优化回声消除过程:舒适噪声生成算法的应用与原理
在回声消除中,舒适噪声生成(Comfort Noise Generator,CNG)算法是一种常用的技术,它被用来减轻回声消除过程中产生的不适感和声音失真。舒适噪声生成算法通过添加特定的噪声信号来模拟人耳的听觉特性,以改善声音的自然度和舒适度。舒适噪声生成算法的基本原理是通过将噪声信号与回声消除处理后的信号进行混合,使得混合信号在听觉上更加自然和舒适。舒适噪声生成一般需要以下几个步骤,首先是进行背景噪声估计,根据估计的背景噪声功率生成随机噪声,最后对生成的噪声进行加权。我们以WebRTC中的回声消除算法为例,解析舒适噪声算法和其应用。对WebRTC回声消除算法不熟悉的朋友可以参考WebRTC AEC 流程解析。
WebRTC回声消除的整体流程如下所示,近端信号再经过线性NLMS和非线性的NLP处理之后会送给CNG来产生舒适噪声。值得一提的是,有的音频处理流程会把NR放在NLP之后CNG之前。

I. 背景噪声估计
WebRTC回声消除中背景噪声估计在函数ProcessBlock中,首先定义了一些噪声估计常数,如下所示。
const float gPow[2] = {0.9f, 0.1f};
// Noise estimate constants.
const int noiseInitBlocks = 500 * aec->mult;
const float step = 0.1f;
const float ramp = 1.0002f;
const float gInitNoise[2] = {0.999f, 0.001f};其中aec->mult是一个与采样率相关的因子,计算方式如下,我们目前测试音频采样率是16000,那么aec->mult值为2,这也意味着噪声初始化的block数目为1000。
// Sampling frequency multiplier SWB is processed as 160 frame size
if (aec->sampFreq == 32000) {
aec->mult = (short)aec->sampFreq / 16000;
} else {
aec->mult = (short)aec->sampFreq / 8000;
}噪声估计算法如果对降噪比较熟悉的朋友应该知道WebRTC的ANR采用的是分位数噪声估计算法而不是一般常用的MCRA系列的噪声估计算法。在WebRTC AEC中的噪声估计算法类似于后者,是一种递归的噪声最小估计方法。首先在WebRtcAec_InitAec中对噪声功率谱进行初始化
memset(aec->dInitMinPow, 0, sizeof(aec->dInitMinPow));
aec->noisePow = aec->dInitMinPow;
aec->noiseEstCtr = 0;
// Initial comfort noise power
for (i = 0; i < PART_LEN1; i++) {
aec->dMinPow[i] = 1.0e6f;
}接着在ProcessBlock中计算远端和近端平滑后的功率谱
for (i = 0; i < PART_LEN1; i++) {
far_spectrum = (xf_ptr[i] * xf_ptr[i]) +
(xf_ptr[PART_LEN1 + i] * xf_ptr[PART_LEN1 + i]);
aec->xPow[i] =
gPow[0] * aec->xPow[i] + gPow[1] * aec->num_partitions * far_spectrum;
// Calculate absolute spectra
abs_far_spectrum[i] = sqrtf(far_spectrum);
near_spectrum = df[0][i] * df[0][i] + df[1][i] * df[1][i];
aec->dPow[i] = gPow[0] * aec->dPow[i] + gPow[1] * near_spectrum;
// Calculate absolute spectra
abs_near_spectrum[i] = sqrtf(near_spectrum);
}当aec->noiseEstCtr大于50的时候我们才开始进行最小值跟踪来估计近端信号的功率谱
if (aec->noiseEstCtr > 50) {
for (i = 0; i < PART_LEN1; i++) {
if (aec->dPow[i] < aec->dMinPow[i]) {
aec->dMinPow[i] =
(aec->dPow[i] + step * (aec->dMinPow[i] - aec->dPow[i])) * ramp;
} else {
aec->dMinPow[i] *= ramp;
}
}
}当aec->noiseEstCtr小于设定的noiseInitBlocks,我们从零开始平滑增加噪声功率,这是为了避免一个突然的噪声出现。
if (aec->noiseEstCtr < noiseInitBlocks) {
aec->noiseEstCtr++;
for (i = 0; i < PART_LEN1; i++) {
if (aec->dMinPow[i] > aec->dInitMinPow[i]) {
aec->dInitMinPow[i] = gInitNoise[0] * aec->dInitMinPow[i] +
gInitNoise[1] * aec->dMinPow[i];
} else {
aec->dInitMinPow[i] = aec->dMinPow[i];
}
}
aec->noisePow = aec->dInitMinPow;
} else {
aec->noisePow = aec->dMinPow;
}以上就是WebRTC回声消除的噪声估计部分,采用了有别于WebRTC ANR的噪声估计算法,并且在计算过程中引入大量的平滑操作使得估计出来的噪声尽可能的“舒适”。
II. 随机数生成
WebRTC回声消除采用的随机数生成算法是线性加乘同余法。线性加乘同余法的基本原理是利用线性同余方程来生成随机数。具体而言,它使用以下公式生成随机数序列:X(n+1) = (a * X(n) + c) mod m,其中,X(n) 是当前的随机数,X(n+1) 是下一个随机数,a、c 和 m 是预先定义的参数。在WebRTC回声消除中实现线性加乘同余法的函数如下:
- WebRtcSpl_IncreaseSeed,增加随机种子,并返回新值
- WebRtcSpl_RandU,在int16_t 范围内产生一个均匀分布的值
- WebRtcSpl_RandUArray,在 int16_t 范围内生成均匀分布的向量
static uint32_t IncreaseSeed(uint32_t* seed) {
seed[0] = (seed[0] * ((int32_t)69069) + 1) & (kMaxSeedUsed - 1);
return seed[0];
}
int16_t WebRtcSpl_RandU(uint32_t* seed) {
return (int16_t)(IncreaseSeed(seed) >> 16);
}
int16_t WebRtcSpl_RandUArray(int16_t* vector,
int16_t vector_length,
uint32_t* seed) {
int i;
for (i = 0; i < vector_length; i++) {
vector[i] = WebRtcSpl_RandU(seed);
}
return vector_length;
}III. 舒适噪声生成
最后就到了舒适噪声生成的函数ComfortNoise,我们看下重要的函数参数
- efw,这是经过NLMS和NLP之后的输出信号
- noisePow,估计的噪声功率谱
- lambda,非线性抑制系数
static void ComfortNoise(AecCore* aec,
float efw[2][PART_LEN1],
complex_t* comfortNoiseHband,
const float* noisePow,
const float* lambda)首先生成[0,1]直接均匀分布的向量。
WebRtcSpl_RandUArray(randW16, PART_LEN, &aec->seed);
for (i = 0; i < PART_LEN; i++) {
rand[i] = ((float)randW16[i]) / 32768;
接着抑制低频噪声,去除直流分量,即将u[0]之后的都赋值为0,并产生时域的随机噪声信号,可以分为三步
Step 1: 根据随机数组计算随机角频率
Step 2: 根据功率谱开平方得到幅度谱
Step 3: 使用欧拉公式对频域信号进行加噪
u[0][0] = 0;
u[0][1] = 0;
for (i = 1; i < PART_LEN1; i++) {
tmp = pi2 * rand[i - 1];
noise = sqrtf(noisePow[i]);
u[i][0] = noise * cosf(tmp);
u[i][1] = -noise * sinf(tmp);
}
u[PART_LEN][1] = 0最后我们根据传入参数lambda数组选取合适的权重,用于非线性的调整噪声幅值u,基本准则是对应频段非线性抑制越厉害生成的舒适噪声越大,反之越小。
for (i = 0; i < PART_LEN1; i++) {
tmp = sqrtf(WEBRTC_SPL_MAX(1 - lambda[i] * lambda[i], 0));
efw[0][i] += tmp * u[i][0];
efw[1][i] += tmp * u[i][1];
}
IV. 效果
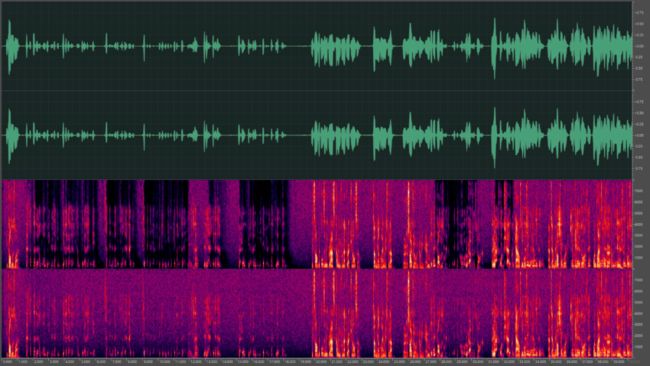
我们最后比较下开启与不开启舒适噪声后的AEC处理效果,如下所示(上图为不开启舒适噪声,下图为开启舒适噪声)。可以明显看到,当不开始舒适噪声时由于远端声音被消除而留下了大片的空白,而开始舒适噪声后,生成的噪声填补了这些空白使得音频听感更连续。
参考文献:
[1]. https://blog.csdn.net/weixin_44856859/article/details/124117845
[2]. https://blog.csdn.net/shichaog/article/details/80210194
[3]. 实时语音处理实践指南