异步爬小说
异步的最好案例应该是爬这种多页面的或者多级的东西,所以直接整小说
直接百度小说
随便点一本小说,然后打开调试
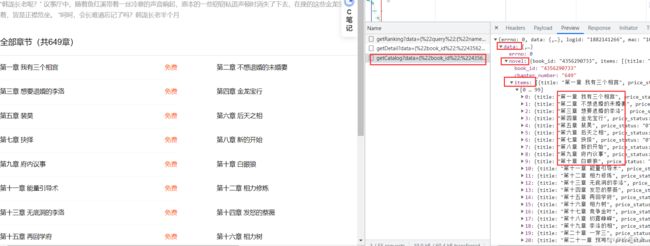
找到加载章节的数据包
然后保存这个包的url地址
点一个章节进去,然后又看一下包
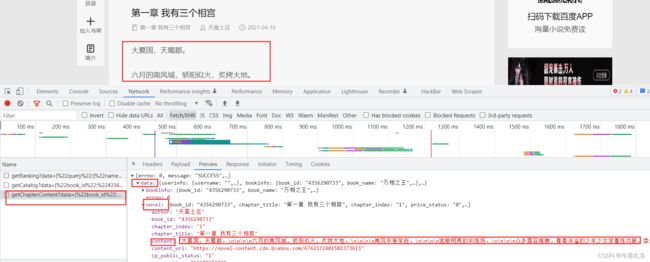
看到了内容,url也复制一下
# https://dushu.baidu.com/api/pc/getCatalog?data={%22book_id%22:%224356290733%22}
# https://dushu.baidu.com/api/pc/getChapterContent?data={%22book_id%22:%224356290733%22,%22cid%22:%224356290733|1569830905%22,%22need_bookinfo%22:1}
发现有%22这玩意,直接去掉

然后对第一个url进行请求
def getCatalog(url): # url 传参
resp = requests.get(url)
print(resp.text) # 同步以获取小说信息
if __name__ == '__main__':
bok_id = "4356290733"
url = 'https://xxxxx.com/api/pc/getCatalog?data={"book_id":"' + bok_id + '"}'
getCatalog(url)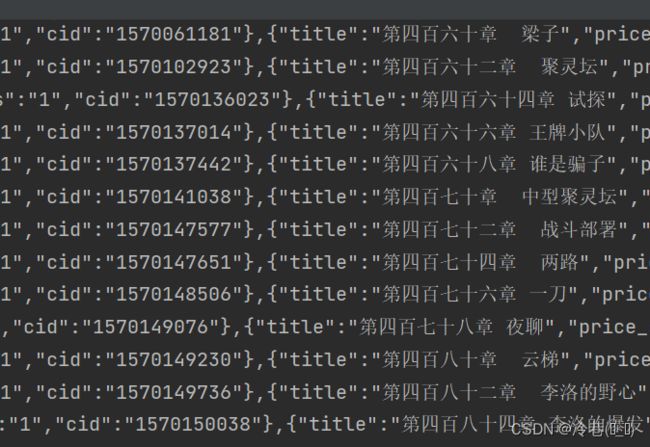
因为是数据包,所以直接用json输出,然后定位到title的位置,以获取title和cid
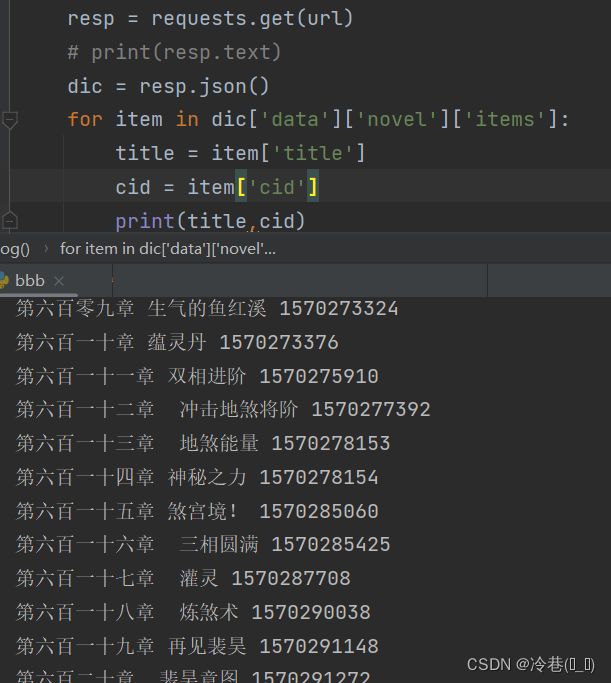
因为每个cid对应每一章节,所以开始上异步
修改代码下
async def aiodownload(cid,bok_id,title):
data = {"book_id":"4356290733","cid":"4356290733|1569830905","need_bookinfo":1}
pass
async def getCatalog(url):
resp = requests.get(url)
# print(resp.text)
dic = resp.json()
tasks = []
for item in dic['data']['novel']['items']:
title = item['title']
cid = item['cid']
# 准备异步任务
tasks.append(aiodownload(cid,bok_id,title))
# print(title,cid)
await asyncio.wait(tasks)
if __name__ == '__main__':
bok_id = "4356290733"
url = 'https://dushu.baidu.com/api/pc/getCatalog?data={"book_id":"' + bok_id + '"}'
asyncio.run(getCatalog(url))仔细看一下data那一行的数据,可以改成
data = {"book_id":bok_id,"cid":f"{bok_id}|{cid}","need_bookinfo":1}对于第一个url就是获取所有章数的,就是如下所示了
async def aiodownload(cid,bok_id,title):
data = {"book_id":bok_id,"cid":bok_id|cid,"need_bookinfo":1}
data = json.dumps(data) # 改为字符串
url = f'https://xxxx.com/api/pc/getChapterContent?data={data}'
async with aiohttp.ClientSession() as sesion:
async with sesion.get(url) as resp:
dic = await resp.json()
async def getCatalog(url):
resp = requests.get(url)
# print(resp.text)
dic = resp.json()
tasks = []
for item in dic['data']['novel']['items']:
title = item['title']
cid = item['cid']
# 准备异步任务
tasks.append(aiodownload(cid,bok_id,title))
# print(title,cid)
await asyncio.wait(tasks)
if __name__ == '__main__':
bok_id = "4356290733"
url = 'https://xxx.xxx.com/api/pc/getCatalog?data={"book_id":"' + bok_id + '"}'
asyncio.run(getCatalog(url))内容就简单了
dic = await resp.json()
async with aiofiles.open(title,mode="w",encoding="utf-8") as f:
await f.write(dic['data']['novel']['content']) # 把小说内容写入全部代码如下
import asyncio, aiohttp, aiofiles
import json
import requests
async def aiodownload(cid, bok_id, title):
data = {"book_id": bok_id, "cid": f"{bok_id}|{cid}", "need_bookinfo": 1}
data = json.dumps(data) # 改为字符串
url = f'https://xxxx.com/api/pc/getChapterContent?data={data}'
async with aiohttp.ClientSession() as sesion:
async with sesion.get(url) as resp:
dic = await resp.json()
async with aiofiles.open(title, mode="w", encoding="utf-8") as f:
await f.write(dic['data']['novel']['content']) # 把小说内容写入
async def getCatalog(url):
resp = requests.get(url)
# print(resp.text)
dic = resp.json()
tasks = []
for item in dic['data']['novel']['items']:
title = item['title']
cid = item['cid']
# 准备异步任务
tasks.append(aiodownload(cid, bok_id, title))
# print(title,cid)
await asyncio.wait(tasks)
if __name__ == '__main__':
bok_id = "4356290733"
url = 'https://xxx.com/api/pc/getCatalog?data={"book_id":"' + bok_id + '"}'
asyncio.run(getCatalog(url))