插入排序的详细讲解与性能分析
1.算法的性能指标
稳定性:指的是 , 待排序序列中有两个或两个以上相同的关键字时,排序谦和排序后这些关键字的相对位置,如果没有发生变化就是稳定的 , 否则就是不稳定的。举个例子就是,某个序列关键字都是100 , 以100(a)和100(b)加以区分,现用某种算法对该序列进行排序,排序后的结果a和b的相对位置依然保持不变(即a依然在b的后面),那么该算法就是稳定的;反之就是不稳定的。
2.直接排序
先通过一个例子来体会插入排序的执行流程。例如,对原始数组{49 , 38 , 65 , 97 , 76 , 13,27,49}进行插入排序的具体流程。(49加粗,作为稳定性的理解,将以加粗区分)
原始序列:49 38 65 97 76 13 27 49
1)一开始只看49 ,一个数当然是有序的。
49 , 38 , 65 ,97 ,76 , 13 , 27 , 49
2)插入38。38 < 49,所以49向后移动一个位置 , 38插入到49以前的位置,这趟下来结果是:
38 , 49 , 65 ,97 ,76 , 13 , 27 , 49
3) 插入65。 65 > 49 , 所以不需要移动, 65就应该在49之后,这趟排序 的结果就是:
38 , 49 , 65 ,97 ,76 , 13 , 27 , 49
4) 插入97 。 97 > 65 , 所以不需要移动, 这趟排序过后结果就是:
38 , 49 , 65 ,97 ,76 , 13 , 27 , 49
5) 插入76。 76 < 97 , 所以97向后 移动一位;继续比较 , 76 > 65 , 65不需要移动,76应该插入在65之后、97之前,这趟排序过后的结果是:
38 , 49 , 65 ,76 ,97 , 13 , 27 , 49
6) 插入13 。13 < 97 ,97后移;13 < 76 , 76后移 ; 13 < 65 , 65后移;按照这样循环与前一个比较下去,直到13排在最前面。这趟下来结果为:
13 ,38 , 49 , 65 ,76 ,97 , 27 , 49
7) 插入27。还是从后面进行比较,确定27应该插入在13之后,38之前,趟排序过后,结果为:
13 , 27 ,38 , 49 , 65 ,76 ,97 , 49
8) 最后插入49 ,同样与 前一个比较,直到49 = 49 < 65,它的位置确定,直接插入排序全过程完成。之后的结果:
13 , 27 ,38 , 49 ,49, 65 ,76 ,97
算法的思想:
每趟将一个待排序的关键字按照其值的大小插入到已经拍好的部分有序序列的适当位置上,直到所有待排关键字都被插入到 有序序列中为止。代码如下所示:
public static int[] sort(int[] insert) {
int i , j;
int temp;
for(i = 1 ; i < insert.length ; i ++) {
temp = insert[i];
j = i - 1;
while(j >= 0 && temp < insert[j]) {
insert[j + 1] = insert[j];
j --;
}
insert[j + 1] = temp ;
}
return insert;
}
算法性能分析
(1)时间复杂度分析
由插入排序算法代码,可以选取最内层循环中的insert[j + 1] = insert[j];
1)最坏的情况,若整个待排序列是逆序的,则内层循环中 temp < insert[j]的条件始终成立。可得其执行的次数为:n(n - 1)/2,可以看出时间复杂度为O(nn);
2)最好的情况,即整个序列已经是有序的,所以只执行最外层,其时间复杂度为O(n)
3)本算法的平均时间 复杂度为O(nn);
(2)空间复杂度分析
算法所需的辅助空间不需要存储空间不随待排序规模变化而变化,是一个常量,O(1)
折半插入排序
折半插入排序的基本思想和直接插入排序类似,区别在于查找插入位置的方法不同,折半插入排序的采用折半查找法来查找插入位置。
折半查找法的一个基本条件就是序列是有序的,从而直接插入排序的流程可以看出,每次都是在一个有序的序列中插入一个新的关键字。
执行过程如下
举一趟排序为例:
现在的序列是13 ,38 , 49 ,65 ,76 ,97 ,27 ,49
将要插入27,此时序列在数组中的情况为:
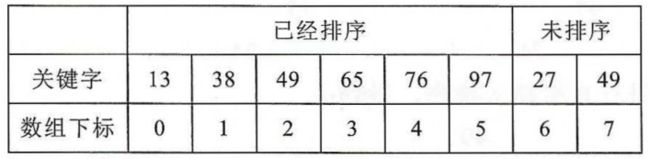
1)low=0,hight=5 , m = [(0 + 5) / 2] = 2,下标为2的关键字是49,27 < 49 , 所以27应该是插入到49的低半区,改变hight = m - 1,low仍然是0。
2)low = 0 , high = 1 , m = [(0 + 1) / 2] = 0,下标为0的关键字是13,27 > 13 , 所以27应该插入到13的高半区,改变low = m + 1 = 1, high 仍然是1;
3)low = 1 , hight = 1 , m[(1 + 1) / 2 ] = 1,下标为1的关键字38,27 < 38 , 所以27应该插入到38的低半区,改变high = m - 1 = 0 , low 仍然是1 , 此时low > high , 折半查找结束,27的插入位置在下标为high的关键字之后,即13之后。
4)依次向后移动关键字97,76,65,49,38,然后将27插入,这趟折半插入结束。执行完这趟以后,结果为:
13 , 27 , 38 , 49 , 65 , 76 , 97 , 49
算法性能分析
(1)时间复杂度分析
折半插入排序适合关键字较多的场景, 与直接差异相比,折半插入排序在查找插入位置上所花的时间大大减少。折半插入排序早关键字移动次数方面和直接插入排序一样 , 所以其时间复杂度和直接插入排序还是一样。
折半插入排序的关键字比较次数和初始序列无关。因为每趟排序折半查找插入位置时,折半次数时一定的,折半一次就要比较一次,所以比较次数是一定的。
由此可知,折半插入排序的时间复杂度最好的情况为O(nlog2(n)) , 最差情况为O(nn) , 平均情况为O(nn);
(2)空间复杂度分析
空间复杂度还是和直接插入算法一样, O(1)