grep程序,不应该指望用它来执行算术运算。 这个原则的结果,自然就是会不断产生出更小、更专用于特定功能的程序,就像专业木匠的工具箱里,永远会有一堆专为特定用途所设计的工具。
2. 两个"偷窥"命令
查看终端最近输入的命令:history

查找最近输入的命令:Ctrl^R,会显示如下:
(reverse-i-search)`':
这个时候输入之前输入命令的一部分即可查找到之前输入的命令,当命令较长的时候可以节省时间。
![]()
二 Shell脚本入门及Linux基础命令
1. 什么是脚本
在《抓到一只Linux小白白》我们说到,Shell是操作系统的最外层,是一个用户跟操作系统之间交互的命令解释器。Shell脚本是利用Shell的功能所写的一个程序, 这个程序使用纯文本文件将一些Shell语法和指令写在里面,保存后,使用一个名为Bash的程序来运行这个文件。
通常将Shell脚本命名为.sh,并赋予可执行权限。
查看当前Linux系统使用的Shell类型的方法为echo $SHELL
$ echo $SHELL
/bin/bash
.1.1 脚本注释
# 用于在脚本中添加注释
.1.2 选择脚本执行程序
#! /bin/bash 被称之为Sha-Bang放在脚本的第一行,用来选择执行脚本的程序,本文中我们只使用bash。
.1.3 Linux 文件属性及用户权限
ls -l xxxx用于查看文件的所有者、属性及所在的组
-rw-r--r-- 1 user group 352 Jun 5 12:00 test
其中:
- 用户
user具有文件的读写权限,即r、w - 用户user在
group组中的成员,具有r权限 - 其它成员具有
r权限
文件属性(MODE)分为四组:
- 第一个字符是文件类别,普通文件为
-,目录为d,链接为l - 紧跟的第一组三个字符是文件所有者的权限
- 中间的三个字符是文件左右者所在的组的权限
- 最后的三个字符是其它人的权限。
chmod用来更改文件属性(MODE)。Linux下文件的属性包括读,写,可执行。对应字母为 r、w、x。使用chmod命令时可以直接使用16进制、也可以使用英文字符来对文件进行操作。文件的类别无法更改。
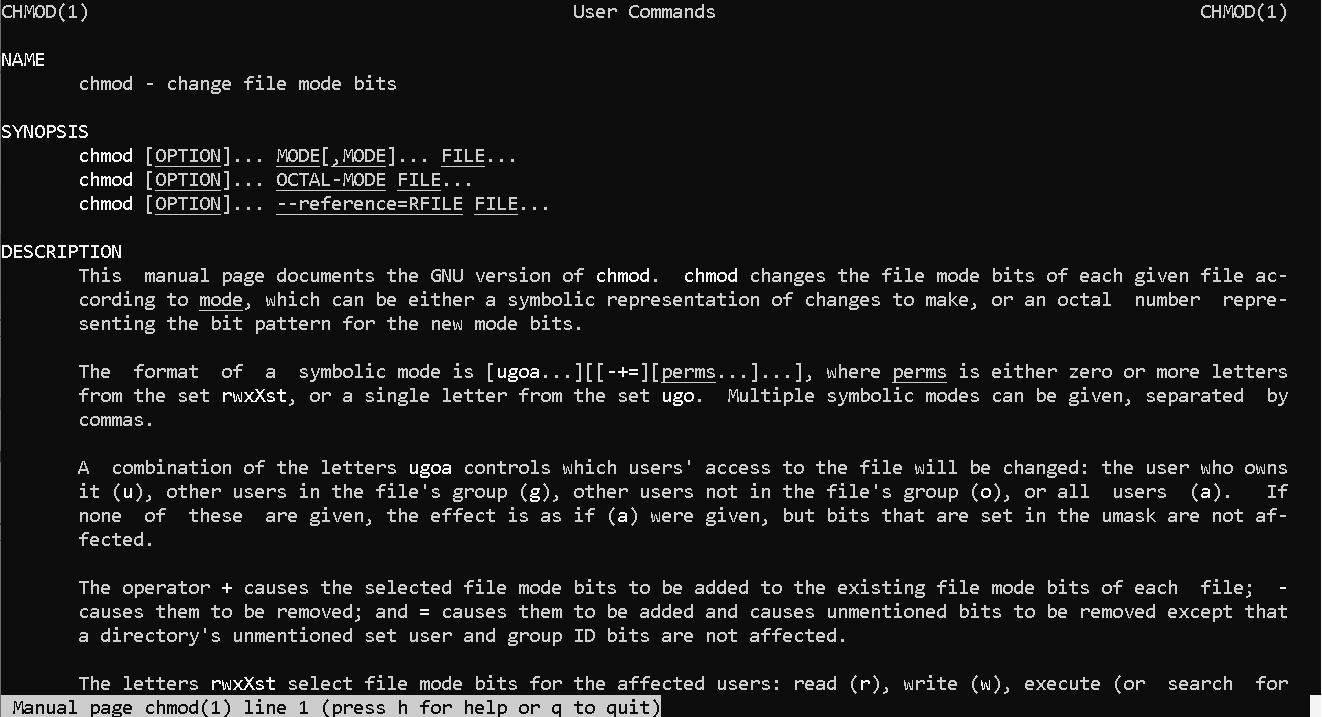
比如:
允许任何人都具有脚本文件的可读和执行权限
$ chmod 555 scriptname
上述命令也可以使用chmod +rx scriptname 来完成,不过使用这个命令,不更改文件的原有属性。这里不改变文件原有的写属性。
当文件具有可执行权限后,可以使用./test来执行这个文件。
.1.4. 输入输出命令
cat命令用于连接文件并打印到标准输出设备上

echo 传递给 echo 的参数被打印到标准输出中。

.1.5 输入输出重定向
大多数 UNIX 系统命令从你的终端接受输入并将所产生的输出发送回到您的终端。一个命令通常从一个叫标准输入的地方读取输入,默认情况下,这恰好是你的终端。同样,一个命令通常将其输出写入到标准输出,默认情况下,这也是你的终端
| 命令 | 解析 |
|---|---|
| command > file | 将输出重定向到 file。 |
| command < file | 将输入重定向到 file。 |
| command >> file | 将输出以追加的方式重定向到 file。 |
| n > file | 将文件描述符为 n 的文件重定向到 file。 |
| n >> file | 将文件描述符为 n 的文件以追加的方式重定向到 file。 |
| n >& m | 将输出文件 m 和 n 合并。 |
| n <& m | 将输入文件 m 和 n 合并。 |
.1.6 进程和管道
进程这里可以理解为每个linux命令在执行过程中的实体。管道可以理解为一种文件。我们可以使用两个进程读写同一个管道文件,从而达到在两个进程中进行数据交互的任务。
cat /etc/passwd | grep root
上面的代码使用了管道命令|。管道命令的作用,是将左侧命令(cat /etc/passwd)的标准输出转换为标准输入,提供给右侧命令(grep root)作为参数。
xargs命令的作用,是将标准输入转为命令行参数。
比如:
$ echo "Hello World" | xargs echo
是将"Hello World"从标准输入转换成echo的参数
由于很多命令不支持管道来传递参数,而日常工作中又有这个必要,所以就有了xargs命令
2. 脚本的变量和参数
本节中大部分表格的来源来自(runoob.com)
.2.1 变量
变量就是可以变化的量,在计算机中用来记录可变化的数据。Shell脚本中将变量所存储的内容,视为字符。
比如:
var=12345
变量限制:
- 命名只能使用英文字母,数字和下划线,首个字符不能以数字开头。
- 中间不能有空格,可以使用下划线 _。
- 不能使用标点符号。
- 不能使用bash里的关键字(可用help命令查看保留关键字)。

.2.2 参数及处理
我们可以在执行 Shell 脚本时,向脚本传递参数:
$ ./test.sh 1 2 3
脚本内获取参数的方法为使用:$N。N 代表一个数字,1 为执行脚本的第一个参数,2 为执行脚本的第二个参数,以此类推。
其它参数处理命令如下:
$0为脚本的文件名$*为传入的整个参数,用一个字符串显示$@为传入的整个参数的数组,每个参数作为数组一个成员
getopts/getopt 自动处理参数,Linux自带的例子doc/util-linux/examples/getopt-parse.bash内容如下:
#!/bin/bash
# A small example script for using the getopt(1) program.
# This script will only work with bash(1).
# A similar script using the tcsh(1) language can be found
# as getopt-parse.tcsh.
# Example input and output (from the bash prompt):
#
# ./getopt-parse.bash -a par1 'another arg' --c-long 'wow!*\?' -cmore -b " very long "
# Option a
# Option c, no argument
# Option c, argument 'more'
# Option b, argument ' very long '
# Remaining arguments:
# --> 'par1'
# --> 'another arg'
# --> 'wow!*\?'
# Note that we use "$@" to let each command-line parameter expand to a
# separate word. The quotes around "$@" are essential!
# We need TEMP as the 'eval set --' would nuke the return value of getopt.
TEMP=$(getopt -o 'ab:c::' --long 'a-long,b-long:,c-long::' -n 'example.bash' -- "$@")
if [ $? -ne 0 ]; then
echo 'Terminating...' >&2
exit 1
fi
# Note the quotes around "$TEMP": they are essential!
eval set -- "$TEMP"
unset TEMP
while true; do
case "$1" in
'-a'|'--a-long')
echo 'Option a'
shift
continue
;;
'-b'|'--b-long')
echo "Option b, argument '$2'"
shift 2
continue
;;
'-c'|'--c-long')
# c has an optional argument. As we are in quoted mode,
# an empty parameter will be generated if its optional
# argument is not found.
case "$2" in
'')
echo 'Option c, no argument'
;;
*)
echo "Option c, argument '$2'"
;;
esac
shift 2
continue
;;
'--')
shift
break
;;
*)
echo 'Internal error!' >&2
exit 1
;;
esac
done
echo 'Remaining arguments:'
for arg; do
echo "--> '$arg'"
done
.2.3 数组
Bash Shell 只支持一维数组(不支持多维数组),初始化时不需要定义数组大小。也可以理解为数组实际上是以空格为分割的字符串。
.2.4 运算符
hell 和其他编程语言一样,支持多种运算符,包括:
- 算数运算符
- 关系运算符
- 布尔运算符
- 字符串运算符
- 文件测试运算符
Shell将所有的数据视为字符串。我们可以使用expr来进行算术运算
下表列出了常用的算术运算符,假定变量 a 为 10,变量 b 为 20:
| 运算符 | 说明 | 举例 |
|---|---|---|
| + | 加法 | expr $a + $b结果为 30。 |
| - | 减法 | expr $a - $b 结果为 -10。 |
| * | 乘法 | expr $a \* $b 结果为 200。 |
| / | 除法 | expr $b / $a 结果为 2。 |
| % | 取余 | expr $b % $a 结果为 0。 |
| = | 赋值 | a=$b 把变量 b 的值赋给 a。 |
| == | 相等 | 用于比较两个数字,相同则返回 true。 [ $a == $b ] 返回 false。 |
| != | 不相等 | 用于比较两个数字,不相同则返回 true。 [ $a != $b ] 返回 true。 |
.2.5 test
test 命令用于检查某个条件是否成立,它可以进行数值、字符和文件三个方面的测试。test命令是一系列命令的集合
- 数值测试
| 参数 | 说明 |
|---|---|
| -eq | 等于则为真 |
| -ne | 不等于则为真 |
| -gt | 大于则为真 |
| -ge | 大于等于则为真 |
| -lt | 小于则为真 |
| -le | 小于等于则为真 |
- 字符串测试
| 参数 | 说明 |
|---|---|
| = | 等于则为真 |
| != | 不相等则为真 |
| -z 字符串 | 字符串的长度为零则为真 |
| -n 字符串 | 字符串的长度不为零则为真 |
- 文件测试
| 参数 | 说明 |
|---|---|
| -e 文件名 | 如果文件存在则为真 |
| -r 文件名 | 如果文件存在且可读则为真 |
| -w 文件名 | 如果文件存在且可写则为真 |
| -x 文件名 | 如果文件存在且可执行则为真 |
| -s 文件名 | 如果文件存在且至少有一个字符则为真 |
| -d 文件名 | 如果文件存在且为目录则为真 |
| -f 文件名 | 如果文件存在且为普通文件则为真 |
| -c 文件名 | 如果文件存在且为字符型特殊文件则为真 |
| -b 文件名 | 如果文件存在且为块特殊文件则为真 |
三 bash脚本调试技术
PS:各个版本的shell的语法在某些细节之处有着明显区别。也就是说,使用bash语法测试通过的脚本是无法确保在其它shell中使用的。
本文来自IBM论坛的《Linux Shell脚本调试技术》一文,目前原文章已经无法找到了。这里根据笔者经验,简单介绍一下常用的、简单的调试技术。
1. tee调试管道
在shell脚本中管道以及输入输出重定向使用得非常多,在管道的作用下,一些命令的执行结果直接成为了下一条命令的输入。如果我们发现由管道连接起来的一批命令的执行结果并非如预期的那样,就需要逐步检查各条命令的执行结果来判断问题出在哪儿,但因为使用了管道,这些中间结果并不会显示在屏幕上,给调试带来了困难,此时我们就可以借助于tee命令了。
tee命令会从标准输入读取数据,将其内容输出到标准输出设备,同时又可将内容保存成文件。例如有如下的脚本片段,其作用是获取本机的ip地址:
ipaddr=`/sbin/ifconfig | grep 'inet addr:' | grep -v '127.0.0.1'
| tee temp.txt | cut -d : -f3 | awk '{print $1}'`
echo $ipaddr
通过temp.txt可以查看中间结果:
$ cat temp.txt
inet addr:192.168.0.1 Bcast:192.168.0.255 Mask:255.255.255.0
在比较简单的脚本中,我们通常会分段执行来诊断错误。但在一些复杂的shell脚本中,特别是继承别人的脚本,这些由管道连接起来的命令可能又依赖于脚本中定义的一些其它变量,这时我们想要在提示符下来分段运行各条命令就会非常麻烦了,简单地在管道之间插入一条tee命令来查看中间结果会更方便一些。
2. 使用命令解析器的参数
命令解析器本身自己也是一个命令,也因此它也可以带参数运行:
-v 一边执行脚本,一边将执行过的脚本命令打印
-n 测试脚本语法错误
-x 提供跟踪执行信息,将执行的每一条命令和结果依次打印出来。
-c "string" 从strings中读取命令
shell的执行选项除了可以在启动shell时指定外,亦可在脚本中用set命令来指定。 "set -参数"表示启用某选项,“set +参数"表示关闭某选项。有时候我们并不需要在启动时用”-x"选项来跟踪所有的命令行,这时我们可以在脚本中使用set命令,如以下脚本片段所示:
set -x #启动"-x"选项
要跟踪的程序段
set +x #关闭"-x"选项
3. shell内置环境变量LINENO
$LINENO代表shell脚本的当前行号,类似于C语言中的内置宏__LINE__
4. shell内置环境变量FUNCNAME
$FUNCNAME函数的名字,类似于C语言中的内置宏__func__,但宏__func__只能代表当前所在的函数名,而$FUNCNAME的功能更强大,它是一个数组变量,其中包含了整个调用链上所有的函数的名字,故变量${FUNCNAME[0]}代表shell脚本当前正在执行的函数的名字,而变量${FUNCNAME[1]}则代表调用函数${FUNCNAME[0]}的函数的名字,余者可以依此类推。
5. shell内置环境变量PS4
$PS4 主提示符变量$PS1和第二级提示符变量$PS2比较常见,但很少有人注意到第四级提示符变量$PS4的作用。我们知道使用-x执行选项将会显示shell脚本中每一条实际执行过的命令,而$PS4的值将被显示在-x选项输出的每一条命令的前面。在Bash Shell中,缺省的$PS4的值是+号。(现在知道为什么使用-x选项时,输出的命令前面有一个+号了吧?)。
利用$PS4这一特性,通过使用一些内置变量来重定义$PS4的值,我们就可以增强-x选项的输出信息。例如先执行:
`export PS4='+{$LINENO:${FUNCNAME[0]}} ',
然后,再使用-x选项来执行脚本,就能在每一条实际执行的命令前面显示其行号以及所属的函数名。
6. trap
trap命令用于捕获指定的信号并执行预定义的命令,其基本的语法是:
trap 'command' signal
Shell脚本在执行时,会产生三个所谓的“伪信号”,(之所以称之为“伪信号”是因为这三个信号是由Shell产生的,而其它的信号是由操作系统产生的),通过使用trap命令捕获这三个“伪信号”并输出相关信息对调试非常有帮助。
| 信号名 | 何时产生 |
|---|---|
| EXIT | 从一个函数中退出或整个脚本执行完毕 |
| ERR | 当一条命令返回非零状态时(代表命令执行不成功) |
| DEBUG | 脚本中每一条命令执行之前 |
通过捕获EXIT信号,我们可以在shell脚本中止执行或从函数中退出时,输出某些想要跟踪的变量的值,并由此来判断脚本的执行状态以及出错原因,其使用方法是:
trap 'command' EXIT 或 trap 'command' 0
通过捕获ERR信号,我们可以方便的追踪执行不成功的命令或函数,并输出相关的调试信息,以下是一个捕获ERR信号的示例程序,其中的$LINENO是一个shell的内置变量,代表shell脚本的当前行号。
$ cat -n exp1.sh
1 ERRTRAP()
2 {
3 echo "[LINE:$1] Error: Command or function exited with status $?"
4 }
5 foo()
6 {
7 return 1;
8 }
9 trap 'ERRTRAP $LINENO' ERR
10 abc
11 foo
以下是一个通过捕获DEBUG信号来跟踪变量的示例程序:
$ cat –n exp2.sh
1 #!/bin/bash
2 trap 'echo “before execute line:$LINENO, a=$a,b=$b,c=$c”' DEBUG
3 a=1
4 if [ "$a" -eq 1 ]
5 then
6 b=2
7 else
8 b=1
9 fi
10 c=3
11 echo "end"
附:练手脚本示例
下面我们通过基本的Linux 命令来解决我们日常中遇到的问题:
1. 通过file命令遍历目录
得到所有目录与对目录下的文件:
#! /bin/sh
[ $# -ne 1 ] &&
{
echo "usage: ./${0##*/} "
exit 0
}
function notcompile ()
{
ifelf=0
#echo $1
filesinsub=$(ls)
#echo $filesinsub
for eachfile in $filesinsub
do
if [ $ifelf -eq 1 ]
then
#echo "elf file exist"
break
fi
elffileexist=$(file $eachfile | grep [Ee][lL][fF])
[ -n "$elffileexist" ] && ##if it is elf file, then run belows
{
#echo $(file $eachfile)
ifelf=1
}
done
if [ $ifelf -eq 0 ] ##有.c文件的但是没有elf文件的
then
#echo $1 ##已经可以输出了
#echo $(ls)
#echo " "
#echo " "
#echo " "
{
ismakefiles=$(ls)
for ismakefile in $ismakefiles
do
if [ "${ismakefile}" = "Makefile" ]
then
echo $1
echo $(ls)
echo " "
echo " "
echo " "
break
fi
done
}
fi
if [ $ifelf -eq 1 ]
then
ifelf=0
fi
}
dirs=$(find $1 | sort)
direxsit=0
for dir in $dirs
do
if [ -d $dir ]
then
{
cd $dir
files=$(ls)
for file in $files
do
if [ $direxsit -eq 1 ]
then
direxsit=0
break
fi
if [ "${file#*.}" = "c" ]
then
#filemeta_c=$(file $file | grep "ASCII C program text")
#if [ -n "$filemeta_c" ] ##c file exist
#then
direxsit=1
notcompile $dir
#break
fi
done
cd - > /dev/null
}
fi
done
2. sed批量修改
修改文件中的某一个字符串(加过滤功能):
#!/bin/sh
#******************************************************************************
# Change "/bin/sh" to "/system/bin/sh"
#
#*****************************************************************************/
if [ $UID != 0 ]
then
echo "FAILED: Must have root access to execute this script"
exit 0
fi
[ $# -ne 1 ] &&
{
echo "usage: sudo ./${0##*/} "
exit 0
}
echo " "
echo "grep -l -R \"/bin/sh\" $1 ..."
echo " "
files=$(grep -l -R "/bin/sh" $1 | sort)
echo "start to manipulate files: "
echo " "
for i in $files
do
{
filemeta=$(file $i | grep [eE][lL][fF])
#echo $filemeta
#echo $i
if [ -z "$filemeta" ]
then
echo $(file $i)
sed -e "s/\/bin\/sh/\/system\/bin\/sh/g" $i > ${i}_bak; mv ${i}_bak $i
chmod 777 $i
objectfile=`grep "/bin/sh" $i`
echo $objectfile
fi
}
done
3. 使用Linux自带随机数生成器
Linux在/proc/sys/kernel/random/uuid下生成随机数,以下是通过这个文件像源码中插入随意行的数据:
#!/bin/sh
######################################################################################
[ $# -ne 2 ] &&
{
echo "usage: sudo ./${0##*/} "
exit 0
}
function random()
{
min=$1;
max=$2-$1;
num=$(cat /proc/sys/kernel/random/uuid| cksum | cut -f1 -d" ");
((retnum=num%max+min));
#进行求余数运算即可
echo $retnum;
#这里通过echo 打印出来值,然后获得函数的,stdout就可以获得值
#还有一种返回,定义全价变量,然后函数改下内容,外面读取
}
#add below to the head of objectfile
sed -i "1i \/\/ ${line4}" $filename
sed -i "1a \/\/ ${line5}" $filename
#add below to the end of objectfile
sed -i '$a /*EOF*/' $filename
#add below to radomline of objectfile
filelines=$(awk 'END{print NR}' $filename)
radomline=$(random20 $filelines)
line1=$(awk '{ if(NR==(num-6)) {print $0} }' num=$randomline englishfile)
objfileradomline=$(random 20 $filelines)
echo "for line 1"
[ -z "$line1" ] ||
{
echo $line1
huanhang1=$(awk '{if(NR==testline) { if ( $NF ~/\\$/ ){ print 1 } }}' testline=${objfileradomline} $filename)
[ "1" = "$huanhang1" ] ||
{
echo "in sed 1"
sed -i "${objfileline}a \/\/ ${line1}" $filename
}
}