Prometheus 笔记(02)— 监控系统典型架构、采集器(Telegraf_Exporters)、时序数据库(OpenTSDB_InfluxDB_TDEngine)告警引擎、展示 Grafana
监控系统的典型架构:

1. 采集器
采集器负责采集监控数据,有两种典型的部署方式,
- 一种是跟随监控对象部署,比如所有的机器上都部署一个采集器,采集机器的
CPU、内存、硬盘、IO、网络相关的指标; - 另一种是远程探针式,比如选取一个中心机器做探针,同时探测很多个机器的
PING连通性,或者连到很多MySQL实例上去,执行命令采集数据。
业界有多款开源采集器可供选择,下面我们做一个简要点评,便于你做选型。
1.1 Telegraf
Telegraf (https://github.com/influxdata/telegraf) 是 InfluxData 公司的产品,开源协议是 MIT,非常开放,有很多外部贡献者,主要配合 InfluxDB 使用。当然,Telegraf 也可以把监控数据推给 Prometheus、Graphite、Datadog、OpenTSDB 等很多其他存储,但和 InfluxDB 的对接是最丝滑的。
InfluxDB 支持存储字符串,而 Telegraf 采集的很多数据都是字符串类型,但如果把这类数据推给 Prometheus 生态的时序库,比如 VictoriaMetrics、M3DB、Thanos 等,它就会报错。因为这些时序库只能存储数值型时序数据。另外,Telegraf 采集的很多数据在成功和失败的时候会打上不同的标签,比如成功的时候会打上 result=success 标签,失败的时候打上 result=failed 标签。
在 InfluxDB 中这种情况是可以的,但是在 Prometheus 生态里,标签变化就表示不同的指标,这种情况我叫它标签非稳态结构,使用 Prometheus 生态的时序库与 Telegraf 对接时需要把这类标签丢弃掉。
Telegraf 是指标领域的 All-In-One 采集器,支持各种采集插件,只需要使用 Telegraf 这一个采集器,就能解决绝大部分采集需求。
1.2 Exporters
Exporter 是专门用于 Prometheus 生态的组件,Prometheus 生态的采集器比较零散,每个采集目标都有对应的 Exporter 组件,比如 MySQL 有 mysqld_exporter,Redis 有 redis_exporter,交换机有 snmp_exporter,JVM 有 jmx_exporter。
这些 Exporter 的核心逻辑,就是去这些监控对象里采集数据,然后暴露为 Prometheus 协议的监控数据。比如 mysqld_exporter,就是连上 MySQL,执行一些类似于 show global status 、show global variables 、show slave status 这样的命令,拿到输出,再转换为 Prometheus 协议的数据;还有 redis_exporter,它是连上 Redis,执行一些类似于 info 的命令,拿到输出,转换为 Prometheus 协议的数据。
随着 Prometheus 的影响越来越大,很多中间件都内置支持了 Prometheus,直接通过自身的 /metrics 接口暴露监控数据,不用再单独伴生 Exporter,简化了架构。比如 Kubernetes 中的各类组件:kube-apiserver、kube-proxy、kube-scheduler 等等,比如 etcd,还有新版本的 ZooKeeper、 RabbitMQ、HAProxy,都可以直接暴露 Prometheus 协议的监控数据,无需 Exporter。
不管是 Exporter 还是直接内置支持 Prometheus 协议的各类组件,都提供 HTTP 接口(通常是 /metrics )来暴露监控数据,让监控系统来拉,这叫做 PULL 模型。而像 Telegraf 那种则是 PUSH 模型,采集了数据之后调用服务端的接口来推送数据。
1.3 Categraf
Categraf (https://github.com/flashcatcloud/categraf) 的定位类似 Grafana-Agent,支持 metrics、logs、traces 的采集,未来也会支持事件的采集,对于同类监控目标的多个实例的场景,又希望做出 Telegraf 的体验。同时对于所有的采集插件,不但会提供采集能力,也会提供监控大盘、告警规则,让社区开箱即用。
Categraf 偏重 Prometheus 生态,标签是稳态结构,只采集数值型时序数据,通过 Remote Write 方式推送数据给后端存储,所有支持 Remote Write 协议的时序库都可以对接,比如 Prometheus、VictoriaMetrics、M3DB、Thanos 等等。
对于习惯使用 Prometheus 的用户,Categraf 也支持直接读取 prometheus.yml 中的 scrape 配置,对接各类服务发现机制,实现上就是把 Prometheus agent mode 的代码引入进来了。
1.4 Grafana-Agent
Telegraf 以及后面即将讲到的 Grafana-Agent,也可以直接抓取 Prometheus 协议的监控数据,然后统一推给时序库,这种架构比较清晰,总之跟数据采集相关的都由采集器来负责。

采集器采集到数据之后,要推给服务端。通常有两种做法,一个是直接推给时序库,一个是先推给 Kafka,再经由 Kafka 写到时序库。
2. 时序数据库
监控系统的架构中,最核心的就是时序库。老一些的监控系统直接复用关系型数据库,比如 Zabbix 直接使用 MySQL 存储时序数据,MySQL 擅长处理事务场景,没有针对时序场景做优化,容量上有明显的瓶颈。
2.1 OpenTSDB
OpenTSDB 出现得较早,2010 年左右就有了,OpenTSDB 的指标模型有别于老一代监控系统死板的模型设计,它非常灵活,给业界带来了非常好的引导。
OpenTSDB 是基于 HBase 封装的,后来持续发展,也有了基于 Cassandra 封装的版本。你可以看一下它的架构图。
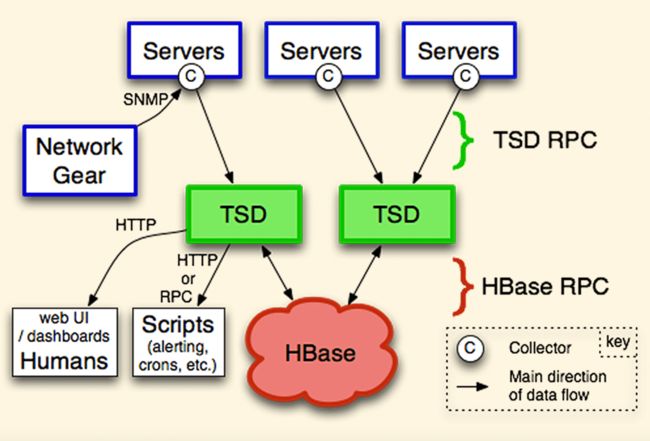
由于底层存储是基于 HBase 的,一般小公司都玩不转,在国内的受众相对较少,当下再选型时序数据库时,就已经很少有人会选择 OpenTSDB 了。
2.2 InfluxDB
InfluxDB 来自 InfluxData,针对时序存储场景专门设计了存储引擎、数据结构、存取接口,国内使用范围比较广泛,而且 InfluxDB 可以和 Grafana、Telegraf 等良好整合,生态是非常完备的。不过 InfluxDB 开源版本是单机的,没有开源集群版本。
2.3 TDEngine
TDEngine 姑且可以看做是国产版 InfluxDB,GitHub 的 Star 数上万,针对物联网设备的场景做了优化,性能很好,也可以和 Grafana、Telegraf 整合,对于偏设备监控的场景,TDEngine 是个不错的选择。
TDEngine 的集群版是开源的,相比 InfluxDB,TDEngine 这点很有吸引力。TDEngine 不止是做时序数据存储,还内置支持了流式计算,可以让用户少部署一些组件。
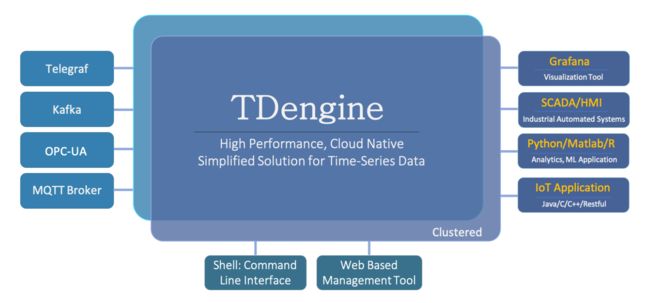
通过 TDEngine 的官网可以得知,TDEngine 是支持 Prometheus 的 remote_read 和 remote_write 接口的。不过不支持 Prometheus 的 Query 类接口,这点需要注意。
注:Thanos、M3DB、VictoriaMetrics 都直接兼容 Prometheus 的 Query 类接口,上层程序可以把这些时序库当做 Prometheus 来使用。
TDEngine 的创始人是陶建辉,有非常高的技术热情,在开源社区非常活跃。
2.4 M3DB
M3DB 是来自 Uber 的时序数据库,M3 声称在 Uber 抗住了 66 亿监控指标,这个量非常庞大。而且 M3DB 是全开源的,包括集群版,不过架构原理比较复杂,CPU 和内存占用较高,在国内没有大规模推广起来。M3DB 的架构代码中包含很多分布式系统设计的知识,是个可以拿来学习的好项目。
2.5 VictoriaMetrics
VictoriaMetrics,简称 VM,架构非常简单清晰,采用 merge read 方式,避免了数据迁移问题,搞一批云上虚拟机,挂上云硬盘,部署 VM 集群,使用单副本,是非常轻量可靠的集群方式。
VM 实现了 Prometheus 的 Query 类接口,即
/api/v1/query/api/v1/query_range/api/v1/label/values
相关的接口,是 Prometheus 一个非常好的 Backend,甚至可以说是 Prometheus 的一个替代品。其实 VM 的初衷就是想要替换掉 Prometheus 的。
2.6 TimescaleDB
TimescaleDB 是 timescale.inc 开发的一款时序数据库,作为一个 PostgreSQL 的扩展提供服务。
它是基于 PostgreSQL 设计而成的,PostgreSQL 社区已经有了现成的高可用特性,包括完善的流复制和只读副本、数据库快照功能、增量备份和任意时间点恢复、wal 支持、快速导入导出工具等。而其他时序库,这些问题都要从头解决。
但是传统数据库是基于 btree 做索引的,数据量到百亿或者千亿行,btree 会大到内存都存不下,产生频繁的磁盘交换,数据库性能会显著下降。另外,时序数据的写入量特别大,PostgreSQL 面对大量的插入,性能也不理想。TimescaleDB 就要解决这些问题。目前 Zabbix 社区在尝试对接到 TimescaleDB,不过国内应用案例还比较少。
3. 告警引擎
告警引擎通常有两种架构,一种是数据触发式,一种是周期轮询式。
数据触发式,是指服务端接收到监控数据之后,除了存储到时序库,还会转发一份数据给告警引擎,告警引擎每收到一条监控数据,就要判断是否关联了告警规则,做告警判断。因为监控数据量比较大,告警规则的量也可能比较大,所以告警引擎是会做分片部署的,即部署多个实例。这样的架构,即时性很好,但是想要做指标关联计算就很麻烦,因为不同的指标哈希后可能会落到不同的告警引擎实例。
周期轮询式,架构简单,通常是一个规则一个协程,按照用户配置的执行频率,周期性查询判断即可,因为是主动查询的,做指标关联计算就会很容易。像 Prometheus、Nightingale、Grafana 等,都是这样的架构。
生成事件之后,通常是交给一个单独的模块来做告警发送,这个模块负责事件聚合、收敛,根据不同的条件发送给不同的接收者和不同的通知媒介。
4. 数据展示
监控数据的可视化也是一个非常通用且重要的需求,业界做得最成功的当数 Grafana。Grafana 采用插件式架构,可以支持不同类型的数据源,图表非常丰富,基本可以看做是开源领域的事实标准。
很多公司的商业化产品中,甚至直接内嵌了 Grafana,可见它是多么流行。当然,Grafana 新版本已经修改了开源协议,使用 AGPLv3,这就意味着如果某公司的产品基于 Grafana 做了二次开发,就必须公开代码,有些厂商想要 Fork Grafana,然后进行闭源商业分发,就行不通了。
来源:https://time.geekbang.org/column/article/622150