京东到家机器学习平台建设
目录
前言
机器学习平台总体架构
模型训练平台
特征模型管理平台
在线模型预测服务
算法应用实践
总结和展望
1. 前言
京东到家作为行业领先的即时零售平台,一直把为消费者提供快捷便利高效高质量的即时零售服务作为自己的责任。到家算法团队作为支持京东到家各个业务场景的算法力量,一直以使用算法能力赋能整个到家业务作为团队目标,不断思考怎样提升算法能力和效率,以便更好的服务于到家业务,更好的助力业务发展。
随着京东到家业务的发展和壮大,原有基于线性模型和树模型的基本算法能力已经逐渐无法满足到家业务发展的需求。更多的搜索、推荐以及用户增长等业务场景的算法需求,需要算法团队提供更强大的算法能力,更好的感知用户瞬息万变的意图需求。当前业界先进的算法应用大多都基于深度学习建设完成,深度学习模型能更好地挖掘文本、图片、声音、序列、图结构中的深层次数据信息。依托深度学习模型丰富的模型结构可以更好地抽象提取数据中的高阶特征信息,并且通过结合专家网络等多目标学习任务的方式增强了对用户长短期多样性意图兴趣感知能力,为用户提供更极致服务体验的同时也更有利于业务发展。
所以我们从当前京东到家的业务特点出发,结合算法团队的真实算法迭代需求,融合了原有的算法迭代工具和脚本,进行系统化地沉淀和升级。同时引入了业界先进的kubernetes分布式资源管理框架,以tensorflow2.0作为深度模型训练预测框架。建设完成了从模型离线训练,模型特征管理到在线预测服务的一整套训练预测流程。整个系统采用开闭模式进行设计,将复杂的分布式训练和模型上线过程进行封装,对用户黑盒处理。将算法核心的模型定义和特征生产过程开放出来,实现了处理过程的自定义。总体来说,我们的最终目标就是让算法开发专注于核心工作:特征工程和算法模型。
到家机器学习平台建设以来,承接了京东到家多个业务场景的深度学习模型算法需求,在到家首页feeds推荐、频道feeds推荐以及全局搜索等业务场景均取得了显著的效果,其中首页feeds推荐场景点击率ctr指标累计提升30+%,为到家业务发展提供了高效的算法能力支持。
本文将对到家机器学习平台实现原理和功能进行全面介绍,并分享系统建设过程中遇到的问题和反思。
2. 机器学习平台总体架构

随着以AlphaGo为代表的深度学习应用的成功,第三次人工智能热潮到来,算法在各大互联网公司业务中都发挥着重要的作用。如何提升算法研发的效率,成为各大互联网公司思考的重要工作。像业界比较知名的京东九数算法平台、阿里PAI机器学习平台、百度PaddlePaddle算法平台以及美团Poker算法平台,都通过友好的可视化交互方式提供了大规模数据的深度模型训练任务支持,为整个公司算法发展提供了基础能力。毫无疑问,算法平台可以帮助算法研发将精力聚焦在核心算法工作中去,大幅提升整体算法迭代效率。
到家机器学习平台,参照业界主流机器学习平台的功能划分,将整个平台分为了三个子系统:模型离线训练系统,模型特征配置系统和在线模型预测服务,三个平台各司其职相辅相成,共同组成到家机器学习平台。
我们将模型训练、管理和上线过程进行抽象解释,并将各个功能部分对应到三个系统平台,指出三个系统平台要解决的核心问题:

除了三个平台要解决技术上的核心痛点外,整个到家机器学习平台参考业界先进机器学习平台的设计方案,将模型定义过程和模型训练、上线和部署过程分离开,为用户提供可视化交互方式,并简化了模型训练整体流程,减少上线部署出错概率,从而提高算法迭代质量。模型训练平台基于tensorflow2.0深度模型训练框架,支持图片、序列文本、声音等多模态模型输入,有效增加了算法可利用的输入资源。同时深度模型可以更好的探索迁移学习、负反馈学习、序列化注意力机制、图学习和强化学习等技术领域,让到家算法进入了加速迭代的阶段。
3. 模型训练平台
本章节主要对平台功能进行一个深度剖析。首先对模型实验功能部分进行了详细介绍。其次对平台训练实现原理进行说明,重点阐述了如何通过分布式资源管理和模型分布式训练,解决大模型大数据量级的模型训练问题。最后对未来平台还可以继续优化和改进的部分进行了总结与思考。
3.1 训练平台功能介绍

离线训练平台涵盖了算法平台通用的功能,其中包括:样本实验、模型实验、资源管理、模型debug工具以及实时ab实验工具。这些功能都是在算法开发调试上线过程中,总结发现对算法效率提升最有效的功能部分。
- 样本实验:主要功能是将离线准备好的实验样本,进行业务相关的转换处理,临时储存在训练系统中,工后续的模型实验使用。
- 模型实验:主要是为用户提供一个可视化创建模型训练实验功能入口,将底层创建分布式训练任务的脚本,进行抽象并组件话呈现,简化创建分布式训练实验的成本。
- 资源管理:对使用者来说,可以通过该功能观察系统训练资源的使用情况,并且实时展示全局消耗资源较大的训练任务。
- debug工具:主要是为分析线上模型效果好坏提供系统工具支持,未来会进一步开发并完善。
- 实时ab实验数据:结合系统后端实时流数据,通过flink处理,将系统的实时曝光,实时用户行为和订单数据,进行归因分析,提供实时级别的实验ab数据,有助于发现线上实验问题。
3.2 模型训练过程
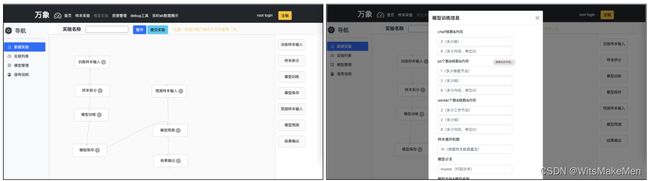
模型训练过程也是整个平台主要的功能部分,其中包括了模型实验创建,实验运行,已有实验的列表,以及训练生成模型的保存管理。
实验创建主要为开发人员提供了七个主要功能组件,其中最主要的有:
- 样本输入(包括训练样本输入和预测样本输入):主要功能是将前面生成的实验样本引入到我们实验中,供模型训练和预测使用。
- 模型训练:将用户定义好的模型文件,通过git方式拉取并引入到模型训练任务中,同时需要配置训练任务中各种类型的训练节点使用资源情况,训练任务生成式基于kubernetes分布式框架。
3.3 实现原理
模型训练平台基于kubernetes作为分布式资源管理框架,使用tensorflow作为机器学习框架。其中kubernetes是Google开源的容器编排引擎,是一个很好的分布式任务生成管理工具,kubernetes支持自动化部署,大规模可伸缩可扩展,应用容器化管理等功能,目前很多云存储云服务都是基于该开源软件设计开发。tensorflow则是目前最受欢迎的机器学习框架之一,他在工业界应用最为广泛,目前各大互联网公司支持最完善机器学习平台都是基于tensorflow提供服务。本节将首先介绍tensorflow分布式训练原理和实现,然后介绍kubernetes如何将分布式训练任务提交并执行。
3.4 tensorflow训练原理
tensorflow作为业界最受欢迎并且应用最为广泛的机器学习框架,具有非常强大的分布式训练和预测支持能力。tensorflow目前主要支持的分布式训练方式有两种Multi-Work训练和Parameter-Server训练。其中Multi-Work分布式训练方式只是将训练数据进行分布式拆分,整个模型结构不会进行分布式拆分,所以Multi-Work主要使用于小模型大数据的训练场景。Parameter-Server分布式训练方式,不仅将模型训练数据进行分布式拆分,同时会将整个模型结构按照模型特点进行分布式拆分,适用于数据量较大同时模型结构也非常大的训练场景。模型训练平台支持两种分布式模型训练方式。
3.4.1 Multi Worker分布式训练原理

对于Multi-Work分布式训练方式来说,所有的节点都是worker节点,没有主从关系,每个worker节点唯一的区别就是输入的训练数据。分布式任务启动之初,就会将整个训练数据按照worker的个数进行拆分,每个worker只会得到其中的一份训练数据,然后并行的执行自己的训练任务,训练任务计算完成各自的梯度后,通过ring-allreduce的方式更新整个集群的参数梯度。训练任务相对比较简单,只需要使用MultiWorkerMirroredStrategy策略,将模型定义和编译定义到strategy策略内部即可,然后将训练任务打包成docker镜像,供后续kubernetes提交训练任务使用。
其中初始化模型阶段,会自动拉取和加载自定义的模型文件,这块代码和整个模型训练过程解耦合,更加方便的为用户提供了可扩展的空间。同时数据加载部分,同样通过接口的方式加载用户自定义的模型数据处理函数,真正模型和数据定义,都是有用户结合平台规范,自定义完成,提供了灵活的模型和数据定义方式。
# multi-work分布式训练代码
def train(self):
strategy = tf.distribute.experimental.MultiWorkerMirroredStrategy()
with strategy.scope():
# 初始化模型
self.model = your_model_here
# 加载训练数据
train = get_csv_dataset(self.train_data_file_list, batch_size=64 * self.num_workers, num_epochs=10)
eval = get_csv_dataset(self.eval_data_file_list, batch_size=64 * self.num_workers)
test = get_csv_dataset(self.test_data_file_list, batch_size=64 * self.num_workers, shuffle=False)
# 模型编译
self.model.compile(
optimizer=self.model_optimizer, # Optimizer
# Loss function to minimize
loss=self.train_loss,
# List of metrics to monitor
metrics=self.train_metrics,
)
callbacks = []
# tensorboard监控
if not self.close_tensorboard:
log_dir= self.model_parent_path + "/logs/%s/%d" % (self.model_name, self.version)
tensorboard_callback = tf.keras.callbacks.TensorBoard(log_dir=log_dir, histogram_freq=1)
callbacks.append(tensorboard_callback)
# 分布式训练容错恢复, 挂载到镜像目录
if self.use_check_point:
checkPointPath = self.model_parent_path + '/tmp/%s/%d' % (self.model_name, self.version)
modelCheckpoint = tf.keras.callbacks.ModelCheckpoint(filepath=checkPointPath)
callbacks.append(modelCheckpoint)
# 模型训练
history = self.model.fit(
train,
epochs=self.epochs,
validation_data=eval,
callbacks=callbacks
)
# 模型验证
results = self.model.evaluate(eval)
# 预测验证集
predictions = self.model.predict(test)
# 保存模型
model_file_dir = self.model_parent_path + '/save_model/keras/%s/%d/%s' % (self.task_name, self.version, self.worker_name)
self.model.save(model_file_dir)
3.4.2 Parameter Server分布式训练原理
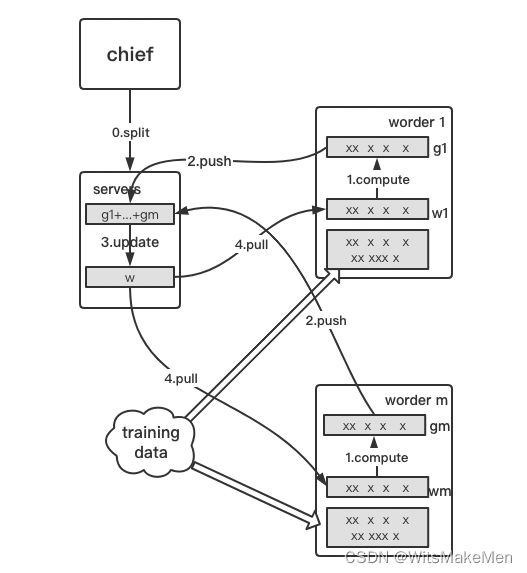
对于Parameter-Server分布式训练方式来说,训练任务按照功能的不同,分为chief节点,parameter-server节点和worker节点。其中chief节点负责拆分训练数据和模型结构,并将模型参数分发到不同的parameter-server和worker节点。parameter-server服务节点负责模型参数梯度的收集和更新。worker节点则负责根据分发的训练数据,计算本节点负责部分参数梯度的计算,将计算完成的梯度推送到parameter-server服务器,然后再拉取最新的参数信息。
整个训练过程需要多种训练任务相互配合,共同完成整个模型的梯度计算和参数更新。相对于Multi-Work训练方式,Parameter-Server分布式训练方式计算效率更高,梯度更新更快,适合于模型结构更大更复杂的训练任务。但是Parameter-Server分布式训练方式也有自己的缺点,那就是训练过程为了加速的需要一般采用异步参数更新方式,这样会牺牲的一部分准确性,导致模型训练效果稍差,但是相对于其对整个模型训练起到的加速作用,一点效果的牺牲还是有必要的。
训练任务根据task_type的不同执行不同的代码逻辑,训练过程定义完成后,同样打包成kubernetes可执行的docker镜像,提供给后续的kubernetes分布式任务执行模块使用。
# parameter-server分布式训练代码
def train(self):
# 定义集群参数
cluster_spec = tf.train.ClusterSpec(self.cluster)
cluster_resolver = tf.distribute.cluster_resolver.SimpleClusterResolver(cluster_spec, task_type=self.task['type'], task_id=self.task['index'])
# chief任务
if cluster_resolver.task_type == 'chief':
variable_partitioner = (tf.distribute.experimental.partitioners.MinSizePartitioner(min_shard_bytes=(256 << 10), max_shards=self.num_ps))
strategy = tf.distribute.experimental.ParameterServerStrategy(cluster_resolver, variable_partitioner=variable_partitioner)
with strategy.scope():
# 初始化模型
self.model = your_model_here
# 模型训练数据
train = tf.keras.utils.experimental.DatasetCreator(dataset_train_fn)
eval = tf.keras.utils.experimental.DatasetCreator(dataset_eval_fn)
test = get_csv_dataset(self.test_data_file_list, features=self.model.feature_names, labels=self.model.label_names, batch_size=64 * self.num_workers, num_epochs=1, features_meta_info=self.model.features_meta_info)
# 模型编译
self.model.compile(
optimizer=self.model_optimizer, # Optimizer
# Loss function to minimize
loss=self.train_loss,
# List of metrics to monitor
metrics=self.train_metrics,
)
callbacks = []
# tensorboard监控
if not self.close_tensorboard:
log_dir = self.model_parent_path + "/logs/%s/%d" % (self.model_name, self.version)
tensorboard_callback = tf.keras.callbacks.TensorBoard(log_dir=log_dir, histogram_freq=1)
callbacks.append(tensorboard_callback)
# 分布式训练容错恢复, 挂载目录
if self.use_check_point:
checkPointPath = self.model_parent_path + '/tmp/%s/%d' % (self.model_name, self.version)
modelCheckpoint = tf.keras.callbacks.ModelCheckpoint(filepath=checkPointPath)
callbacks.append(modelCheckpoint)
# 模型训练
try:
self.model.fit(
train,
batch_size=self.batch_size,
epochs=self.epochs,
steps_per_epoch=self.steps_per_epoch,
validation_data=eval,
validation_steps=self.validation_steps,
callbacks=callbacks
)
except:
traceback.print_exc()
# 模型验证
results = self.model.evaluate(eval, steps=self.eval_test_step)
# 预测验证集
predictions = self.model.predict(test, steps=self.eval_test_step)
# 保存模型
model_file_dir = self.model_parent_path + '/save_model/keras/%s/%d/%s' % (
self.task_name, self.version, self.worker_name)
self.model.save(model_file_dir)
# worker/ps任务
elif cluster_resolver.task_type in ("worker", "ps"):
server = tf.distribute.Server(
cluster_resolver.cluster_spec(),
job_name=cluster_resolver.task_type,
task_index=cluster_resolver.task_id,
protocol="grpc")
server.join()
3.5 kubernetes分布式原理
kubernetes作为Google开源的分布式容器编排引擎,积累了Google自动化容器分布式经验,并且吸收了来自社区的大量想法和经验,目前在业界广受欢迎,并且应用广泛。kubernetes非常适合大规模分布式应用的开发,可以对容器根据资源要求自动进行应用部署,同时在遇到异常后可以快速的自我修复,提供自动服务发现和横向水平扩展,是一款功能非常强大的开源框架,非常适合于到家模型训练平台的开发使用。
3.5.1 基本原理

kubernetes主要分为两部分组成Master和Node。其中Master负责整个集群的正常运行和调度管理,组成部分包括API-Server, Controller,Scheduler和etcd。Node作为实际工作的执行者,组成部分包括kubelet,Storage-Plugin,Network-Plugin和Kuber-Proxy。Master通过自身组件,提供了容器自动化部署,自动化横向扩展以及异常的自动恢复等功能,对使用者提供了kubectl交互工具,对整个集群进行任务创建和管理。同样Node通过自身的组件,负责真正部署启动Master希望得到的容器状态,对外可以提供网络和存储等服务,同时容器内部相互之间的通信,通过Kuber-Proxy实现路由交互。
3.5.2 分布式训练应用
模型训练平台使用了kubernetes生成job任务用来训练模型,其中结合训练任务的不同,结合训练执行image镜像,生成不同类型的yaml任务描述文件,并且提交到kubernetes集群,完成分布式任务的训练。
其中yaml任务描述文件如下,其中一个yaml文件定义了两个组成部分,包括一个Job实例和一个Service实例。Job部分负责了定义Job启动的镜像,以及镜像需要的各种参数定义和环境配置信息,其中env定义的环境配置,是tensorflow分布式训练的关键信息,定义了分布式训练的方式和分布式训练任务其他节点信息,cluster定义了整个集群的服务节点,task标明自己在整个集群中承担的角色。Service定义了当前Job集群内部网络域名信息,提供给cluster定义整个集群交互使用。结合不同类型的训练任务,生成不同类型Job任务的工作,有训练平台的train-job-generator任务生成模块负责。
# multi-worker 一个训练节点的生成yaml文件
apiVersion: batch/v1
kind: Job
metadata:
name: worker-2
spec:
template:
spec:
containers:
- name: worker-2
image: multi_worker_trainer:0.2
args: ["base_models1", "BaseModel"]
env:
- name: TF_CONFIG
value: '{"cluster":{"worker":["service-worker-0:3333","service-worker-1:3333", "service-worker-2:3333"]},"task":{"index":2,"type":"worker"}}'
ports:
- containerPort: 3333
volumeMounts:
- mountPath: /deep_learning_models/datas
name: models
volumes:
- name: models
hostPath:
path: /root/datas
restartPolicy: Never
backoffLimit: 0
---
kind: Service
apiVersion: v1
metadata:
name: service-worker-2
spec:
type: LoadBalancer
selector:
job-name: worker-2
ports:
- port: 3333
到这里整训练任务集群需要的训练镜像和训练任务定义已经全部准备完成,剩下的工作就是怎么将训练任务提交到分布式训练集群。模型训练平台支持多个用户同时训练多个模型任务的同时,还要考虑整个集群的资源合理分配的需要,所以我们提供了统一的实验任务调度experiment-scheduler模块。为每个用户提供固定额度的训练资源,相对公平的保证每个用户的使用权限。提交到experiment-scheduler任务队列中的训练任务,会根据队列目前的资源状况,进行自动化执行,并且将执行的状态和结果实时的反馈给用户,让用户了解到当前实验的阶段和状态。
3.6 总结
模型训练平台目标是封装标准化整个模型训练过程,提供可扩展自定义的模型定义和数据处理,为用户提供灵活又简单的训练平台工具,提升算法迭代效率,减少出错的概率。针对通用的模型结构和数据处理方式,后续也可以组件标准化,为更多有算法需求的非算法同学提供支持。
4. 特征模型管理平台
为了解决多业务多场景多模型的模型管理需求,以及提供复杂而灵活的模型输入算子转换能力,系统设计开发了特征模型管理平台。平台具备模型唯一标识存储能力,可以根据业务线和业务场景区分并生效特定模型。同时平台算子能力,提供了一套统一的算子开发规范,除了提供通用的算法能力外,还支持算子自定义能力。减少了特征模型上线和管理的复杂性,提升了上线服务效率。
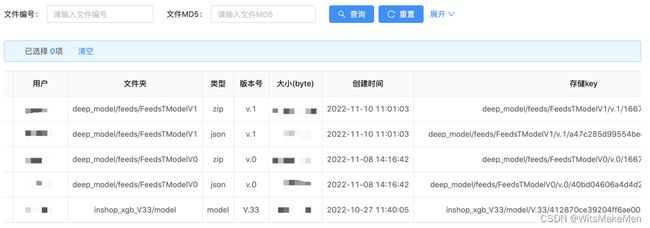
4.1 模型文件管理
模型训练平台生产好的模型最终会产生一个文件集合,里面含有模型文件以及特征的说明信息conf。这两者是缺一不可的。管理好这个生产好的模型文件集合至关重要,模型存放位置,版本信息,模型类型,都需要有一个清晰且规则化的方式存储,这是模型在线服务实现热加载及卸载的基石。因为日常在搜索、推荐各场景的模型数量极多,可视化的知道哪些模型在线使用这样的管理功能也极为重要。
4.2 基础特征管理
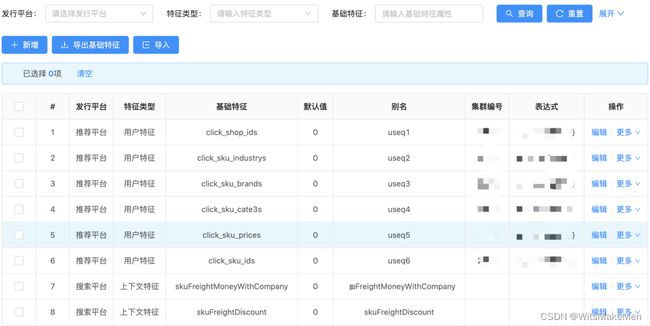
特征信息在京东到家主要含有以下几个大类:用户特征、商品特征、商家特征、门店特征等以及他们组合在一起的交叉特征,再者就是上下文特征的规范化。这部分特征与模型训练平台时候需要的样本特征有一定的关联关系。基础特征管理就是为了能让这部分特征,在线上使用的时候能得到复用。我们知道训练一个模型所需要的特征都是比较多的,但是在多个场景下,模型中所使用的特征存在很多的重合度。如果每个模型都是自己一套样本特征训练及使用,那这样会有很大的资源浪费,并且不能很好的统一特征类别。基础特征管理不光要记录这部分的特征类别,更需要知道这部分特征存放的位置,且能在线上使用的时候找到它。
4.3 模型特征管理
模型特征管理是整个特征模型管理平台的一个核心,因为它决定了模型在线预测能使用的特征都有哪些,以及如何使用这部分特征。很多的实时性上下文特征,或者是基础特征,在不同的模型中使用方式方法是会存在差异的。这部分的差异全靠算子解决,模型特征管理也负责了算子的设计及发布。提供适配性特别强的算子接口,平台化算子能力使算子的扩展及使用更加便利。模型特征管理需要将基础特征与在线模型建立映射关系,同时热发布算子包,以满足不同模型的特征需求。由于模型在线预测的时候,获取特征或者计算特征都有可能在某些时候存在着不可预知的异常现象,所以在映射模型与特征关系的时候,需要为每个特征提供默认的参考值,以应对突发异常情况,保证模型预测的合法性。

4.4 总结
特征模型管理平台是模型训练及模型在线服务系统之间的桥梁,实现了热发布和替换线上模型的能力,减少了人工参与模型发布及修改代码的成本。可视化的管理界面,更能让我们知道各个版本的模型之间的微小差异,加速了我们实验迭代的步伐,提高了人效。
5. 在线模型预测服务
在线模型预测服务的主要目标有两点:第一,对外提供统一的模型预测请求Api接口,通过接口调用的方式实现模型计算逻辑与业务代码逻辑解耦。第二,通过将原本复杂的模型特征数据查询以及模型更新逻辑进行抽象,将所有模型计算相关的功能封装在一个独立服务中,实现了模型功能上的高内聚。
5.1 模型接口的定义
模型预测接口的入参包含了模型信息和item信息。模型信息中的modelType用于区分本次请求中的模型类型,例如xgb、lr,以及深度模型等。在同一种模型类型下为了区分不同的模型实体又引入了模型标签modelTag的概念。至此,通过modelType + modelTag的方式就可以方便地定位到唯一的具体模型。由于模型预测是一种抽象行为,任何需要被预测的信息都可以作为item,item可以是商品也可以是门店,还可以是分类等其他信息。item中包含了几个必须项:item唯一id、item基本参数、item上下文特征。item唯一id做为唯一表示用于运算逻辑多层转换过程中的标记id。item基本参数主要用于拼接查询特征时使用的key,比如说商品id、商家id等。上下文特征是指在业务逻辑执行过程产生的对模型预测有用的特征信息,例如上级来源页面、召回级别等都算作是上下文特征。
如上所述,请求方通过调用api接口时指定modelType + modelTag + Item[]就可以简单地完成一次模型预测请求,具体的细节都交由模型预测服务内部进行处理。
5.2 抽象的特征组装逻辑
在线模型预测逻辑的前提获取到所有模型需要的特征,如何通过一套抽象的逻辑实现所有类型模型的特征组装也就成了重中之重。

如上图所述,整个模型的特征组装逻辑分成了以下几个步骤:
- 获取模型特征配置:通过入参中的modelType和modelTag查询请求目标模型对应的特征列表。
- redis查询条件组合:通过第一步查询出的feature上的配置信息以及item上的基本参数信息进行特征查询key组合,并且最终要按redis集群维度进行聚合去重。
- 并行获取redis查询结果:并行查询redis,得到redis查询出的kv数据。但此时的value还是json结构,json中的具体filed才对应到feature维度。
- redis json特征解析:将第三步得到的json转换成featre维度数据,并且将所属关系挂在到初始的item上。
- 多类型特征整合:将模型feature配置中定义的redis特征、item自带的上下文特征、常量特征进行整合,作为原始特征集合待用。
- 算子加工:部分特征无法直接被模型使用,需要经过算子逻辑加工,比如json信息提取、onehot编码等,加工后的结构会作为新的特征项加到特征集合中。有些深度模型内部也支持自定义算子,但对于简单模型来说在服务中增加算子支持还是必要的,在实际使用中可按需配置。
- 预测得分:将此前获取到的完整特征数据输入到模型,计算获取模型预测得分返回。
5.3 模型服务场景化隔离部署
在线模型预测服务上线后,随着业务场景接入越来越多服务整体的吞吐量也大幅增长,这也导致了一些隐藏的问题被暴露出来。比如在业务调用峰值期间或者压测期间,总会出现个别模型qps极高,甚至极端情况下单个模型的请求量能占据整体模型预测请求量一半以上。这会导致在线模型预测服务的问题排查、限流设置以及服务器资源规划变的非常复杂。针对这些问题,我们提出了场景化隔离方案,如下图:

首先将模型预测调用请求按业务场景进行划分,针对每个场景的模型预测请求提供独立的集群进行响应。每个模型服务集群只加载所属当前场景的模型,并且对外保留独立的别名供调用方请求。各个调用方不用事先模型和别名的对应关系,调用期间可通过配置数据查询到当前请求模型对应的rpc别名,实现了在请求过程中的动态别名路由,而具体配置数据都由模型服务进行维护与同步。通过这样的方式做到了模型请求的场景化隔离,实现了不同场景模型的调用不互相干扰,也方便了工程端的问题排查以及服务器资源规划。
5.4 总结
在线模型预测服务实现了对模型预测行为在功能架构上的高内聚低耦合,为众多业务场景提供了稳定的模型预测能力支持。相比最初的模型接入方式,在线模型预测服务简易的api更便于接入,也为研发同学对更多的业务场景进行算法赋能提供了方便。
6. 算法应用实践
到家算法团队目前主要支持京东到家的算法需求。其中京东到家算法应用场景包括:nlp基础能力建设,搜索召回排序,推荐召回排序,用户增长,门店配送履约预测,销量预测,价格预测管控等算法应用场景。每一个算法应用场景有自己独特的场景特点,所以需要的算法平台支持能力各有差异。对于搜推排序这类在线应用算法场景,平台重点支持了文本序列等多模态特征处理,并且提供了高效的在线预测服务,满足线上实时在线请求需求。对于销量预测这类离线的预测需求,提供了离线预测模块,将预测好的结果输出到hive存储中,提供业务支持。
6.1 首页feeds推荐应用
以首页feeds推荐场景算法支持为例,目前首页feeds推荐场景为用户推荐定位lbs位置下周边店铺的全部商品,需要推荐的门店数量大,同时每个店铺符合要求的商品也比较丰富。怎样从丰富的门店和商品中,为每个用户推荐适合的商品,是该业务场景面临的业务挑战。针对该业务场景的面临的挑战,算法开发同学结合首页feeds场景的业务特点,设计并开发了针对该业务场景的多目标深度专家网络结构。其中对id类输入进行embedding向量化处理,高维稀疏特征转为低维稠密特征。对于dense类稠密特征,进行离散化分桶等特征处理,消除了特征中的噪音,降低了数据的复杂度,增加了模型的鲁棒性。对于行为序列数据,使用transformer将序列和目标值进行encoder和decoder编码处理,挖掘序列中潜在的用户意图兴趣。

其中序列编码部分,使用了经典的self-attention的多头注意力机制:


6.2 图技术探索


7. 总结和展望
随着京东到家即时零售业务的发展和壮大,京东到家算法团队也在不断成长,对算法技术体系和平台工具的打磨也从未停止。在这个过程中,我们将历史经验进行总结和沉淀,并结合业界先进的技术和开源框架,提出并实现了一套适合到家业务的机器学习平台,为算法技术的升级和快速落地提供了系统性的保障。
机器学习平台上线以来,支持了全局搜索商品排序,首页feeds推荐排序,频道feeds推荐排序和店内商品排序等业务场景的深度模型算法应用需求,覆盖了到家90+%分发流量场景和转化流量场景。
目前到家算法团队结合机器学习平台快速迭代算法的能力,在多个业务场景应用图注意力深度模型等业界先进的搜推技术,并取得显著的业务效果。期望在未来的业务发展过程中,机器学习平台能够不断提升算法迭代效率,更好地支持新算法技术落地应用,将算法能力赋能到京东到家业务的每一个角落。